Europe PMC — Biomedical Knowledge Graph & Literature Mining
Pricing
from $2.00 / 1,000 paper fetcheds
Europe PMC — Biomedical Knowledge Graph & Literature Mining
Turn a biomedical topic into a knowledge graph and evidence corpus from Europe PMC. Mines genes, diseases, chemicals, organisms and deposited datasets (GEO, ENA, PDB) from full text, builds entity co-occurrence networks, tracks emerging entities, and exports Neo4j/Gephi CSV. No API key.
Pricing
from $2.00 / 1,000 paper fetcheds
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
0
Bookmarked
5
Total users
0
Monthly active users
a month ago
Last modified
Categories
Share
Turn a biomedical topic into an analysis-ready evidence corpus from Europe PMC -- over 40 million articles aggregated from PubMed, PubMed Central (PMC), and preprint servers including bioRxiv and medRxiv. Beyond clean metadata, the actor mines the biology out of the full text: genes, proteins, diseases, chemicals, and organisms (ontology-grounded), plus the deposited dataset accessions (ENA, PDB, UniProt, GEO) behind each paper. Add preprint awareness, full-text access level, and run-level corpus analytics, and you get a structured biomedical dataset -- and a biomedical knowledge graph -- in one run. No API key required.
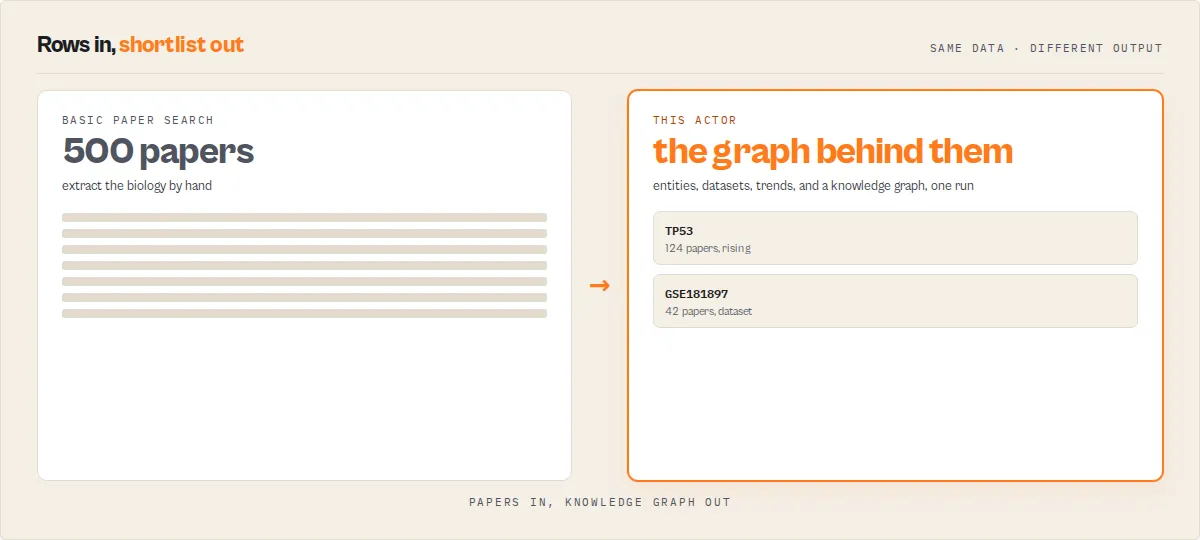
Unlike PubMed wrappers that return papers, this actor returns the biological entities, datasets, trends, and graph relationships behind a biomedical topic.
Common workflows
| Job | Input |
|---|---|
| Build a biomedical knowledge graph | { "query": "CRISPR", "includeNetworks": true } |
| Discover the datasets behind a field | { "query": "single cell sequencing", "entityRollup": true } |
| Detect emerging genes / diseases / targets | { "query": "CAR-T therapy", "entityRollup": true } |
| Full-text entity mining for a RAG corpus | { "query": "Alzheimer's disease", "includeMinedEntities": true, "outputProfile": "compact" } |
| Find preprints before peer review | { "query": "base editing", "queryPreset": "preprints_only" } |
| Pull only open-access full text | { "query": "tumor microenvironment", "queryPreset": "open_full_text" } |
Ready-to-run examples
One-click, pre-configured versions of the common jobs — open one, change the query, run:
- Build a Biomedical Knowledge Graph — co-occurrence graph of genes, diseases and datasets + Neo4j/Gephi CSV.
- Map the Research Landscape — top genes, diseases, datasets, emerging entities and graph in one run.
- Find the Datasets Behind a Field — the GEO/ENA/PDB/UniProt datasets a topic depends on.
- Find Emerging Genes & Targets — entities rising in recent literature vs prior years.
