Nofluffjobs Jobs Search Scraper
Pricing
from $2.00 / 1,000 results
Nofluffjobs Jobs Search Scraper
Scrape comprehensive job listings from NoFluffJobs.pl, Poland's leading tech recruitment platform. Extract IT job postings with transparent salaries, tech stacks, remote work options, and seniority levels. Perfect for recruitment agencies, tech talent analysis, and Polish IT market intelligence.
Pricing
from $2.00 / 1,000 results
Rating
0.0
(0)
Developer
Stealth mode
Maintained by CommunityActor stats
0
Bookmarked
12
Total users
1
Monthly active users
3 months ago
Last modified
Categories
Share
NoFluffJobs.pl Jobs Search Scraper: Extract Polish Tech Job Market Data
Understanding NoFluffJobs.pl and Its Tech Recruitment Value
NoFluffJobs.pl dominates Poland's tech recruitment landscape as the platform where IT professionals find positions with transparent salary ranges and detailed technical requirements. Unlike generic job boards, NoFluffJobs specializes exclusively in technology roles—software development, DevOps, data science, QA, IT management, and more—making it the authoritative source for understanding Poland's booming tech sector.
The platform's defining feature is salary transparency. Every posting displays compensation ranges, eliminating the typical guessing game of tech recruitment. Combined with detailed technology stacks (specific programming languages, frameworks, tools), remote work availability, and seniority classifications, NoFluffJobs provides the structured data essential for tech talent intelligence.
Poland has emerged as Central Europe's tech hub, with major development centers in Warsaw, Kraków, Wrocław, and Gdańsk. For recruitment agencies targeting Polish developers, market researchers analyzing Eastern European tech trends, or companies benchmarking compensation, NoFluffJobs data reveals hiring patterns, salary standards, and skill demands that define one of Europe's fastest-growing tech markets.
Manual collection across hundreds of tech searches would require extensive clicking and copying. This scraper automates the entire process, transforming search pages into structured datasets ready for talent acquisition, competitive analysis, or market research.
What This Scraper Extracts and Who Should Use It
The NoFluffJobs.pl Jobs Search Scraper processes search result pages—the listings displayed when filtering by technology, location, or seniority. It captures multiple job postings efficiently from each search page rather than individual job details.
Key extracted data includes job titles, company names, locations, technologies (primary and supplementary), salary ranges, seniority levels, posting/renewal dates, remote work status, and various promotional flags (highlighted, top in search, help4UA support badges).
Target users:
Tech Recruitment Agencies build candidate databases filtered by specific tech stacks (React, Python, Kubernetes) and seniority. Salary Analysts benchmark compensation across Polish cities, technologies, and experience levels. Tech Companies monitor competitor hiring activity, track emerging technology adoption, and identify talent shortages. Market Researchers analyze Poland's tech sector growth, remote work trends, and regional development center expansion. Career Counselors provide students and professionals with real-time data about in-demand skills and salary expectations.
Input Configuration: Search URLs and Parameters
The scraper processes NoFluffJobs search result URLs displaying multiple listings, not individual job detail pages.
Example Input:
Example Screenshot:
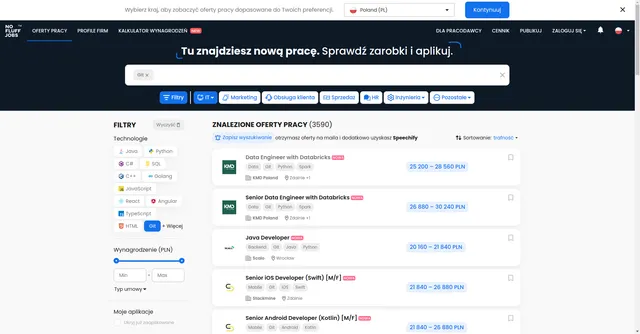
Parameter Breakdown:
proxy configuration: Set useApifyProxy: false for basic scraping. NoFluffJobs.pl typically doesn't require residential proxies, but enable if encountering blocking. No proxy country selection needed when disabled.
max_items_per_url: Controls extraction limit per search page. NoFluffJobs typically displays 20-50 jobs per page. Setting to 20 collects a full standard page. Increase to 50-100 for comprehensive extraction if pages contain more results.
ignore_url_failures: When true, continues processing remaining URLs even if some fail. Essential for large URL lists where individual broken links shouldn't stop the entire run.
urls array: Contains search result page URLs. Example formats:
- Technology search:
https://nofluffjobs.com/pl/[technology](e.g.,/pl/Python,/pl/React) - Location + tech:
https://nofluffjobs.com/pl/Warszawa/[technology] - Seniority filter:
https://nofluffjobs.com/pl/[technology]?seniority=senior - Remote only:
https://nofluffjobs.com/pl/[technology]?fullyRemote=true
Building URL lists: Perform searches manually on NoFluffJobs to apply filters (city, seniority, remote), then copy those URLs. For broad datasets, create multiple URLs covering different technologies, locations, or seniority levels.
