Reddit Scraper - Posts, Comments, Communities & Users
Pricing
from $2.30 / 1,000 results
Reddit Scraper - Posts, Comments, Communities & Users
Scrape Reddit posts, comments, subreddits, communities, and user profiles without login or API keys. Get titles, scores, upvotes, awards, flair, media, and full metadata as structured JSON. Search by keyword or subreddit, filter by date and NSFW, and export to JSON, CSV, or Excel.
Pricing
from $2.30 / 1,000 results
Rating
5.0
(1)
Developer
SilentFlow
Maintained by CommunityActor stats
1
Bookmarked
13
Total users
5
Monthly active users
12 days ago
Last modified
Categories
Share
Reddit Scraper
Turn any subreddit, thread, community, or user profile into clean structured data. Posts, comments, communities, and users in a single run, in seconds not hours.
How it works
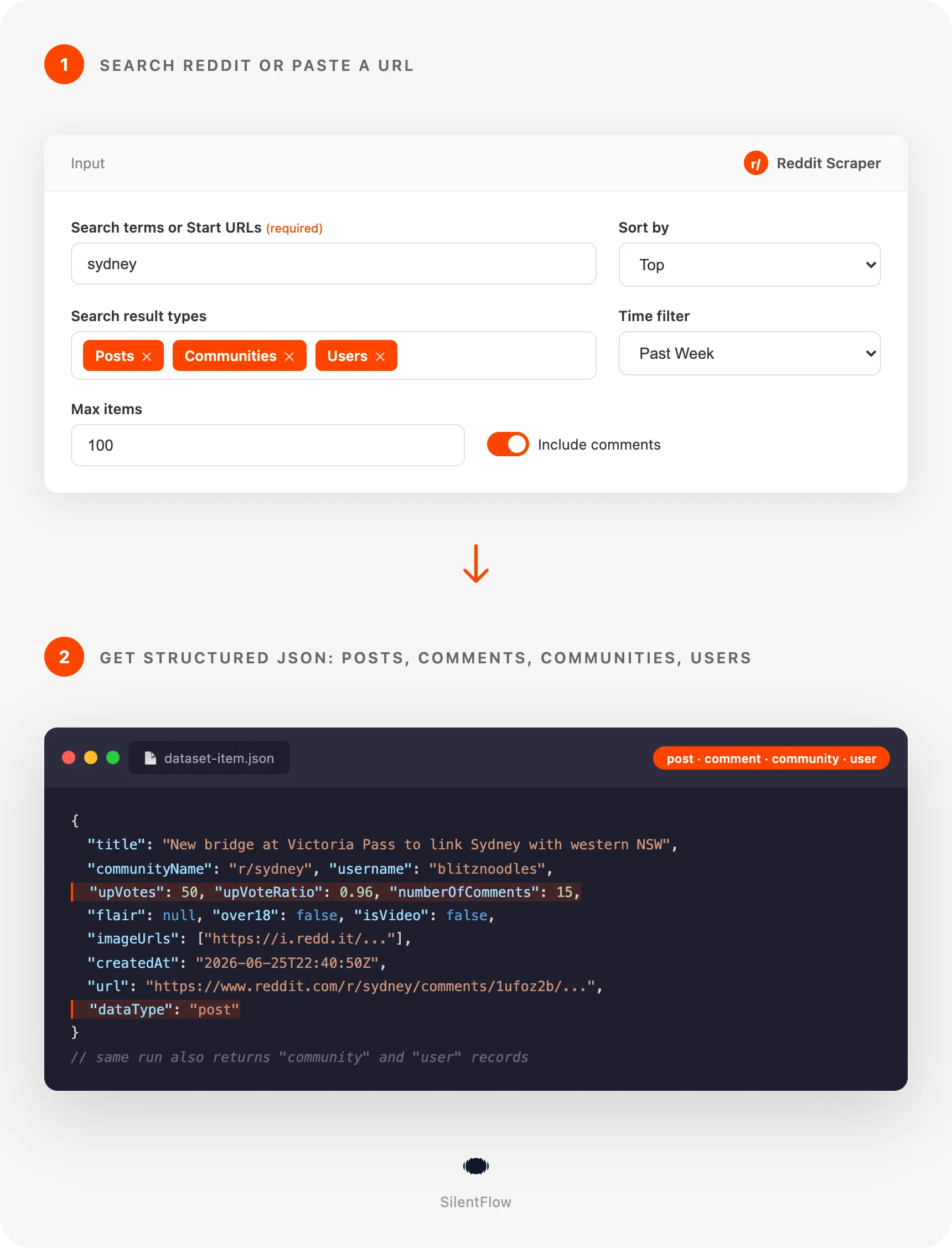
- Search or paste a URL. Type keywords (optionally scoped to one subreddit) or drop in subreddit, post, or user links, and choose what to pull: posts, comments, communities, users.