- Extract Biomedical Entities for RAG — compact entity-mined corpus for retrieval pipelines.
- Find Clinical Trial Publications — clinical-trial literature on any condition.
- Find Biomedical Preprints — bioRxiv / medRxiv preprints PubMed does not index.
- Find Systematic Reviews & Review Articles — review and systematic-review literature on a topic.
- Find Open-Access Full-Text Papers — papers with open-access full text, ready to read or mine.
- Find Recent High-Impact Papers — the most-cited papers from the last five years.
See all on the examples page.
What each job returns
| Job | Key input | What you get back |
|---|---|---|
| Build a knowledge graph | includeNetworks | edge records (entity co-occurrence) + nodes.csv / edges.csv |
| Map the research landscape | entityRollup + includeNetworks | entity records + summary with top entities, emerging entities, graph size |
| Dataset discovery | queryPreset: datasets_available | accession entities (GEO/ENA/PDB/UniProt) + the papers that use them |
| Emerging genes & targets | entityRollup | entity records with a recent-vs-prior trend + emergingEntities |
| Entities for RAG | includeMinedEntities + outputProfile: compact | compact per-paper minedEntities (genes, diseases, chemicals, organisms) |
| Clinical trials | queryPreset: clinical_trials | clinical-trial publications with abstracts, MeSH, full-text links |
| Preprints | queryPreset: preprints_only | bioRxiv / medRxiv preprints with isPreprint + access level |
| Systematic reviews | queryPreset: reviews_only | review and systematic-review articles |
| Open-access full text | queryPreset: open_full_text | papers with accessLevel: open-fulltext + fullTextUrl |
| Recent high-impact | queryPreset: recent_high_impact | last-5-years papers sorted by citation count |
What you get from one query
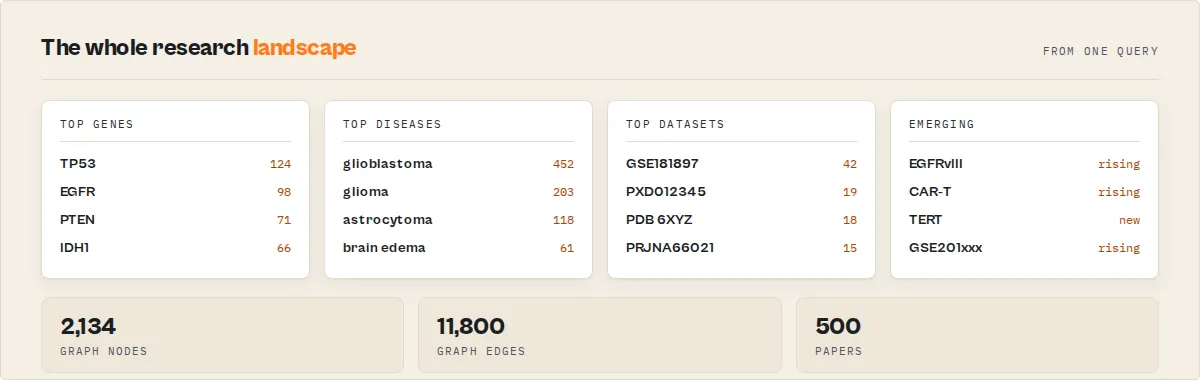
Run { "query": "glioblastoma", "entityRollup": true, "includeNetworks": true } and a single run returns, with no manual extraction, spreadsheet work, or graph-building in between:
- The relevant papers -- with abstracts, MeSH terms, full-text links, preprint status, and access level.
- Every gene, disease, chemical, and organism mined from the full text, each as an aggregate record with paper counts, citations, and a recent-vs-prior trend.
- The public datasets (GEO, ENA, PDB, UniProt accessions) referenced across the corpus -- which dominate the field, what biology co-occurs with each, and when they were active.
- The fastest-rising entities -- e.g. for glioblastoma, genes like EGFRvIII or TP53 climbing in recent literature -- computed deterministically from publication dates.
- A knowledge graph -- typed entity nodes and co-occurrence relationships as dataset records plus
nodes.csv/edges.csv, ready to import into Neo4j, Gephi, Cytoscape, or a GraphRAG / agent-memory pipeline.
The run-level summary record consolidates this into one object -- corpus composition, top entities, top datasets, emerging entities, publication timeline, and knowledge-graph size (networkStats) -- the whole landscape behind your query in a single record.
Example records
That is the structural synthesis a literature review, a drug-discovery target scan, or a bioinformatics knowledge-base build normally does by hand after exporting -- delivered as one structured dataset.
Why Europe PMC?
Most biomedical search tools wrap PubMed, which gives you citations and abstracts. Europe PMC carries the same coverage plus the assets that make structural synthesis possible in one place:
- Text-mined biological entities -- genes, proteins, diseases, chemicals, organisms, ontology-grounded (RXNORM, UniProt, OBO), extracted from full text.