Complete Output Structure and Field Definitions
ID: Unique numeric identifier for each job posting. Purpose: Primary database key, tracking specific positions over time, avoiding duplicates when merging datasets.
Name: Company name posting the job. Purpose: Employer identification, tracking which companies actively hire, building employer databases for talent mapping.
Location: Job's geographic location, typically Polish cities (Warszawa, Kraków, Wrocław, Gdańsk, Poznań) or "Polska" for nationwide. Purpose: Geographic analysis, filtering local vs. remote opportunities, understanding regional tech hub growth.
Posted: Initial posting timestamp. Purpose: Freshness indicator for candidate engagement, analyzing posting patterns (days of week, seasonal trends), calculating time-to-fill.
Renewed: Last renewal/update timestamp. Purpose: Identifying difficult-to-fill positions (frequent renewals), tracking active recruitment efforts, detecting evergreen hiring needs.
Title: Job position as posted (e.g., "Senior Python Developer," "DevOps Engineer," "React Frontend Developer"). Purpose: Role categorization, search/filter functionality, trend analysis of in-demand positions.
Technology: Primary technology/skill for the position. Purpose: Core tech stack identification, filtering jobs by primary expertise area, tracking technology adoption trends.
Logo: URL to company logo image. Purpose: Visual assets for job displays, employer branding analysis, enhancing recruitment platform UX.
Category: Job category classification (Backend, Frontend, Fullstack, DevOps, Mobile, Data, QA, etc.). Purpose: Broad role categorization, market segment analysis, candidate specialization matching.
Seniority: Experience level required (Junior, Mid, Senior, Expert, C-Level). Purpose: Filtering by experience, analyzing market distribution across seniority levels, salary benchmarking by experience.
URL: Direct link to full job posting. Purpose: Accessing complete job details, sharing opportunities, verification of scraped data.
Regions: Array of specific regions/cities where job is available. Purpose: Multi-location position identification, regional demand analysis, matching candidates to preferred locations.
Fully Remote: Boolean indicating if position is 100% remote. Purpose: Remote work trend analysis, filtering remote-only opportunities, understanding remote adoption by company/tech stack.
Salary: Compensation range object typically containing min/max values and currency. Purpose: Salary benchmarking across technologies/seniorities/locations, compensation intelligence, market rate analysis.
Flavors: Array of supplementary technologies, frameworks, or tools (e.g., ["Docker", "AWS", "PostgreSQL"]). Purpose: Complete tech stack understanding, identifying technology combinations, skill requirement analysis.
Top In Search: Boolean flag indicating premium search ranking. Purpose: Identifying employer investment in visibility, competitive intelligence on recruitment urgency.
Highlighted: Boolean showing if job is visually highlighted in listings. Purpose: Premium placement indicator, tracking employer recruitment marketing investment.
Help4UA: Boolean badge showing companies supporting Ukrainian professionals. Purpose: Identifying inclusive employers, analyzing corporate social responsibility in hiring, tracking refugee support programs.
Reference: Internal reference code or identifier. Purpose: Linking to employer's internal job tracking systems, cross-referencing with other data sources.
Search Boost: Numeric indicator of search ranking boost level. Purpose: Quantifying employer visibility investment, analyzing correlation between boost and fill rates.
Online Interview Available: Boolean indicating virtual interview availability. Purpose: Understanding remote hiring processes, tracking modern recruitment practice adoption.
Tiles: Array of visual badges or feature tags displayed on job listing. Purpose: Identifying special features (equity offered, flexible hours, training budget), categorizing employer benefits.
Applied Without Account: Boolean showing if application possible without platform registration. Purpose: Understanding application friction, analyzing barrier-to-apply strategies.
Sample Output:
Step-by-Step Usage Guide
1. Define Target Data: Decide which tech jobs to collect. Consider specific technologies (Python, JavaScript, DevOps), locations (Warsaw tech hubs, remote-only), or seniority levels. Test searches on NoFluffJobs to verify results match needs.
2. Build Search URLs: Copy URLs from test searches. For comprehensive data, create multiple URLs covering different tech stacks, cities, or filters. Include pagination URLs (?page=2, ?page=3) for deep extraction.
3. Configure Input: Set up JSON with URL list. Adjust max_items_per_url (20 for standard pages, 50+ for comprehensive). Keep ignore_url_failures: true for robustness with large URL lists.
4. Execute Scraping: Launch via Apify console. Monitor real-time progress. Processing 5-10 search pages typically completes in 2-4 minutes, varying with platform load.
5. Review Data Quality: Preview dataset results. Verify critical fields (title, company, salary, technology) are populated correctly. Check for missing data patterns.
6. Export and Analyze: Export in preferred format—JSON for databases, CSV for spreadsheets. Filter by seniority, remote status, or salary ranges based on research needs.
7. Handle Pagination: For large datasets, either include multiple page URLs (/pl/Python?page=1, /pl/Python?page=2) or set max_items_per_url higher than page display limit to auto-handle pagination.
Error Troubleshooting: If URLs fail consistently, verify they're search pages not job detail pages. Ensure technology names in URLs match NoFluffJobs format (case-sensitive). Check activity logs for specific error details.
