OpenAI Vector Store Integration
Pricing
Pay per usage
OpenAI Vector Store Integration
This integration uploads data from Apify Actors to the OpenAI Vector Store linked to OpenAI Assistant.
Pricing
Pay per usage
Rating
4.8
(5)
Developer
Jiří Spilka
Maintained by CommunityActor stats
15
Bookmarked
224
Total users
13
Monthly active users
18 days ago
Last modified
Categories
Share
OpenAI Vector Store Integration (OpenAI Assistant)
![]()

The Apify OpenAI Vector Store integration uploads data from Apify Actors to the OpenAI Vector Store (connected to the OpenAI Assistant). It assumes that you have already created a OpenAI Vector Store and you need to regularly update the files to provide up-to-date responses.
💡 Note: This Actor is meant to be used together with other Actors' integration sections. For instance, if you are using the Website Content Crawler, you can activate Vector Store Files integration to save web content (including docx, pptx, pdf and other files) for your OpenAI assistant.
Is there anything you find unclear or missing? Please don't hesitate to inform us by creating an issue.
You can easily run the OpenAI Vector Store Integration at the Apify Platform.
Read a detailed guide in the documentation or in blogpost How we built an enterprise support assistant using OpenAI and the Apify platform.
֎ How does OpenAI Assistant Integration work?
Data for the Vector Store and Assistant are provided by various Apify actors and can include web content, Docx, Pdf, Pptx, and other files.
The following image illustrates the Apify-OpenAI Vector Store integration:
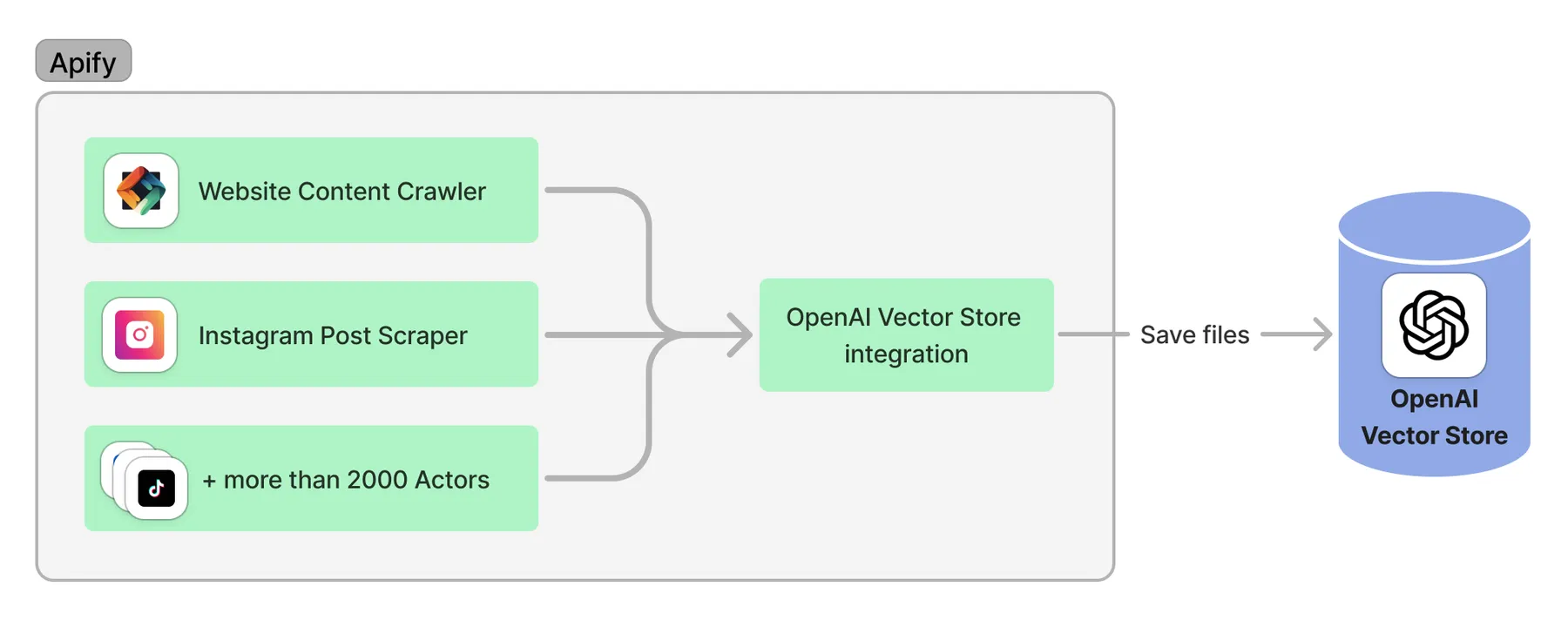
The integration process includes:
- Loading data from an Apify Actor
- Processing the data to comply with OpenAI Assistant limits (max. 1000 files, max 5,000,000 tokens)
- Creating OpenAI Files
- [Optional] Removing existing files from the Vector Store (specified by
fileIdsToDeleteand/orfilePrefix) - Adding the newly created files to the vector store.