- Get structured JSON. Every score, upvote ratio, comment count, flair, media link, karma, and timestamp, ready for your database, spreadsheet, or model.
✨ Why teams choose this over other Reddit scrapers
Stuck with a scraper that only pulls posts and comments? Running one that fails on every third request? Still copy-pasting threads into a spreadsheet by hand?
- 📦 Four data types in one actor, not two. Posts, comments, communities, and users. Most Reddit scrapers stop at posts and comments. Discover and qualify subreddits, then profile the people behind the threads, without switching tools.
- 🔓 No login, no API keys, no quotas. Pull public Reddit data straight to structured JSON. No account to create, no OAuth to wire, no developer app to register.
- 🎯 Search or paste URLs, your choice. Search all of Reddit by keyword, restrict a search to one subreddit, or drop in exact subreddit, post, or user URLs. Both modes return the same clean schema.
- 🧮 Every signal Reddit exposes. Upvotes, upvote ratio, comment counts, flair, media URLs, karma, community size, account age. Around 38 fields per record, the numbers you actually rank and filter on.
- 🕑 Full sort and time control. Hot, new, top, rising, most-comments, or relevance, over any window from the past hour to all time. Grab this week's top posts or a subreddit's all-time best in one call.
- 📈 Scale from one thread to a full subreddit. Pull a single post or sweep an entire subreddit's history, with no fixed cap on how many items a run returns.
🎯 What you can do with Reddit data
| Team | What they build |
|---|---|
| Brand & social | Track every mention of a product or company across subreddits, with score and comment context |
| Market research | Map which communities discuss a topic, how large they are, and who drives the conversation |
| Content & trends | Surface this week's top and rising posts in any niche before they hit the mainstream |
| Lead generation | Find active users and niche subreddits around a topic to target outreach and community seeding |
| Data science / ML | Pull large post and comment corpora for sentiment, classification, and LLM training sets |
| Academic research | Study online communities, opinion dynamics, and user behavior at scale |
| Product & CX | Collect unfiltered feature requests and complaints straight from the communities that use you |
📥 Input parameters
URL scraping
| Parameter | Type | Description |
|---|---|---|
startUrls | array | Reddit URL(s) to scrape (subreddits, posts, users, search pages) |
Supported URL types:
- Subreddits:
https://www.reddit.com/r/programming/ - Subreddit sort:
https://www.reddit.com/r/programming/hot - Posts:
https://www.reddit.com/r/learnprogramming/comments/abc123/... - Users:
https://www.reddit.com/user/username - User comments:
https://www.reddit.com/user/username/comments/ - Search:
https://www.reddit.com/search/?q=keyword - Popular:
https://www.reddit.com/r/popular/ - Leaderboards:
https://www.reddit.com/subreddits/leaderboard/crypto/
Search
| Parameter | Type | Description |
|---|---|---|
searches | array | Keywords to search on Reddit |
searchCommunityName | string | Restrict search to a specific subreddit (e.g. programming) |
searchTypes | array | Types of results: posts, communities, users (default: posts) |
Sorting & filtering
| Parameter | Type | Default | Description |
|---|---|---|---|
sort | string | new | Sort by: relevance, hot, top, new, rising, comments |
time | string | all | Time filter: all, hour, day, week, month, year |
includeNSFW | boolean | true | Include adult/NSFW content |
postDateLimit | string | - | Only posts after this date (YYYY-MM-DD) |
Options & limits
| Parameter | Type | Default | Description |
|---|---|---|---|
includeComments | boolean | true | Also scrape comments when visiting posts |
maxItems | integer | 50 | Maximum total items to return (no fixed cap) |
📊 Output data
Post
Comment
Community
User
🗂️ Data fields
| Category | Fields |
|---|---|
| Identity | id, parsedId, url, username, userId |
| Content | title, body, html, flair |
| Community | communityName, parsedCommunityName, category, numberOfMembers |
