Instagram Hashtag Scraper
Pricing
from $1.90 / 1,000 results
Instagram Hashtag Scraper
Scrape Instagram posts and reels by hashtags. Just add one or more hashtags and extract captions, locations, likes, plays, shares, comments count, images, timestamps, audio, and other hashtags. Export scraped hashtags, run the scraper via API, schedule and monitor runs or integrate with other tools.
Pricing
from $1.90 / 1,000 results
Rating
3.2
(80)
Developer
Apify
Maintained by ApifyActor stats
645
Bookmarked
73K
Total users
8.8K
Monthly active users
16 hours
Issues response
3 hours ago
Last modified
Categories
Share
🚀 New: keyword-as-hashtag discovery. You can now scrape reels and posts by keyword as well as hashtag. Try both to get a fuller picture of relevant content. Give it a go and leave a review!
What can Instagram Hashtag Scraper do?
Instagram Hashtag Scraper is a content discovery tool that extracts posts and reels associated with one or multiple hashtags, beyond what the Instagram Hashtag API provides. Add one or a list of hashtags, and you can:
#️⃣ Fetch recent posts and carousels for each hashtag
🎥 Discover recent reels posted under those hashtags
📊 Get engagement metrics like likes, comment counts, shares, views, video length, and plays
🌐 Extract related hashtags to expand audience research and content strategy within a given topic
🧩 Extract metadata such as captions, timestamps, locations, latest comments, tagged users, music info
⬇️ Export your data in JSON, CSV, Excel, or XML
🦾 Access via API, webhooks, Node.js & Python SDKs, and automation tools
Use Instagram Hashtag Scraper to track trending content for topic research, marketing campaigns, or viral pattern analysis, as well as to support content planning, influencer research, competition tracking, UGC discovery, and brand monitoring.
Tip: Need to find popular and trending reels, not only recent ones? Use 🔗 Instagram Search Scraper along with the Instagram Hashtag Scraper.
What data can I scrape from Instagram hashtags?