- [Optional] Deleting existing files from the OpenAI files (specified by
fileIdsToDeleteand/orfilePrefix)
💰 How much does it cost?
Find the average usage cost for this actor on the pricing page under the Which plan do I need? section.
Additional costs are associated with the use of OpenAI Assistant. Please refer to their pricing for details.
Since the integration is designed to upload entire dataset as a OpenAI file, the cost is minimal, typically less than $0.01 per run.
✅ Before you start
To use this integration, ensure you have:
- An OpenAI account and an
OpenAI API KEY. Create a free account at OpenAI. - Created an OpenAI Vector Store. You will need
vectorStoreIdto run this integration. - [Optional] Created an OpenAI Assistant.
➡️ Inputs
Refer to input schema for details.
vectorStoreId- OpenAI Vector Store IDopenaiApiKey- OpenAI API keyassistantId: The ID of an OpenAI Assistant. This parameter is required only when a file exceeds the OpenAI size limit of 5,000,000 tokens (as of 2024-04-23). When necessary, the model associated with the assistant is utilized to count tokens and split the large file into smaller, manageable segments.datasetFields- Array of datasetFields you want to save, e.g.,["url", "text", "metadata.title"].filePrefix- Delete and create files using a filePrefix, streamlining vector store updates.fileIdsToDelete- Delete specified file IDs from vector store as needed.datasetId: [Debug] Apify's Dataset ID (when running Actor as standalone without integration).keyValueStoreId: [Debug] Apify's Key Value Store ID (when running Actor as standalone without integration).saveInApifyKeyValueStore: [Debug] Save all created files in the Apify Key-Value Store to easily check and retrieve all files (this is typically used when debugging)
⬅️ Outputs
This integration saves selected datasetFields from your Actor to the OpenAI Assistant and optionally to Actor Key Value Storage (useful for debugging).
💾 Save data from Website Content Crawler to OpenAI Vector Store
To use this integration, you need an OpenAI account and an OpenAI API KEY.
Additionally, you need to create an OpenAI Vector Store (vectorStoreId).
The Website Content Crawler can deeply crawl websites and save web page content to Apify's dataset.
It also stores files such as PDFs, PPTXs, and DOCXs.
A typical run crawling https://platform.openai.com/docs/assistants/overview includes the following dataset fields (truncated for brevity):
Once you have the dataset, you can store the data in the OpenAI Vector Store.
Specify which fields you want to save to the OpenAI Vector Store, e.g., ["text", "url"].
🔄 Update existing files in the OpenAI Vector Store
There are two ways to update existing files in the OpenAI Vector Store.
You can either delete all files with a specific prefix or delete specific files by their IDs.
It is more convenient to use the filePrefix parameter to delete and create files with the same prefix.
In the first run, the integration will save all the files with the prefix openai_assistant_.
In the next run, it will delete all the files with the prefix openai_assistant_ and create new files.
The settings for the integration are as follows:
📦 Save Amazon Products to OpenAI Vector Store
You can also save Amazon products to the OpenAI Vector Store.
Again, you need to have an OpenAI account and an OpenAI API KEY with a created OpenAI Vector Store (vectorStoreId).
To scrape Amazon products, you can use the Amazon Product Scraper Actor.
Let's say that you want to scrape "Apple Watch" and store all the scraped data in the OpenAI Assistant.
For the product URL https://www.amazon.com/s?k=apple+watch, the scraper can yield the following results (truncated for brevity):
You can easily save the data to the OpenAI Vector Store by creating an integration (in the Amazon Product Scraper integration section) and specifying the fields you want to save:
ⓘ Limitations
- Crawled files, such as PDFs, PPTXs, and DOCXs, are saved in the OpenAI Vector Store as single files and uploaded one by one. While this approach is inefficient, it allows for better error handling and the ability to log detailed error messages.
- OpenAI can process text-based PDF files but cannot handle PDF images or scanned PDFs. For the latter, you need to use OCR to extract text from images.