- Deposited data accessions -- the GEO, ENA, PDB, and UniProt datasets behind each paper, for dataset discovery and reproducibility.
- Preprints -- bioRxiv, medRxiv, and Research Square, which PubMed does not index.
- Full-text links and open-access status, grants/funder linkage, and MeSH terms -- all in a single keyless API.
That combination is why this actor can return a knowledge graph and an entity landscape, not just a list of papers -- the raw material for drug discovery, life-sciences competitive scans, bioinformatics pipelines, and scientific dataset discovery.
Why use Europe PMC Literature Search?
- Get the biology, not just the papers -- one run returns the genes, diseases, chemicals, and datasets behind a topic, how they connect (co-occurrence network), and which are rising -- the structural synthesis researchers normally do by hand in Excel after exporting.
- Access 40M+ publications in one search -- Europe PMC unifies PubMed (MED), PMC full-text (PMC), and preprints (PPR) into a single searchable index, eliminating the need to query multiple databases separately.
- No API key or authentication needed -- the Europe PMC REST API is completely free and open, so you can start extracting data immediately without registration or credentials.
- Rich structured metadata -- every result includes PMID, PMCID, DOI, full author lists with affiliations, abstract text, MeSH subject headings, citation counts, publication types, and direct full-text URLs.
- Automated pagination and data transformation -- the actor handles cursor-based pagination, nested API response parsing, and output normalization so you get clean, flat JSON records ready for analysis.
- Schedule recurring literature monitoring -- run the actor daily or weekly with date range filters to automatically track new publications on any biomedical topic.
- Export anywhere -- results are stored in standard Apify datasets that export to JSON, CSV, Excel, Google Sheets, or feed directly into downstream workflows via webhooks and the Apify API.
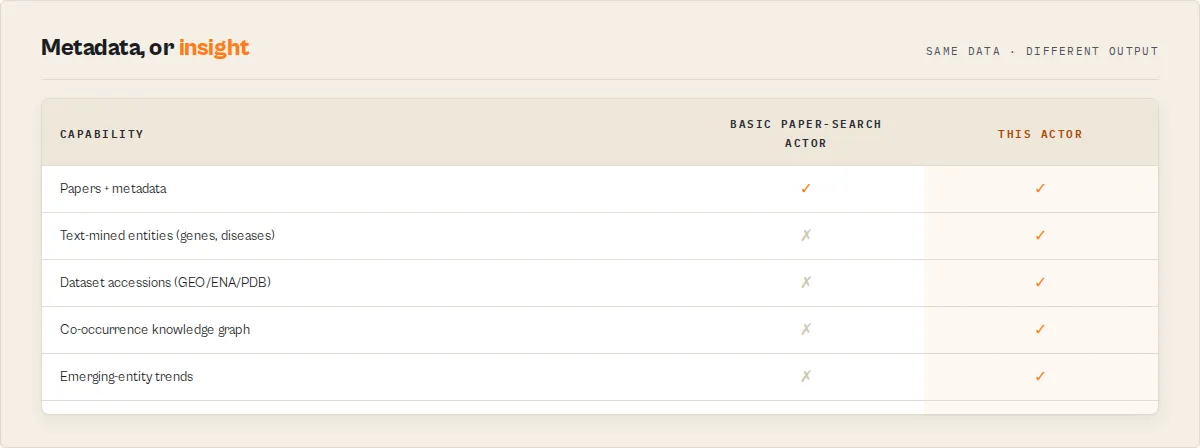
This actor vs the alternatives
| Capability | This actor | Raw Europe PMC API | Generic scraper |
|---|---|---|---|
| Clean, paginated Apify dataset | Yes | Manual | Maybe |
Preprint classification (isPreprint) | Yes | Manual | No |
Full-text access level (accessLevel) | Yes | Manual | No |
| Text-mined biological entities | Yes | Separate API | No |
| Entity-centric rollup records | Yes | No | No |
| Emerging-entity trends (recent vs prior) | Yes | No | No |
| Entity co-occurrence network + graph CSV | Yes | No | No |
| Deposited-data accessions | Yes | Separate API | No |
| Funder linkage | Yes | Manual | No |
| Corpus-composition analytics | Yes | No | No |
| CSV-flat / agent-compact output | Yes | No | No |
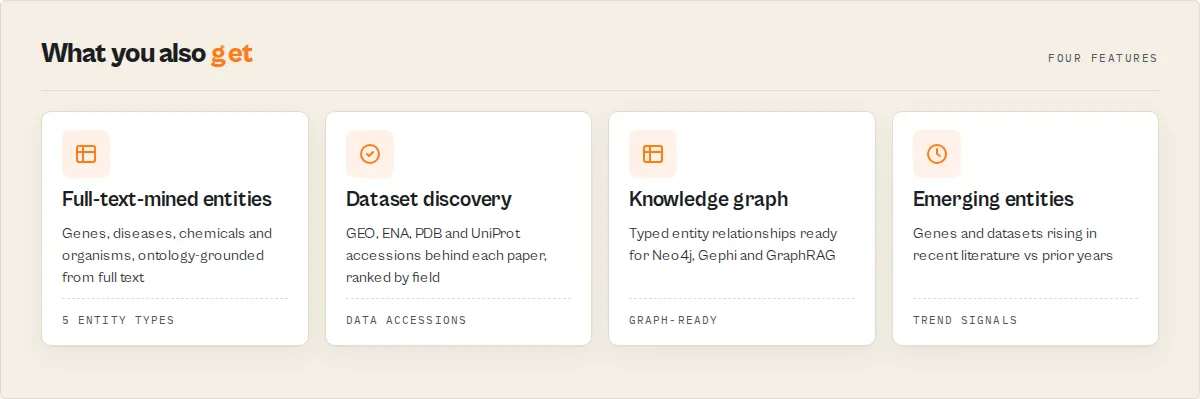
Key features
- Advanced query support -- free-text search plus one-click presets (clinical trials, reviews, preprints, open full text, datasets available) so you don't need to know the query syntax; power users can still use field operators like
TITLE:"term",AUTH:"name", and Boolean AND/OR/NOT - Author filtering -- narrow results to a specific researcher by name using the dedicated author filter field
- Journal filtering -- restrict searches to publications from a specific journal title
- Date range filtering -- specify start and end dates in YYYY-MM-DD format to target a publication window
- Open access filtering -- toggle a single checkbox to return only freely available open access publications
- Source database selection -- choose between All sources, PubMed (MED) for MEDLINE citations, PMC for full-text articles, or Preprints (PPR) for bioRxiv/medRxiv content
- Flexible sort options -- sort results by relevance, citation count (most cited first), or publication date (most recent first)
