Email Finder API — MX-Verified Contacts & Phones
Pricing
from $20.00 / 1,000 url processeds
Email Finder API — MX-Verified Contacts & Phones
Email finder API and contact scraper for B2B enrichment: crawl domains, return MX-verified emails, role labels, normalized phones, socials, and CRM-ready JSON. Fast direct mode by default; Firecrawl and social validation are opt-in. Guide: https://konabayev.com/tools/contact-finder-pro/
Pricing
from $20.00 / 1,000 url processeds
Rating
0.0
(0)
Developer
Tugelbay Konabayev
Maintained by CommunityActor stats
0
Bookmarked
8
Total users
2
Monthly active users
14 days ago
Last modified
Categories
Share
Email Finder API — MX-Verified Contacts, Phones, Role Detection
Premium contact-info extractor. Built for B2B teams who need contact data they can actually use — not regex dumps full of dead emails and broken social links. MX-verified emails — every email's domain is checked for live MX records. Junk gets dropped, not shipped. Role classification —
sales@,careers@,support@,legal@,press@,personalautomatically tagged so you can target the right inbox. Phone E.164 normalization — international format ready for dialer/CRM import. Social profile discovery — Facebook, Instagram, Twitter/X, LinkedIn, YouTube, TikTok, GitHub URLs returned in CRM-ready JSON; HEAD validation is available when needed. Multi-page crawl per domain — homepage + common contact paths; default direct mode keeps first runs fast and cheap. Firecrawl anti-bot fallback — optional full browser rendering for Cloudflare/Akamai sites when direct fetch does not find contacts.
Full production guide: Contact Finder Pro workflows.

Why Pro
The cheap contact-info scrapers on Apify Store ship raw extraction. They regex any something@something.com they find, dump the result, and call it done. The most popular alternative, vdrmota/contact-info-scraper (3.59 ★, 79 reviews), has 99% reliability — the complaint isn't that it fails. The complaint is the output is unusable: bounced emails, broken social URLs, no role context, raw phones in 5 different formats.
Pro is built around the validation gap:
| Layer | Pro | Incumbent |
|---|---|---|
| Email MX verification (drops dead domains) | Yes | Mostly no |
| Email role classification | sales / support / careers / legal / press / billing / personal / info | Raw email only |
| Phone normalization (E.164) | International format | As-found |
| Social profile validation (HEAD 200 check) | Optional | Raw URL only |
| Multi-path crawl per domain | 3 paths by default, configurable up to 10 | Configurable but billed per page |
| Anti-bot fallback (Firecrawl) | Optional | Manual config |
| Per-record quality score | 0.0-1.0 | None |
