Instagram Profile Scraper
Pricing
from $1.60 / 1,000 profiles
Instagram Profile Scraper
Scrape all Instagram profile info. Just add Instagram usernames, IDs or URLs and extract name, join date, number of followers, location, bio, website, related profiles, video&post count, latest posts. Export scraped data, schedule scraper via API, and integrate with other tools or AI workflows.
Pricing
from $1.60 / 1,000 profiles
Rating
4.8
(148)
Developer
Apify
Maintained by ApifyActor stats
1.4K
Bookmarked
181K
Total users
22K
Monthly active users
1.3 days
Issues response
2 days ago
Last modified
Categories
Share
🚀 New feature: About profile. You can now scrape information about when the user joined Instagram, got verified, where they are from, or how many times they’ve changed the username. Available as a paid add-on. Try it out and share your feedback in a review!
What can Instagram Profile Scraper do?
Our Instagram Profile Scraper scrape data from public Instagram profiles beyond what the Instagram API allows. Just add one or more Instagram usernames, profile URLs, or profile IDs, and you're ready to:
👤 Extract Instagram data at scale from any public profile with no limits on requests
🌐 Get contact details, links, and websites, if listed in bio
✅ Categorize an account by type: business/private status, category, number of followers/follows, check verification, content stats, and join date
🪢 Map out related accounts to get a broader view of the niche
🎥 Get an overview of the most recent content and its stats – posts, videos, highlights reels, plus the latest 12 posts with details
⬇️ Download Instagram basic profile data in JSON, CSV, Excel, or other formats
🦾 Export posts data via SDKs (Python & Node.js), use API Endpoints & webhooks
🤳 Explore our other social media scrapers
You can use Instagram Profile Scraper to discover creators and businesses by analyzing bios, follower metrics, posting activity, and collecting any contact details or websites they’ve shared. Other options include market research and tracking competitors.
What data can I scrape from Instagram profiles?
Using this Instagram Profile API, you will be able to extract the following Instagram user data:
| 👤 Profile name | 🔗 Profile URL | 🆔 Profile ID | 📝 Profile bio |
| 🌐 External URLs (websites) | 👥 Number of profile followers | ➡️ Number of profile follows | 🧑🤝🧑 Related profiles |
| 📍 Location (if available) | 🔁 Username change count | 🕒 Join date | 🆕 Is the user recently joined? |
| 🎥 Total video count | 📮 Total posts count | 📚 Highlight reels count | 🪪 Facebook ID |
| ✅ Is user verified | ⏱️ When the account got verified | 💼 Is it a business or private account? | 🏢 Business category |
| 📷 Profile pic URL | 📯 Latest image posts, carousels, and videos (12) with details | 📽️ Number of IGTV videos | 📈 Latest IGTV videos (12) with details |
If you're not sure which profiles to extract data from, let's find them first. To find the right profiles to scrape for a niche, first use the keyword search by users in 🔗 Instagram Search Scraper. You can then reuse the resulting list as an input for Instagram Profile Scraper.
And another tip: since both Meta platforms users share a username, you can extract data from both Instagram and Threads at once. To do so, check out our 🔗 Threads Profile Scraper.
How to scrape data from Instagram profiles?
Instagram Profile Scraper is designed to be fast and easy to use, so there aren't too many parameters or settings. Just follow the steps below:
- Create a free Apify account.
- Open Instagram Profile Scraper.
- Add one or multiple Instagram usernames, profile URLs, or profile IDs.
- Click "Save & Start" and wait for the datasets to be extracted.
- Download your data in JSON, XML, CSV, Excel, or HTML.
If you want more guidance on how to use Instagram Profile Scraper, here's a full video that explains it:
For more details, check out our tutorial on how to scrape data from Instagram, full of tips and tricks.
If you would like to scrape not only profile info but also profile's posts or reels — using usernames as input as well — go for our 🔗 Instagram Post Scraper or 🔗 Instagram Reels Scraper, respectively.
How much will scraping Instagram profiles cost you?
Instagram Profile Scraper works on our pay-per-event (PPE) model, meaning you’re charged for each result you receive. On the Free plan, the price is $2.60 per 1,000 results ($0.0026 per result), giving you nearly 2,000 results for free with the $5 credit.
On paid plans, you get discounted rates and more monthly credit. For example, on the Starter plan, it costs just $2.30 per 1,000 results, which lets you scrape over 12,600 results per month. Check the pricing tab for full details.