- Full-text URL extraction -- automatically finds the best available full-text link for each article, preferring HTML over PDF over any other format
- MeSH term extraction -- returns Medical Subject Headings for each article, enabling standardized topic classification and filtering
- Up to 500 results per run -- cursor-based pagination collects large result sets efficiently with page sizes up to 1,000 per API call
How to use Europe PMC Literature Search
Using the Apify Console
- Go to the Europe PMC Literature Search actor page on Apify.
- Click Start to open the input configuration form.
- Enter your search query in the Search Query field (e.g.,
CRISPR gene editing). - Optionally fill in Author Name, Journal Name, Date From, Date To, Open Access Only, and Source Database filters.
- Select your preferred Sort By option -- Relevance, Most Cited, or Most Recent.
- Set the Max Results value (1 to 500, default is 50).
- Click Start to run the actor.
- When the run finishes, open the Dataset tab to view, download, or export results in JSON, CSV, or Excel format.
Using the Apify API or CLI
Input parameters
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
query | String | Yes | -- | Search query. Supports free text and field syntax like TITLE:"term", AUTH:"name", DOI:10.xxx |
queryPreset | String | No | general | Expert query construction without the syntax: clinical_trials, reviews_only, preprints_only, open_full_text, datasets_available, recent_high_impact. Adds the right Europe PMC filters on top of your query |
author | String | No | -- | Filter by author name (e.g., "Smith J") |
journal | String | No | -- | Filter by journal name (e.g., "Nature") |
dateFrom | String | No | -- | Start date in YYYY-MM-DD format |
dateTo | String | No | -- | End date in YYYY-MM-DD format |
openAccessOnly | Boolean | No | false | Only return open access publications |
source | String | No | All | Source database: All, PubMed (MED), PMC Full Text (PMC), or Preprints (PPR) |
sortBy | String | No | RELEVANCE | Sort order: RELEVANCE, CITED desc (most cited), or P_PDATE_D desc (most recent) |
maxResults | Integer | No | 50 | Maximum number of results to return (1--500) |
includeMinedEntities | Boolean | No | false | Fetch text-mined biological entities (genes, proteins, diseases, chemicals, organisms, data accessions) extracted from each paper's full text via the Europe PMC Annotations API. Adds the minedEntities and accessions fields. Makes extra API calls (one batch per ~8 papers). |
entityRollup | Boolean | No | false | Emit per-entity aggregate records (recordType: "entity") across the result set — genes, diseases, chemicals, organisms, and datasets with paper counts, summed citations, and example papers. Enables entity mining automatically. |
includeNetworks | Boolean | No | false | Emit entity co-occurrence edges (recordType: "edge") plus nodes.csv / edges.csv in the key-value store, ready for Neo4j / Gephi / Cytoscape / GraphRAG. Enables entity mining automatically. |
outputProfile | String | No | standard | standard returns the full record; compact drops the authors list, abstract, and per-paper entity arrays (keeping counts) for lean agent/LLM use |
flattenForCsv | Boolean | No | false | Flatten nested arrays/objects to delimited strings (authors, MeSH, funders, mined entities become single columns) for clean CSV / spreadsheet export |
emitSummary | Boolean | No | true | Append a run-level summary record with corpus composition (preprint vs peer-reviewed share, open-access share, top MeSH topics, top funders, top mined entities, most-referenced datasets), also mirrored to the SUMMARY key-value store key |
Example input
Tips for effective queries
- Combine free text with field operators for precision:
TITLE:"deep learning" AND AUTH:"Chen". - Use the dedicated author and journal filter fields instead of embedding them in the query string -- the actor builds the correct Lucene syntax for you.