JSON-LD Organization schema parsing | Yes | No |
| Pricing model | PPE — pay per delivered VALUE | PPE — pay per page scraped |
What You Get
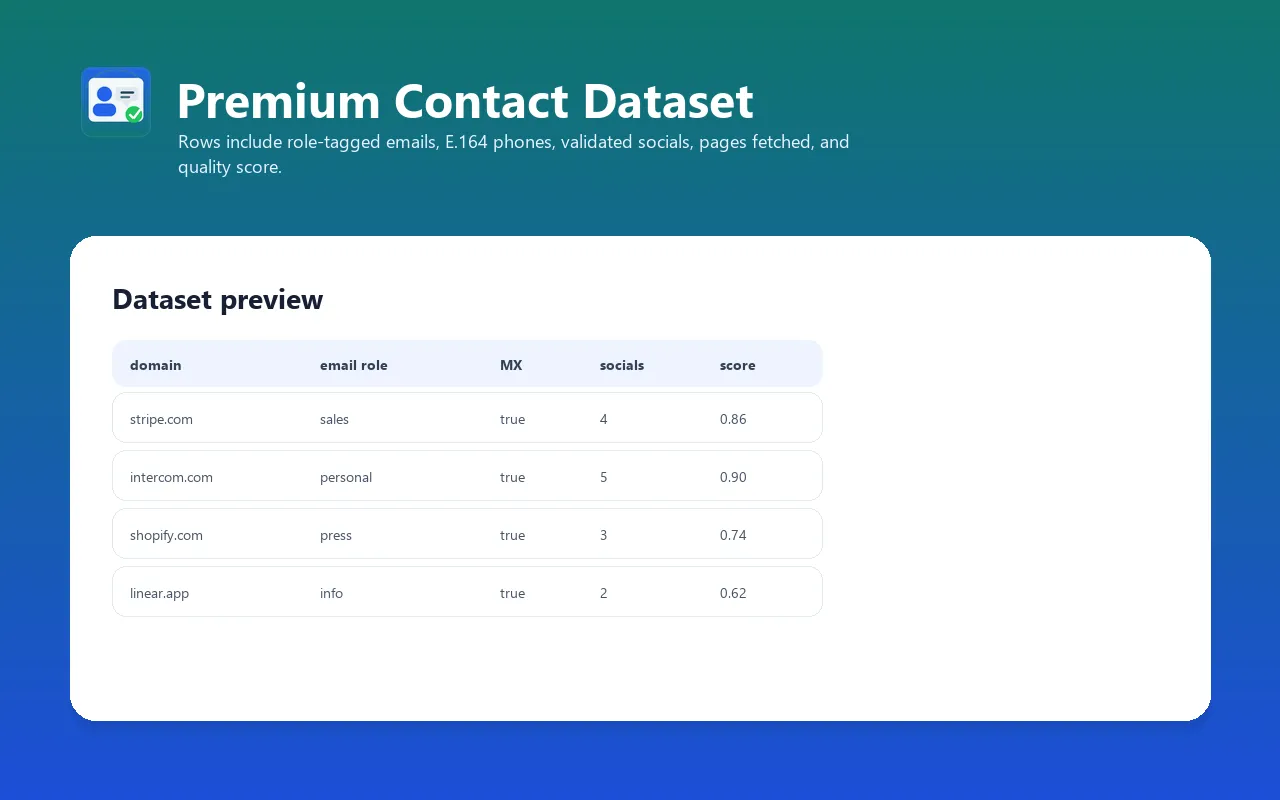
For each input URL, one structured record:
Core fields
inputUrl— what you submitteddomain— extracted domain (lowercased, nowww.)companyName— pulled from JSON-LD Organization, og:site_name, og:title, or<title>pagesFetched— how many candidate pages were actually retrievedfirecrawlUsed—trueif Firecrawl rescue was triggeredextractedAt— ISO 8601 UTC timestampqualityScore— 0.0-1.0 weighted completeness
Emails
Roles: sales, support, careers, legal, press, billing, info, personal.
Phones
Numbers that fail E.164 normalization but contain at least 10 digits are still emitted with e164: null so you can normalize them yourself.
Socials
Platforms detected: facebook, instagram, twitter (X), linkedin, youtube, tiktok, github. validated: true means the profile URL responded HTTP 200 to a HEAD request.
Quality SLA
Pro enforces a contract on every run before publishing the dataset:
| Metric | Target | What it means |
|---|---|---|
| Min items returned | 1 | If a query returns nothing, the run fails loudly instead of silently shipping an empty dataset. |
| Min contact rate | 50% | At least half of input URLs must return at least one email/phone/social. |
| Min average quality score | 0.30 | Average completeness across the dataset. |
If the dataset misses these targets, the run is flagged so you can re-run on a different input/proxy instead of paying for junk.
Input Examples
Quick test
CRM enrichment (large list, full validation)
Cost-controlled bulk run
Region-specific (UK phones)
Output Example
Pricing — Pay Per Event
Current Apify pricing schedule starts at 2026-05-20T00:00:00Z.
Charged only when delivered value matches:
| Event | Price | When charged |
|---|---|---|
actor-start | $0.05 | Once per run |
url-processed | $0.02 | Per emitted dataset record with at least one contact |
email-verified | $0.05 | Per email confirmed deliverable via MX |
social-validated | $0.02 | Per social profile that responded HTTP 200 |
Realistic run costs
| Scenario | Breakdown | Total |
|---|---|---|
| 100 domains, 30 returned 1+ verified email + 3 socials | $0.05 + 100 × $0.02 + 30 × $0.05 + 90 × $0.02 | $5.35 |
| 50 domains, full enrichment, 40 hits | $0.05 + 50 × $0.02 + 40 × $0.05 + 80 × $0.02 | $4.65 |
| 1,000 domains bulk, no enrichment | $0.05 + returned domains × $0.02 | usage-based |
You pay for delivered VALUE, not for infrastructure. If a domain returns nothing, no url-processed charge fires.
Best Use Cases
- B2B sales prospecting — feed your TAM domain list, get sales@/info@ contacts you can mail.