| Engagement | upVotes, upVoteRatio, numberOfComments, numberOfreplies, postKarma, commentKarma |
| Media | imageUrls, videoUrl, thumbnailUrl, link |
| Flags | isVideo, isAd, over18 |
| Meta | createdAt, scrapedAt, dataType |
🚀 Examples
Scrape a subreddit's hottest posts
Search Reddit for a topic across posts and communities
Pull a thread with all its comments
Find active users around a topic
Search inside a single subreddit
Get only fresh posts from a subreddit
🤖 Copy to your AI assistant
Paste this block into Claude, ChatGPT, or Cursor to give it full context about this scraper:
💻 Integrations
Build a brand-mention monitor (Python)
Track this week's top posts in a niche (JavaScript)
Export a run to CSV (dataset API)
📈 Performance
| Metric | Value |
|---|---|
| Data types | Posts, Comments, Communities, Users |
| Items per page | up to 100 |
| Items per run | No fixed limit (set with maxItems) |
| Search modes | keyword, subreddit-scoped, URL |
| Login required | No |
💾 Data export
Every run writes to an Apify dataset you can export as JSON, CSV, Excel, XML, RSS, or HTML from the Storage tab, or pull programmatically:
Connect it to Google Sheets, Airtable, or your warehouse with an Apify integration or a scheduled webhook.
💡 Tips for best results
- Scope your run with
maxItems. Request only the number of results you need, then scale up once the output looks right. - Target specific subreddits. Focused scraping returns cleaner, more relevant data than broad searches.
- Turn off comments when you only need posts. Set
includeComments: falseto return post-level data only and cut the result count. - Combine search types. Use
searchTypes: ["posts", "communities"]to find both discussions and the subreddits behind them in one run. - Test with 10 items first. Verify your input returns what you expect before launching a large scrape.
❓ FAQ
Q: What exactly can it scrape? A: Public Reddit posts, comments, communities (subreddits), and user profiles, with full metadata. Four data types in one actor.
Q: Do I need a Reddit account or API key? A: No. It reads publicly available data. No login, no OAuth, no developer app, no rate-limit quotas.
Q: What is the difference between search and URL mode? A: Search mode takes keywords and queries all of Reddit (optionally scoped to one subreddit). URL mode takes exact subreddit, post, or user links. Both return the same schema.
Q: Can I scrape communities and users, not just posts?
A: Yes. Set searchTypes to include communities or users, or pass user and subreddit URLs directly. Most Reddit scrapers only return posts and comments.
Q: How do I control how much data I get?
A: Use maxItems. It caps the total number of results returned per run, across posts, comments, communities, and users.
Q: What if a run finds no results? A: The run finishes cleanly with an empty dataset. Refine your search terms, sort, or time filter and run it again.
Q: Can I scrape private subreddits? A: No. The scraper only accesses publicly available data.
Q: Can I limit results to recent posts?
A: Yes. Set postDateLimit (YYYY-MM-DD) to keep only posts after a given date, or use time to filter by past hour, day, week, month, or year.
Q: How fresh is the data? A: Every item is fetched live at scrape time, so scores, comment counts, and karma reflect the moment of the run.
Q: Why are some fields empty, like flair or media?
A: Reddit only returns them when the post has them. flair is null for untagged posts, and imageUrls/videoUrl are empty for text posts.
⚖️ Legal
This Actor extracts publicly available data from Reddit. It does not bypass any login, paywall, or CAPTCHA, and does not access private subreddits or non-public content. Users are responsible for complying with Reddit's terms of service and applicable laws in their jurisdiction. The data returned is informational; verify accuracy for regulated use cases.
📬 Support
Need something this scraper doesn't do yet? We ship features fast.
- Feature requests go straight to our backlog
- Enterprise needs? We do custom integrations and high-volume plans
- Pricing questions? Check the Monetization tab on the actor page
Check out our other scrapers: silentflow on Apify