- Set
dateFromto a recent date and schedule recurring runs to build an automated new-publication alert pipeline. - Filter by source
PMCwhen you need articles with guaranteed full-text availability. - Filter by source
PPRto find preprints from bioRxiv and medRxiv before they are formally published.
Output
The dataset contains paper records (one per publication) and, by default, a single run-level summary record. Each paper record carries full publication metadata plus Europe-PMC-native intelligence: preprint status, full-text access level, funder linkage, and (when entity mining is enabled) the biological entities and data accessions mined from the full text.
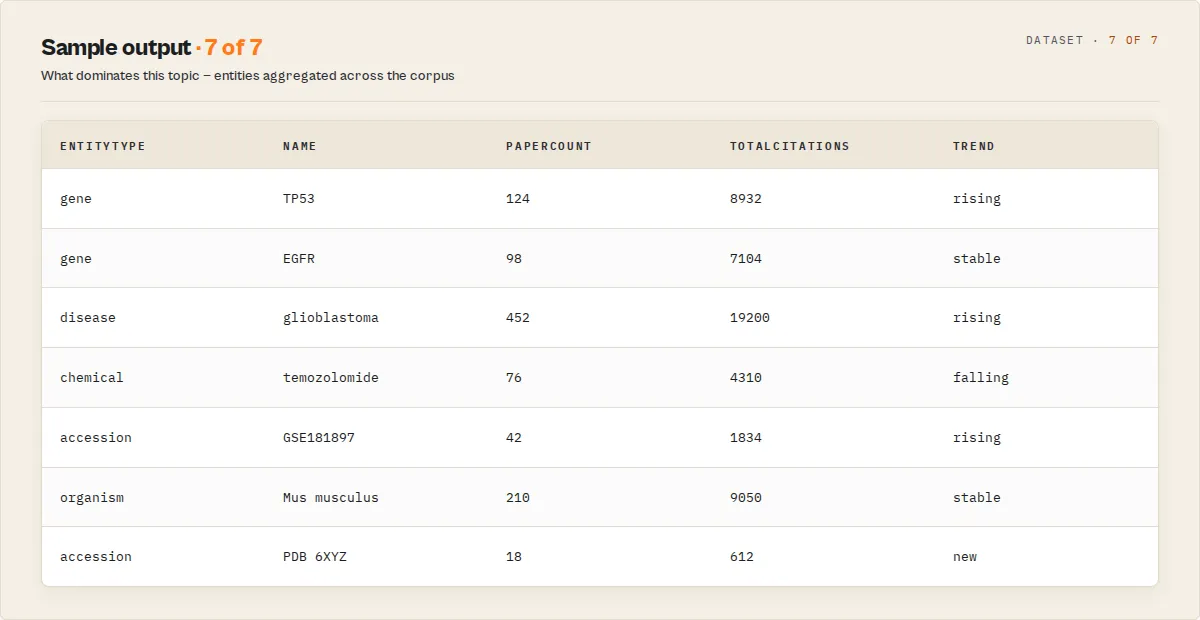
Example output (paper record)
The summary record (emitted once at the end, recordType: "summary") carries corpus composition: totalPapers, preprintCount / peerReviewedCount, openAccessCount, preprintSharePct, openAccessSharePct, yearRange, publicationTimeline (per-year counts), topJournals, topAuthors, topMeshTerms, topFunders, topEntities (genes / diseases / chemicals / organisms), topReferencedDatasets, emergingEntities (rising genes/diseases/chemicals/datasets, recent vs prior window), avgCompletenessScore, and runStats (API request / retry / failure counts + duration).