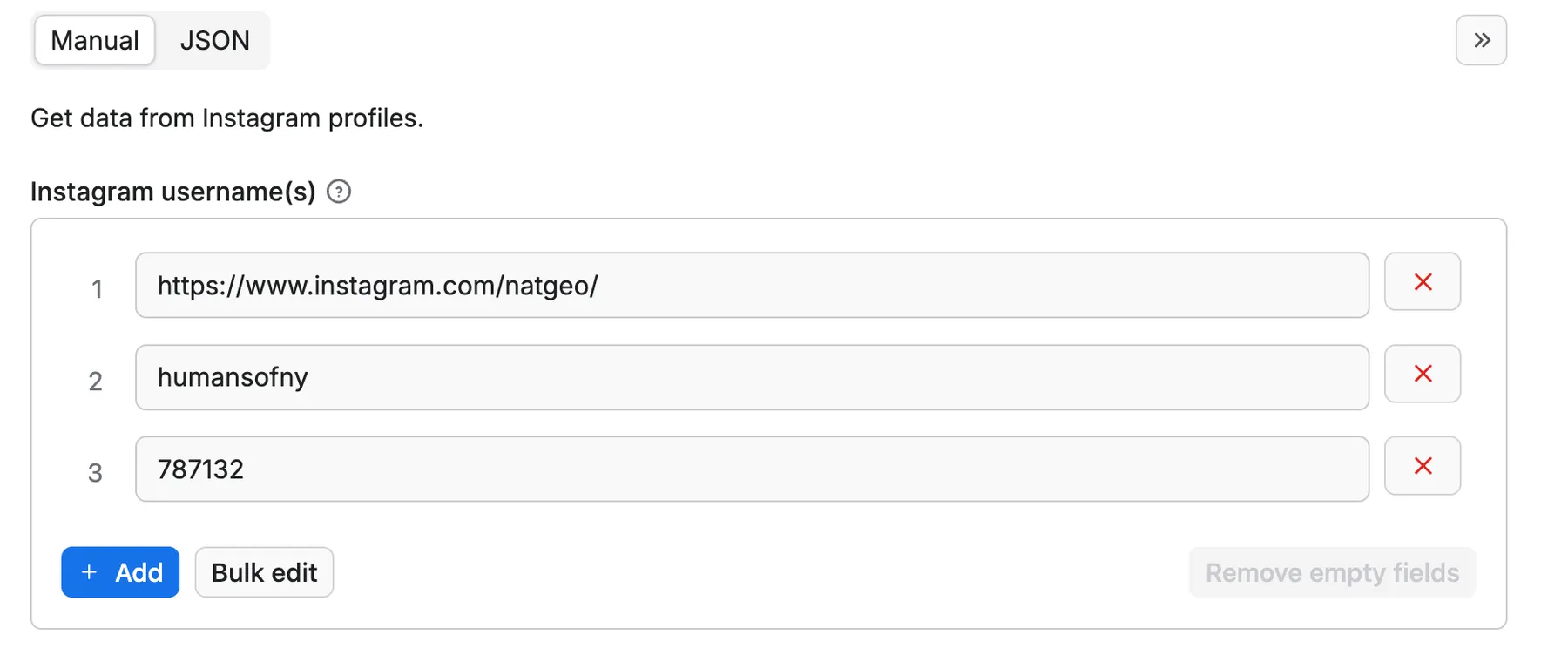
⬇️ Input
To use this Instagram account scraper, enter either a profile URL, Instagram username, or profile ID. You can enter them one by one or all at once using the Bulk edit function.