Instagram Hashtag Scraper extracts key details from each post or reel:
| 🆔 Post/reel ID | 🔗 Post/reel URL | 🧑🎤 Owner username | 👤 Owner full name |
| ❤️ Likes count | 💬 Comments count | 🔄 Shares count (for reels) | 👁️ Video views/play count (for reels) |
| #️⃣ Other hashtags | 📢 Mentions | 👥 Tagged users | 🧚 Child posts (other images from carousel) |
| 📝 Caption | 🕒 Timestamp | 📍 Location name and location ID | 📌 Is post sponsored? |
| 📽️ Video URL and video duration (if reel) | 🎶 Music info (artist, track, original audio) | 🖼️ Images URLs (thumbnails/carousels) | 📊 Media dimensions |
| 🙋♀️ First comment (if keyword) | 💬 10 latest comments (if keyword) | 👍 Facebook likes count, Facebook play count (if keyword) | 🙈 Are comments disabled? (if keyword) |
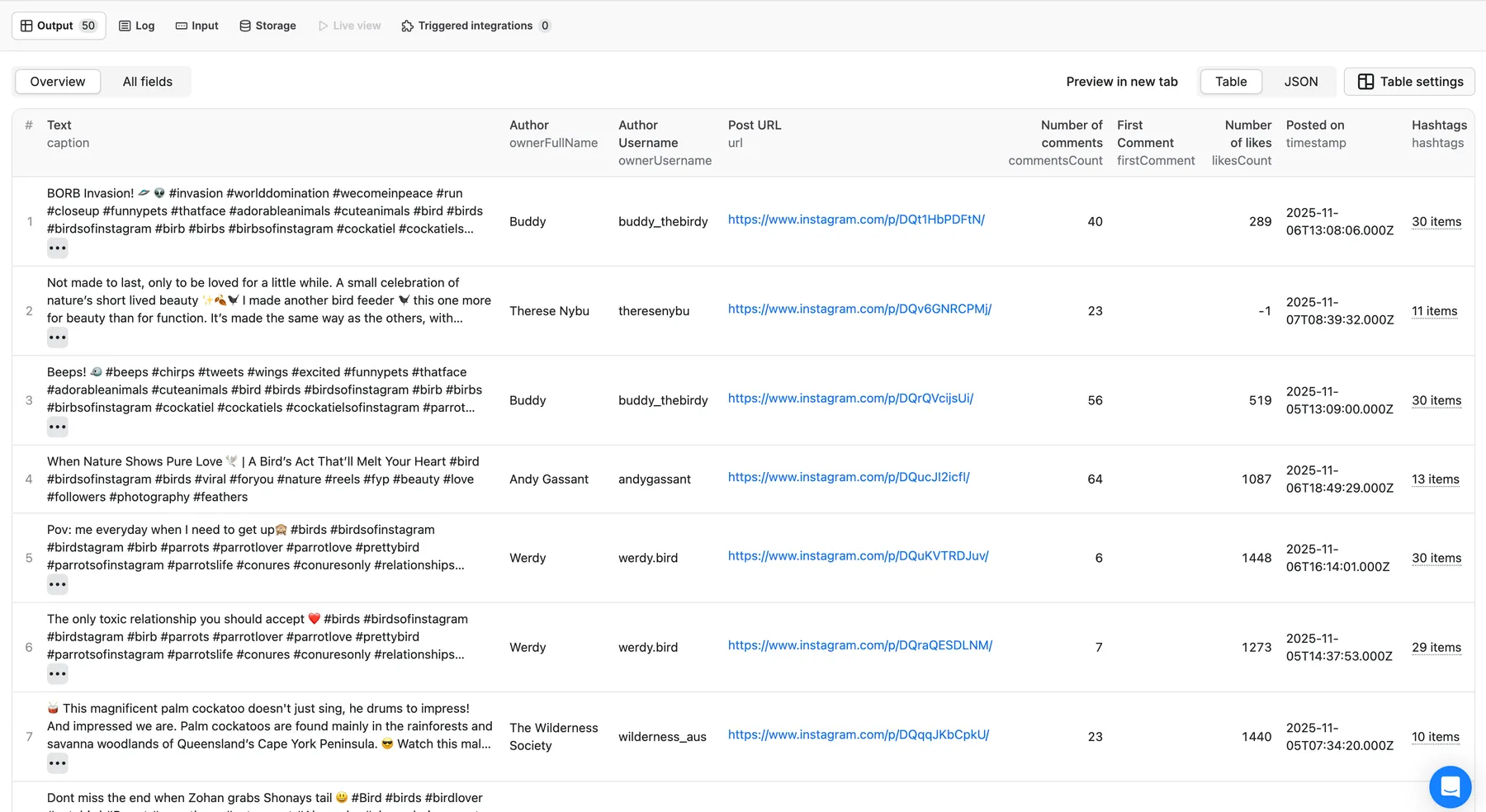
For #birdsofinstagram, the Actor extracted (50 posts):
- a recent video post (31s)
- 289 likes, 2,133 plays, 17 reshares
- Full caption + 30+ hashtags
- Video + image URLs
- Creator info (username + profile ID)
- Music info (artist + track used)
Tip: Need to do hashtag discovery first? You can first find valuable hashtags on your topic using 🔗 Instagram Search Scraper, and then drill down on each hashtag separately using this Instagram Hashtag Scraper. And if you want to extract all possible hashtags on a given topic and know their reach, use our 🔗 Instagram Hashtag Analytics Scraper.
How to scrape Instagram hashtags?
- Create a free Apify account.
- Open Instagram Hashtag Scraper.
- Enter one or multiple hashtags (with or without
#) - Choose whether to scrape posts or reels containing this hashtag, and the number of results per hashtag.
- Click Save & Start.
- Download your dataset in JSON, CSV, Excel, or XML, or access it via API.
If you want step-by-step guidance, here’s a walkthrough video:
Tip: If you're primarily analyzing reel performance itself or need to download reels, use the 🎥 Instagram Reel Scraper for more detailed reel-level metrics. Post-performance? Go for the 🔗 Instagram Post Scraper.