Entity-centric output (entityRollup)
With entityRollup: true, the dataset also carries recordType: "entity" records — one per gene, disease, chemical, organism, and dataset (accession) found across the result set, with paperCount, totalCitations, firstYear/lastYear, a recent-vs-prior trend, and (when includeNetworks is on) topCoOccurring. Filter entityType == "accession" for the dataset-discovery view ("which datasets dominate this topic, what biology co-occurs with them, and when were they active").
When entityRollup is on and the corpus spans 2+ years, the summary record also carries emergingEntities — genes, diseases, chemicals, and datasets rising in the recent window vs the prior window, computed deterministically from publication dates (no LLM, no cross-run state).
Co-occurrence network (includeNetworks)
With includeNetworks: true, the dataset carries recordType: "edge" records — entity co-occurrence links with a typed relationship, a weight (papers mentioning both), and normalizedWeight (0-100) — and the key-value store gets nodes.csv + edges.csv whose headers follow the neo4j-admin import convention (id:ID / :LABEL / :START_ID / :END_ID / :TYPE), so the graph imports directly into Neo4j, Gephi, Cytoscape, or a GraphRAG pipeline.
This is the build-a-biomedical-knowledge-graph job in one run: point it at a topic, get typed entity nodes (genes, diseases, chemicals, organisms, datasets) and co-occurrence relationships ready for a graph database or agent retrieval memory — no extraction or graph-building step in between.
Output fields reference (paper record)
| Field | Type | Description |
|---|---|---|
recordType | String | paper, summary, or error |
pmid | String | PubMed identifier |
pmcid | String | PubMed Central identifier |
doi | String | Digital Object Identifier |
title | String | Publication title |
authorString | String | Comma-separated author names |
authors | Array | Structured author objects with fullName, firstName, lastName, affiliation |
journalTitle | String | Name of the journal |
journalVolume | String | Journal volume number |
journalIssue | String | Journal issue number |
pageInfo | String | Page range (e.g., "295-302") |
pubYear | String | Publication year |
firstPublicationDate | String | Date of first publication (YYYY-MM-DD) |
abstractText | String | Full abstract text |
citedByCount | Number | Number of citations in Europe PMC |
isOpenAccess | Boolean | Whether the article is open access |
inPMC | Boolean | Whether the article is in PubMed Central |
inEPMC | Boolean | Whether the article is in Europe PMC |
source | String | Source database (MED, PMC, PPR, etc.) |
canonicalId | String | Single best cross-system join key (doi: > pmid: > pmcid: > source:id) |
isPreprint | Boolean | True for preprints (source PPR — bioRxiv / medRxiv / Research Square) |
publicationStatus | String | preprint or peer-reviewed |
isReview | Boolean | Publication type includes "review" (convenience filter, not an evidence grade) |
isClinicalTrial | Boolean | Publication type includes "clinical trial" (convenience filter, not an evidence grade) |
accessLevel | String | open-fulltext, restricted-fulltext, or abstract-only |
pubType | Array | Publication types (e.g., "research-article", "Review") |
meshTerms | Array | Medical Subject Heading terms |
grants | Array | Funder / grant linkage: { agency, grantId } |
funders | Array | Distinct funding agency names |
accessions | Array | Deposited dataset / sequence accessions mined from the paper (ENA, PDB, UniProt, GEO): { name, count, uri }. Requires includeMinedEntities |
accessionCount | Number | Count of distinct data accessions |
minedEntities | Object | Text-mined biological entities bucketed by type (genesProteins, diseases, chemicals, organisms, cellTypes, goTerms). null unless includeMinedEntities is on |
minedEntityCount | Number | Total distinct mined entities (including accessions) |
completeness | Object | Metadata-completeness signal: score (0-1, fraction of 7 key fields present) plus hasDoi, hasAbstract, hasMeshTerms, hasAffiliations, hasFullText, hasFunding, hasDataAccessions. Filter reliable records by completeness.score |
fullTextUrl | String | Best available full-text URL (HTML preferred over PDF) |
europePmcUrl | String | Direct link to the article on Europe PMC |
summary | String | Plain-English one-line summary of the record |
extractedAt | String | ISO 8601 timestamp of when the data was extracted |
Use cases
- Systematic literature reviews -- collect all publications matching specific criteria for structured evidence synthesis in medical or scientific research
- Research trend analysis -- track publication volume, citation patterns, and emerging topics across biomedical fields over time
- Competitor intelligence for pharma -- monitor publications from competing research groups or pharmaceutical companies working on similar drug targets
- Grant application preparation -- quickly survey existing literature on a topic to establish research gaps and justify funding proposals
- Clinical evidence gathering -- find clinical trial publications and reviews relevant to specific treatments, diseases, or medical devices
- Preprint monitoring -- filter by source PPR to track bioRxiv and medRxiv preprints before they appear in peer-reviewed journals
- Author publication tracking -- follow a specific researcher's output by combining author name filters with date ranges
- Knowledge graph construction -- extract structured metadata including MeSH terms, authors, and citations to build biomedical knowledge graphs and network analyses
- Open access content mining -- filter for open access articles to build text mining datasets for NLP, machine learning, or AI training
- Journal benchmarking -- compare publication volume and citation impact across journals in a specific research area
API & integrations
Python
JavaScript
cURL
Platform integrations
- Apify Schedules -- run daily or weekly to monitor new publications on a topic
- Webhooks -- trigger downstream processing when a run completes (e.g., email alerts, Slack notifications)
- Zapier / Make -- connect Apify to thousands of apps for automated literature monitoring workflows
- Google Sheets -- export results directly to a spreadsheet for collaborative review
- Amazon S3 / Google Cloud Storage -- push datasets to cloud storage for archival or further processing
Use in Dify
Drop this actor into Dify workflows via the Apify plugin's Run Actor node. Each paper returns classified, structured JSON — publicationStatus (preprint / peer-reviewed), accessLevel (open-fulltext / restricted-fulltext / abstract-only), and the text-mined biology — so a downstream if/else node branches on stable enums instead of parsing prose. A generic scraper pointed at a publisher page returns rendered HTML; this returns the classification and the entities.
