GPT Scraper
Pricing
$9.00 / 1,000 pages
GPT Scraper

Extract data from any website and feed it into GPT via the OpenAI API. Use ChatGPT to proofread content, analyze sentiment, summarize reviews, extract contact details, and much more.
4.4 (7)
Pricing
$9.00 / 1,000 pages
96
Total users
5.8k
Monthly users
176
Runs succeeded
>99%
Issue response
3.2 days
Last modified
4 months ago
GPT Scraper is a powerful tool that leverages OpenAI's API to modify text obtained from a scraper. You can use the scraper to extract content from a website and then pass that content to the OpenAI API to make the GPT magic happen.
How does GPT Scraper work?
The scraper first loads the page using Playwright, then it converts the content into markdown format and asks for GPT instructions about markdown content.
If the content doesn't fit into the GPT limit, the scraper will truncate the content. You can find the message about truncated content in the log.
How much does it cost?
GPT Scraper costs $0.009 per processed page. This price also includes the cost of the OpenAI API. A free Apify account gives you $5 free usage credit each month, so you can scrape up to 555 pages for free.
Extended version
If you are looking for a more powerful GPT Scraper that lets you select the GPT model you want to use and provides more features, check out Extended GPT Scraper.
How to use GPT Scraper
To get started with GPT Scraper, you need to set up the pages you want to scrape using Start URLs and then set up instructions on how the GTP scraper should handle each page. For instance, using a simple scraper to load the URL https://news.ycombinator.com/ and instructing GPT to extract information from it will look like this:
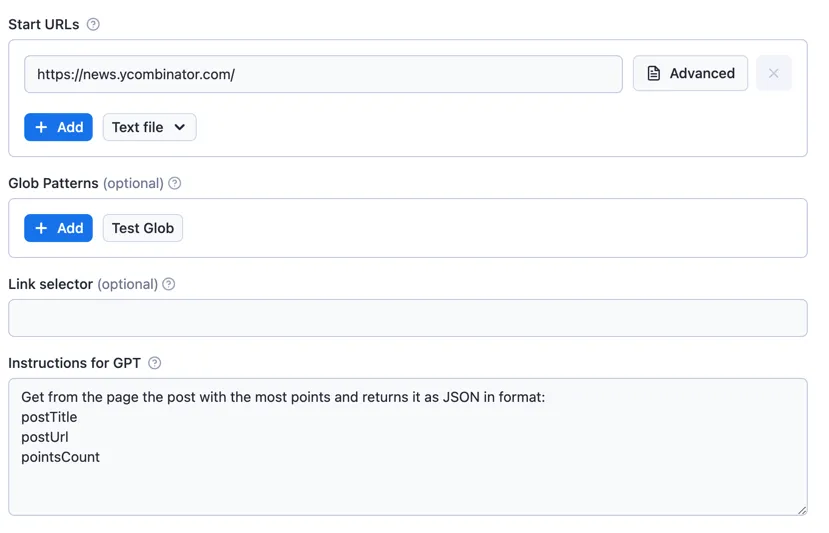
You can configure the scraper and GPT using Input configuration to set up a more complex workflow. You can also follow this video for guidance:
Input configuration
GPT Scraper accepts a number of configuration settings. These can be entered either manually in the user interface in Apify Console or programmatically in a JSON object using the Apify API. For a complete list of input fields and their types, please see the outline of the Actor's Input-schema.
Start URLs
The Start URLs (startUrls) field represents the initial list of page URLs that the scraper will visit. You can enter a group of URLs together using file upload or one by one.
The scraper supports adding new URLs to scrape on the fly, either using the Link selector and Glob patterns options.
Link selector
The Link selector (linkSelector) field contains a CSS selector that is used to find links to other web pages (items with href attributes, e.g. <div class="my-class" href="...">).
On every page that is loaded, the scraper looks for all links matching Link selector, and checks that the target URL matches one of the Glob patterns. If it is a match, it then adds the URL to the request queue so that it's loaded by the scraper later on.
If Link selector is empty, the page links are ignored, and the scraper only loads pages specified in Start URLs.
Glob patterns
The Glob patterns (globs) field specifies which types of URLs found by Link selector should be added to the request queue.
A glob pattern is simply a string with wildcard characters.
For example, a glob pattern http://www.example.com/pages/**/* will match all the
following URLs:
http://www.example.com/pages/deeper-level/pagehttp://www.example.com/pages/my-awesome-pagehttp://www.example.com/pages/something
Instructions and prompts for GPT
This option tells GPT how to handle page content. For example, you can send the following prompts:
- "Summarize this page in three sentences."
- "Find a sentences that contain 'Apify Proxy' and return them as a list."
You can also instruct OpenAI to answer with "skip this page" if you don't want to process all the scraped content, e.g.
- "Summarize this page in three sentences. If the page is about proxies, answer with 'skip this page'.".
Max crawling depth
This specifies how many links away from the Start URLs the scraper will descend.
This value is a safeguard against infinite crawling depths for misconfigured scrapers.
Max pages per run
The maximum number of pages that the scraper will open. 0 means unlimited.
Formatted output
If you want to get data in a structured format, you can define JSON schema using the Schema input option and enable the Use JSON schema to format answer option.
This schema will be used to format data into a structured JSON object, which will be stored in the output in the jsonAnswer attribute.
Proxy configuration
The Proxy configuration (proxyConfiguration) option enables you to set proxies.
The scraper will use these to prevent its detection by target websites.
You can use both Apify Proxy and custom HTTP or SOCKS5 proxy servers.
Limits
The GPT model itself has a limit on the amount of content it can handle (i.e. maximum token limit). The scraped content will be truncated when this limit is reached. If you are looking for a more powerful version that lets you use more than 4096 tokens, you can check out Extended GPT Scraper.
Tips & tricks
Here are a few hidden features that you might find helpful.
Skip pages from the output
You can skip pages from the output by asking GPT to answer with skip this page, for example:
- "Summarize this page in three sentences. If the page is about proxies, answer with 'skip this page'.".
Structured data answer with JSON [DEPRECATED]
Deprecated: Use Schema input option instead.
You can instruct GPT to answer with JSON, and the scraper under the hood will parse this JSON and store it as a structured answer, for example:
- "Find all links on this page and return them as JSON. There will be one attribute,
links, containing an array of URLs."
Example usage
Here are some example use cases that you can use as a starting point for your own GPT scraping experiments.
Summarize a page
Start URL:
Instructions for GPT:
Results:
Extract keywords from a blog post
Start URL:
Prompt for GPT
Extract keywords from this blog post.
Results:
Summarize reviews of movies, games, or products
Start URL:
Instructions for GPT:
Results:
Find contact details on a web page
Start URL:
Instructions for GPT:
Results:
Other suggested use cases
- Find typos and grammatical errors across your entire website
- Analyze competing content to find keywords or ideas
- Examine code examples in content to find errors or suggest improvements