How much will extracting Instagram hashtags cost?
Instagram Hashtag Scraper uses a pay-per-event (PPE) model. On the Free plan, it costs $2.60 per 1,000 results — which means your $5 free credit gets you almost 2,000 results.
Paid plans reduce the PPE rate and include more monthly credit. For example, on the Starter plan, the cost is $2.30 per 1,000 results, giving you over 12,600 results each month with included credit.
Check the Pricing tab for full cost tiers and discounts.
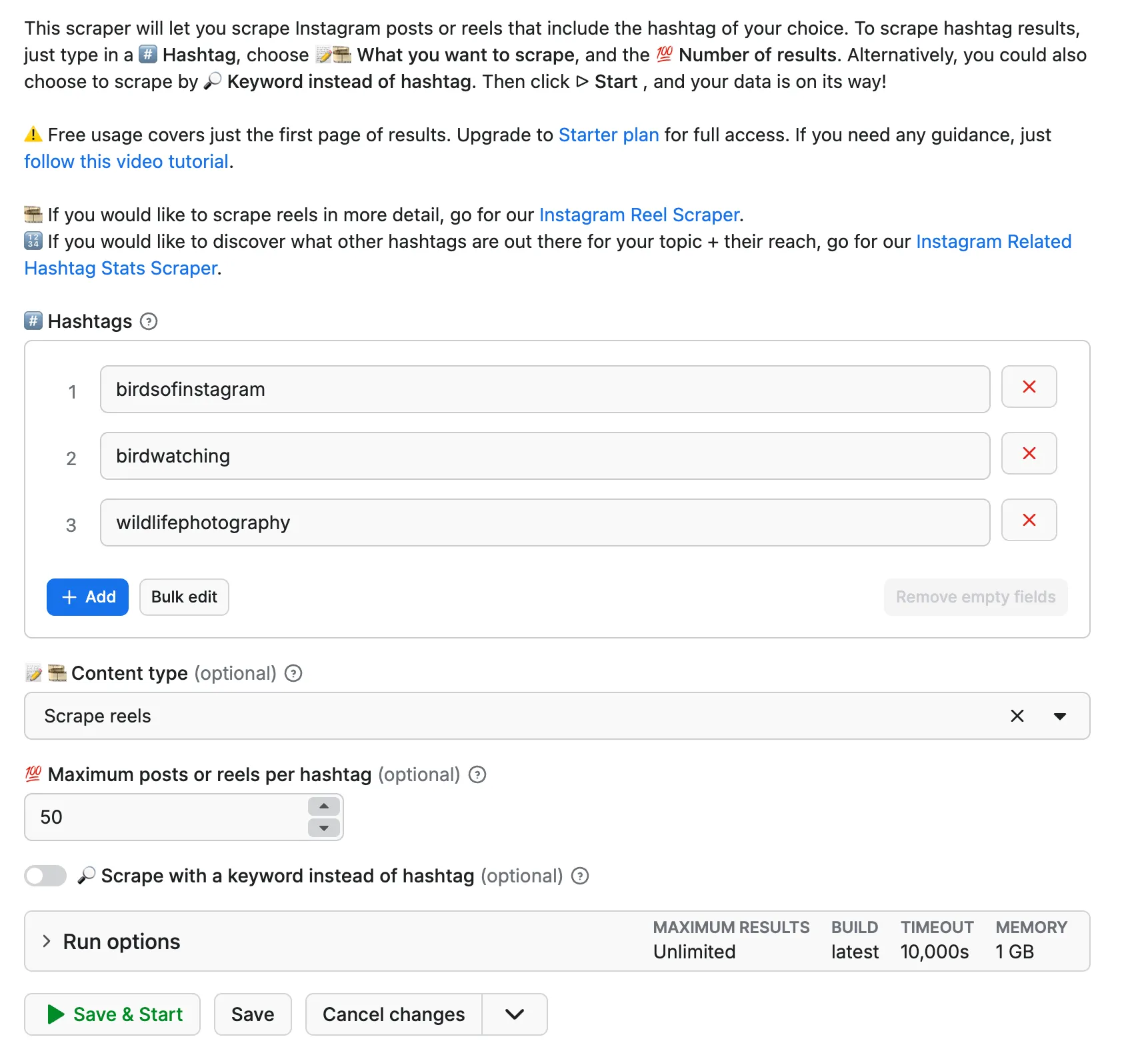
⬇️ Input
Add one or multiple hashtags, choose whether to scrape reels or posts, and add a number of results you expect per hashtag. You can paste them manually or use Bulk edit to add many at once. Alternatively, toggle the scrape by keyword instead of hashtag as well — to get slightly different results.