- Actor ID:
ryanclinton/europe-pmc-search - Sample input (build a full-text-aware evidence pipeline with entity mining):
- Branching example — a Dify if/else node routes each paper record by the fields above:
accessLevel == "open-fulltext"→ fetch the body viafullTextUrland feed a RAG index.isPreprint == true→ flag as not-yet-peer-reviewed before citing.accessionCount > 0→ route to a data-reuse / reproducibility step using theaccessionslist.completeness.score >= 0.7→ accept; below → send to a manual-review branch.recordType == "entity"→ route gene / disease / dataset aggregates to a knowledge-graph or trend node;recordType == "edge"→ a network node.recordType == "summary"→ branch the run-level corpus record (preprint share, top entities, top funders) to a reporting node.
- Presets and modes Dify can leverage:
queryPreset(e.g.datasets_available,clinical_trials) constructs the right query without Lucene syntax;includeMinedEntitiesturns on the per-paperminedEntitiesblock (genes, diseases, chemicals, organisms) and theaccessionslist;entityRollupadds entity-aggregate records andincludeNetworksadds co-occurrence edges + graph CSVs;outputProfile: "compact"returns a lean record for token-bounded agent steps;canonicalIdis the stable key for joining or deduping across nodes. The mined-entity arrays are usable verbatim by a downstream node — no LLM rewriting needed.
How it works
- Parse input -- reads the search query and optional filters (author, journal, dates, open access, source database)
- Build Lucene query -- constructs a Europe PMC query string combining free text with field-specific operators like
AUTH:"name",JOURNAL:"title",FIRST_PDATE:[from TO to],OPEN_ACCESS:y, andSRC:source - Query the API -- sends the request to the Europe PMC REST API at
https://www.ebi.ac.uk/europepmc/webservices/rest/searchwithresultType=corefor full metadata - Paginate with cursors -- uses cursor-based pagination (
cursorMark) with page sizes up to 1,000 to efficiently collect large result sets - Transform results -- normalizes nested API responses into flat, consistent output records with 23 structured fields
- Extract full-text URLs -- finds the best available full-text link for each article, preferring HTML over PDF over any other format
- Push to dataset -- stores each batch of transformed records in the Apify dataset as they are collected
Performance & cost
| Scenario | Results | Approx. Duration | Apify Platform Cost |
|---|---|---|---|
| Quick search | 50 | 5--10 seconds | < $0.01 |
| Medium batch | 200 | 15--30 seconds | < $0.01 |
| Maximum batch | 500 | 30--60 seconds | ~$0.01 |
| Scheduled daily run | 50/day | 5--10 seconds/run | < $0.30/month |
- Memory requirement: 256 MB (minimum Apify tier)
- The Europe PMC API is completely free with no usage limits for reasonable query volumes
- Cost is driven entirely by Apify compute time, which is minimal for this API-only actor
- No browser rendering or proxy infrastructure required
Limitations
- Maximum 500 results per run -- the actor caps output at 500 records to keep runs fast and manageable. For larger datasets, run multiple queries with narrower filters.
- Abstract only for paywalled articles -- the actor provides full metadata and abstracts for all articles, but full-text content behind paywalls requires separate institutional access.
- Citation counts may lag -- the
citedByCountfield reflects Europe PMC's citation index, which may not be as current as Google Scholar or other citation databases. - Preprint metadata may be sparse -- preprints from bioRxiv and medRxiv may lack MeSH terms, full author affiliations, or other metadata that is added during peer review and indexing.