- CRM enrichment — append role-tagged emails, normalized phones, and optional validated socials to existing accounts.
- Investor research — extract press@, founder personal emails, and verified LinkedIn/Twitter profiles from portfolio companies.
- Recruitment — pull careers@/jobs@ contacts from target companies for outbound recruiter outreach.
- Compliance / DPO discovery — many privacy@ and dpo@ emails live on
/legal/privacypages — Pro's multi-path crawl finds them. - PR / media outreach —
press@andmedia@emails pre-classified, ready for distribution lists. - Competitor intel — quickly gather public contact surface from competitor sites with quality score 0.6+.
Programmatic Usage
Python
JavaScript / TypeScript
LangChain tool
MCP (Streamable HTTP)
FAQ
Q: How is "MX-verified" different from full SMTP probe?
A: MX verification confirms the domain is set up to receive mail at all — it catches ~80% of dead/junk addresses (typos, parked domains, abandoned sites) without the false-positive rate of SMTP probing (which many mail servers refuse). For deeper validation pipe email through NeverBounce or ZeroBounce after this run.
Q: Why don't most modern SaaS sites return any emails?
A: They moved to contact forms behind /contact-sales. There is no email on the page to extract. Pro will still return companyName, discovered socials, and any phones. For raw email harvesting at SaaS companies, follow up with a tool that extracts founder/employee emails from LinkedIn (separate actor).
Q: Will Firecrawl be charged when my run uses it? A: Firecrawl calls happen on the actor's compute cost, not yours. The premium PPE pricing already accounts for fallback usage. You don't pay separately.
Q: What if a domain returns nothing?
A: No url-processed charge is fired (you only pay for VALUE). The actor logs no contacts found for X and moves on.
Q: Does it follow redirects?
A: Yes — httpx follows redirects, and the final URL's domain is what gets emitted in the domain field.
Q: International support?
A: All extraction works globally. For phone normalization, set countryHint to the most-common country code in your input list (GB, DE, FR, etc.). US is the default.
Q: How does this differ from official Hunter.io / Apollo / ZoomInfo APIs? A: Those services charge per-lead with monthly minimums ($49+ Hunter, $99+ Apollo). Pro is PPE — pay only when you actually receive a verified contact. For occasional prospecting, dramatically cheaper.
Troubleshooting
Empty dataset across all URLs
- Check that
urlsis set; the actor falls back to a demo URL and warns if not. - Some domains (LinkedIn, Twitter accounts directly) are heavily rate-limited — try variants.
- Disable
firecrawlFallbackto rule out timeouts at the fallback layer.
Many emails returned but verified: false
- Domain might have temporary DNS issues — retry the run.
- The MX lookup falls back to
8.8.8.8/1.1.1.1automatically; if your domain has authoritative-only DNS, verification will be inconclusive.
Phones look like CSS color codes
- Pro filters phones to E.164-normalized OR 10+-digit. If you still see noise, lower
maxPagesPerDomainto 3 (skips footer/legal pages where SPA color tokens live).
Slow runs
- Set
validateSocialProfiles: falseto skip the per-profile HEAD checks (saves about 3s per social URL). - Set
firecrawlFallback: falseif you don't need the anti-bot rescue. - Drop
maxPagesPerDomainto 3 (homepage + /contact + /about only).
Limitations
- Email harvesting depends on the site exposing emails on its public pages. Modern SaaS rarely does — Pro will return
companyName+ socials +phoneseven when emails are zero. - MX verification is necessary but not sufficient. A domain with MX records can still have a non-existent mailbox. Pipe
emailthrough SMTP-probe service for deeper validation. - HEAD validation may miss profiles that block HEAD but allow GET. Pro retries with GET on 403/405, but a few platforms (Instagram for non-public profiles) return 200 even for nonexistent users.
- Phone normalization is best-effort. If
phonenumberslibrary cannot parse the number, the raw is still emitted (withe164: null) when 10+ digits. - Crawl is shallow by design — only the listed contact paths, not full-site crawl. For deep crawl, use a separate Apify crawler upstream.
Changelog
- 0.1 (2026-05-06) — Initial release. Multi-path crawl, MX verification, role classification, E.164 phone normalization, social HEAD validation, Firecrawl fallback, JSON-LD parser, quality score. Premium PPE pricing scheduled for 2026-05-20.