⬆️ Output
The results will be wrapped into a dataset, which you can find in the Storage tab. Here's an excerpt from the dataset you'd get if you apply the input parameters above:
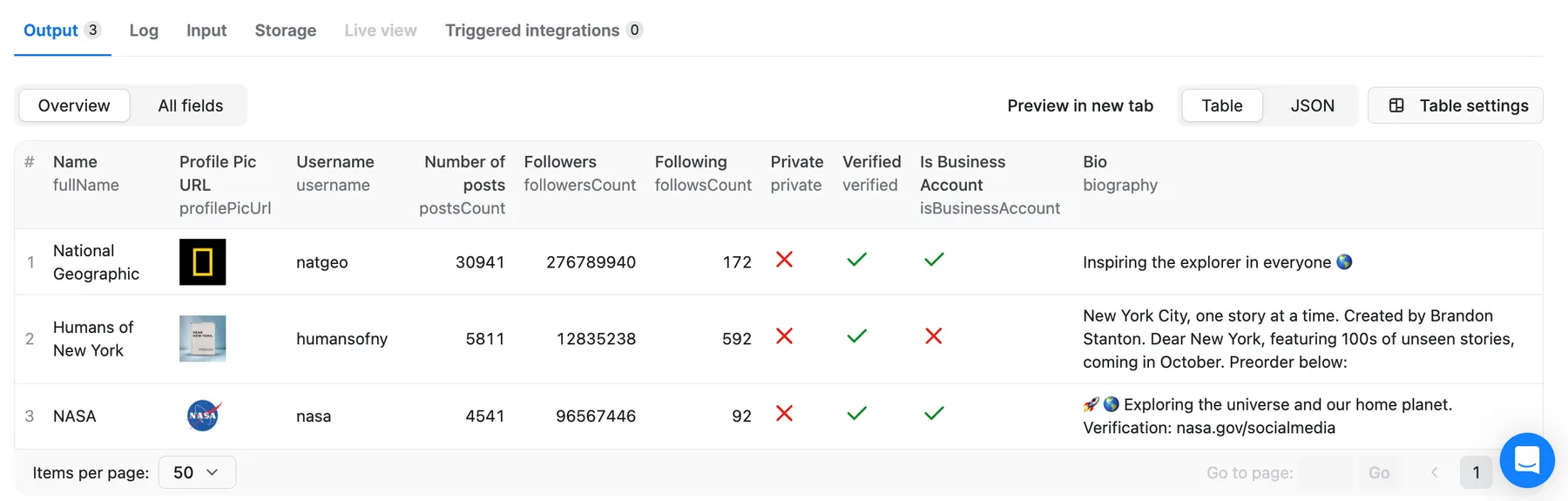
Besides the table view, you can also view your data as JSON, as well as download it as CSV, XML, Excel file, or through an API. Here’s an abridged version of the output for NASA’s profile.
👤 Extracted Instagram Profile data sample
You can export the data in common formats such as JSON, XML, CSV, or Excel. The JSON sample below is shortened for easier viewing. For details about extensive profile dataset, check the ❓FAQ.
Want to get other details from an Instagram account?
You can use the other dedicated scrapers below if you want to scrape specific Instagram data:
If you're comfortable with more complex settings, use our more advanced 🔗 Instagram Scraper or 🔗 Instagram API Scraper. They cover almost all functionalities of the dedicated scrapers.
❓FAQ
What's the expected size of the Instagram Profile dataset?
Note that the dataset can become extensive due to sections like relatedProfiles, latestPosts, and latestIgtvVideos. If you only need key metrics and contact information from scraped Instagram profiles, you can exclude these fields in Storage > Dataset > Export dataset > Omit fields.
What if I only need very basic profile info from Instagram account?
In case you need to scrape only basic profile info, such as followers count, following count, and the last time the account posted, you can use 👥 Instagram Followers Count Scraper. It is more optimized for a specific use case like this.
Can I get Instagram details by username?
Yes. All you need is the profile’s username, and the scraper will fetch all available public data from that account. This includes metrics like followers, follows, posts, engagement, and profile contact details, so you don’t need anything more than the username to start.
Can I get Instagram details by URL or ID?
Yes. Simply provide the profile’s URL or ID, and the scraper will extract the same set of public data as it would with a username. Using URLs can be especially handy if you already have a list of Instagram profiles from another source and want to process them directly.
Is it legal to scrape Instagram profiles?
Our Instagram scrapers do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly.
However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping.
Can I use integrations with Instagram Profile Scraper?
You can integrate profile data scraped from Instagram with almost any cloud service or web app. We offer integrations with Zapier, n8n, Slack, Make, Airbyte, Gumloop, CrewAI, IFTTT, Lindy, GitHub, Google Sheets, Google Drive, and plenty more.
Alternatively, you could use webhooks to carry out an action whenever an event occurs, such as getting a notification whenever the Instagram Profile Scraper successfully finishes a run.
Can I use this Instagram data extractor with the Apify API?
Yes. The Apify API gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify Actors. Meaning the API will let you access any datasets, monitor actor performance, fetch scraped profile results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package. Check out the Apify API reference docs for all the details.
Can I get Instagram account details through an MCP Server?
With Apify API, you can use almost any Actor in conjunction with an MCP server. You can connect to the MCP server using clients like ClaudeDesktop and LibreChat, or even build your own. Read all about how you can set up Apify Actors with MCP.
For Instagram Profile Scraper, go to the MCP tab and then go through the following steps:
- Start a Server-Sent Events (SSE) session to receive a
sessionId - Send API messages using that
sessionIdto trigger the scraper - The message starts the Instagram Profile Scraper with the provided input
- The response should be:
Accepted
Instagram Profile Scraper not working
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for Instagram Profile Scraper or simply found a bug, please create an issue on the Actor’s Issues tab.