- API rate limits -- while the Europe PMC API has no formal authentication requirement, extremely high-frequency requests may be throttled. The actor uses reasonable page sizes and sequential requests to avoid this.
- Date filtering uses first publication date -- the
FIRST_PDATEfield may differ from the journal publication date for articles that appeared as early releases or preprints first. - No full-text download -- the actor extracts metadata and links but does not download or parse the full text of articles.
Responsible use
- Respect publisher terms -- while Europe PMC metadata is freely available, full-text articles may be subject to publisher copyright. Always check the license before redistributing or text mining full-text content.
- Cite your sources -- if you use data from this actor in research publications or reports, cite the original articles and acknowledge Europe PMC as the data source.
- Use reasonable query volumes -- avoid scheduling unnecessarily frequent runs or requesting maximum results when fewer would suffice. The Europe PMC API is a shared public resource.
- Comply with institutional policies -- if you are accessing this actor through an institutional Apify account, ensure your usage complies with your organization's data handling and research ethics policies.
- Do not use for spam or harassment -- do not use extracted author contact information (affiliations) for unsolicited bulk communications.
FAQ
Q: What databases does Europe PMC cover? A: Europe PMC indexes over 40 million records from three primary sources: PubMed (MED) for MEDLINE biomedical citations, PubMed Central (PMC) for full-text open access articles, and preprint servers (PPR) including bioRxiv and medRxiv. It also includes content from patents, agricultural research, and European life science repositories.
Q: Do I need an API key to use this actor? A: No. The Europe PMC REST API is completely free and open. This actor requires no API keys, tokens, or registration to run.
Q: How is this different from the PubMed Research Search actor? A: Europe PMC includes everything in PubMed plus additional content from PubMed Central full-text articles, preprints from bioRxiv/medRxiv, and European life science sources. It also provides MeSH terms, richer author metadata with affiliations, and direct full-text URLs in a single query.
Q: Can I get the full text of articles?
A: The actor provides a fullTextUrl field with the best available link to the full text (HTML or PDF) for open access articles. For paywalled articles, you receive the abstract and all metadata but need institutional access for full text.
Q: What query syntax is supported?
A: The actor supports Europe PMC's Lucene-based query syntax. You can use free text, field-specific operators (TITLE:"term", AUTH:"name", DOI:10.xxx, ABSTRACT:"keyword"), Boolean operators (AND, OR, NOT), and wildcards (*). The dedicated filter fields for author, journal, date, and source are combined automatically.
Q: Can I search for preprints specifically?
A: Yes. Set the Source Database parameter to PPR (Preprints) to restrict results to bioRxiv, medRxiv, and other preprint servers indexed by Europe PMC.
Q: How does pagination work?
A: The actor uses cursor-based pagination with the Europe PMC API's cursorMark parameter. Each API call retrieves up to 1,000 results, and the actor continues fetching pages until it reaches your maxResults limit or exhausts available results.
Q: Can I schedule automatic searches for new publications?
A: Yes. Set up an Apify schedule to run the actor daily or weekly. Use the dateFrom parameter set to a recent date to capture only newly published articles. Combine with webhooks to send email or Slack alerts when new papers match your criteria.
Q: What are MeSH terms and why are they useful? A: MeSH (Medical Subject Headings) is a standardized vocabulary maintained by the National Library of Medicine. MeSH terms enable consistent topic classification across articles, making them valuable for systematic reviews, meta-analyses, and building structured topic taxonomies.
Q: How current is the data? A: Europe PMC updates its index daily. PubMed records typically appear within 1--2 days of being indexed by the National Library of Medicine. Preprints are indexed shortly after they are posted to bioRxiv or medRxiv.
Q: Can I sort results by citation count?
A: Yes. Set the Sort By parameter to CITED desc to return the most highly cited articles first. This is useful for identifying seminal papers and high-impact research on any topic.
Q: What happens if my query returns more than 500 results?
A: The actor returns up to 500 results (or your configured maxResults limit, whichever is lower). If the total hit count exceeds this, you can narrow your search with additional filters or run multiple queries with non-overlapping date ranges to cover the full result set.
Related actors
| Actor | Description |
|---|---|
| PubMed Biomedical Literature Search | Search PubMed for MEDLINE-indexed biomedical citations with abstracts and metadata |
| Semantic Scholar Paper Search | Search Semantic Scholar for academic papers with AI-generated TLDRs and citation data |
| OpenAlex Research Paper Search | Search OpenAlex for open scholarly metadata across all academic disciplines |
| Crossref Academic Paper Search | Search Crossref for DOI-registered publications with reference metadata |
| ORCID Researcher Search | Look up researchers by ORCID ID to find their publication history and affiliations |
| ArXiv Preprint Paper Search | Search ArXiv for preprints in physics, mathematics, computer science, and related fields |