Strategic Applications for Tech Recruitment Intelligence
Salary Benchmarking: NoFluffJobs' transparent salaries enable precise compensation analysis. Track salary ranges by technology (Python vs. Java), seniority (Junior vs. Senior), and location (Warsaw vs. Wrocław). Identify premium-paying technologies and regional compensation differences.
Tech Stack Trend Analysis: Monitor "flavors" field frequency across hundreds of jobs to identify emerging technologies. Track adoption of cloud platforms (AWS vs. Azure vs. GCP), containerization (Docker, Kubernetes), and framework preferences (React vs. Vue, Spring Boot vs. Django).
Remote Work Evolution: Analyze "fully_remote" patterns over time. Identify which companies/technologies offer most remote positions. Correlate remote work with salary levels and geographic distribution changes.
Competitive Hiring Intelligence: Track competitors' posting frequency, technologies hired for, seniority distributions, and renewal patterns (frequent renewals = hard to fill). Monitor "top_in_search" and "highlighted" usage to understand recruitment marketing investment.
Regional Tech Hub Analysis: Compare job volumes, average salaries, and technology distributions across Polish cities. Identify emerging tech centers beyond Warsaw/Kraków. Understand regional specializations (e.g., Wrocław = gaming, Gdańsk = fintech).
Seniority Distribution Insights: Analyze market composition across experience levels. High junior demand signals company growth; senior-heavy hiring indicates specialized project needs or technical debt resolution.
Skill Combination Patterns: Cross-reference "technology" with "flavors" to understand typical tech stack combinations. Example: Backend Java positions commonly require Spring Boot, PostgreSQL, Kafka—informing candidate skill development strategies.
Ukrainian Talent Support Tracking: "Help4UA" field enables analyzing which companies actively support Ukrainian professionals, revealing corporate social responsibility patterns in Polish tech sector.
Maximizing Data Value: Advanced Techniques
Temporal Tracking: Scrape weekly to build historical datasets. Track how long positions remain active (posted date to disappearance), identify seasonal hiring patterns, and monitor salary inflation over time.
Technology Correlation Analysis: Cross-reference technologies with salary ranges to identify highest-paying skills. Determine if certain tech combinations (e.g., Python + AWS + Kubernetes) command premium compensation.
Geographic Arbitrage Opportunities: Compare salaries for identical roles across cities. Identify markets with talent shortages (higher salaries) vs. oversupply (lower salaries). Guide remote workers toward higher-paying markets.
Employer Investment Scoring: Create composite scores from "top_in_search," "highlighted," and "search_boost" to rank employers by recruitment urgency/investment. Correlate with renewal frequency to identify chronic hiring challenges.
Application Friction Analysis: Track "applied_without_account" adoption rates. Identify if low-friction application processes correlate with faster fill times (fewer renewals).
Seniority Salary Progression: Calculate average salary increases from Junior → Mid → Senior → Expert for specific technologies. Provide career progression benchmarks for professionals.
Remote vs. On-Site Premium: Compare salaries for fully remote positions vs. on-site for same technology/seniority. Quantify "remote work premium" or discount in Polish market.
Tech Stack Complexity Measurement: Count "flavors" array length to measure role complexity. Correlate with salary and seniority to understand compensation for specialized vs. generalized positions.
Data Quality and Best Practices
Update Frequency: Polish tech market changes rapidly. Scrape weekly for active recruitment databases, bi-weekly for trend analysis. Balance data freshness against resource consumption.
Technology Normalization: NoFluffJobs uses specific technology names. Build mapping tables to normalize variations (e.g., "JavaScript," "JS," "Node.js") for consistent analysis.
Salary Currency Standardization: All salaries in PLN (Polish Złoty). Convert to EUR/USD using current exchange rates for international comparisons. Store both original and converted values.
Duplicate Detection: Same company may post similar positions in multiple cities. Use combination of company name, title, and technology to detect near-duplicates while preserving legitimate multi-location openings.
Validation Rules: Flag anomalies—salaries below market minimums, missing critical fields (technology, location), or unusual renewal patterns (renewed daily = possible data issues).
Enrichment Strategies: Combine NoFluffJobs data with company LinkedIn pages, Glassdoor reviews, or GitHub profiles. Cross-reference with cost-of-living data to calculate real purchasing power across Polish cities.
Privacy Compliance: While job data is public, company names and contact information require appropriate handling under GDPR. Use data for intended recruitment/research purposes with proper data governance.
Conclusion
The NoFluffJobs.pl Jobs Search Scraper unlocks Poland's tech recruitment intelligence through the country's leading IT job platform. From transparent salary data enabling precise compensation benchmarking to detailed tech stacks revealing skill demands, this tool transforms public job listings into competitive advantage. Whether building recruitment pipelines, analyzing Central European tech markets, or optimizing hiring strategies, NoFluffJobs data provides the structured insights essential for succeeding in one of Europe's fastest-growing tech ecosystems. Start extracting Polish tech talent intelligence today.