⬆️ Output
You’ll get a dataset containing all scraped posts and reels for the provided hashtags. The results appear in a dataset in the Storage tab. You can view them as a table, download in JSON, CSV, Excel, or XML, or use API endpoints.
📝 Extracted Instagram post with hashtag sample
🎞️ Extracted Instagram reel with hashtag sample
Want to get other data from Instagram?
You can use the other dedicated scrapers below if you want to scrape specific Instagram data:
For advanced configurations, use the 🔗 Instagram Scraper or 🔗 Instagram API Scraper
❓ FAQ
Are comments included in this Instagram tags extractor?
Yes, this Actor does return the 10 latest comments if the keywords toggle is enabled. If you want all comments from reels or posts, use the 💬 Instagram Comments Scraper for found reels and posts.
What is the difference between extracting Instagram data by hashtag and by keyword?
The dataset will be slightly different. Scraping by keyword also delivers Facebook likes and plays, as well as the latest comments.
Here's an example of scraping by keyword instead of just hashtag. Compare it with the Output example above ⬆️
I want to extract hashtags from Instagram reel. Which Actor should I use?
Use the 🎞️ Instagram Reel Scraper. It extracts full metadata from reels, including captions, hashtags, audio info, engagement metrics, and video URLs.
I want to extract hashtags from Instagram post. Which Actor should I use?
Use the 📷 Instagram Post Scraper. It extracts the caption text and automatically pulls out all hashtags used in the post.
Can I scrape both posts and reels at the same time?
Not with this Actor — it handles one content type at a time. If you need both posts and reels together, use other discovery Actors such as 🔎 Instagram Search Scraper or 🔗 Instagram Hashtag Analytics Scraper, which return mixed content results under a hashtag.
Why is there a -1 on likesCount value on some Instagram reels?
When a user chooses to hide the like count on their reel, Instagram doesn’t display this data publicly. In those cases, the Actor returns -1 for likesCount which indicates that the information isn’t publicly available.
Is it legal to scrape Instagram hashtag data?
This Actor only collects public data available on Instagram. It does not access private accounts or private content. However, some public data may still qualify as personal data under laws like the GDPR. Make sure you have a legitimate purpose for processing it. For more guidance, see our article: Is web scraping legal?
Can I integrate Instagram tag data with other tools?
Yes. You can send the scraped data to almost any app or workflow system. Apify integrates with Zapier, Make, n8n, Slack, Airbyte, Google Sheets, Google Drive, and many others.
You can also use webhooks to trigger actions automatically when a run finishes.
Can I use the Instagram Hashtag scraping data via API?
Yes. You can run it programmatically, pull datasets, and manage tasks using the Apify API.
- Node.js: use the
apify-clientNPM package - Python: use the
apify-clientPyPI package
See full reference docs in the Apify API docs.
Can I use Instagram Hashtag Scraper with an MCP server?
Yes. You can connect to an MCP server using clients like ClaudeDesktop or LibreChat, or build your own integration. For Instagram Reel Scraper:
- Start a Server-Sent Events (SSE) session to receive a
sessionId. - Send API messages using that
sessionIdto trigger the Actor. - The message starts the Instagram Reel Scraper with the provided input.
- The response should be: Accepted.
Learn more in MCP setup guide.
Instagram Hashtag Scraper not working?
We continuously update and improve Actor's reliability. If you notice bugs or changes in Instagram’s structure, please report them on the Actor’s Issues tab so we can fix them quickly.