Jooble Jobs Search Scraper
Pricing
$20.00/month + usage
Jooble Jobs Search Scraper
Extract thousands of Jooble job listings instantly with our automated scraper. Get structured data including salaries, locations, company details, and requirements exported directly to JSON, CSV, or Excel. Built for recruiters, HR teams, and market analysts who need reliable job market intelligence.
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
21
Total users
1
Monthly active users
8 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
What Can Jooble Jobs Search Scraper Do?
Introduction
Jooble.org stands as one of the world's leading job search platforms, operating as a global product-based IT company across 69 countries with over 90 million monthly users. Since 2006, this comprehensive employment platform has been aggregating job openings from more than 140,000 sources worldwide, making it an invaluable resource for recruitment professionals, job seekers, and market researchers.
The Jooble Jobs Search Scraper addresses the critical need for automated job data extraction from this massive repository. With over 540,000 current vacancies spanning full-time, part-time, and temporary positions, manually collecting this data would be virtually impossible. This scraper transforms hours of manual research into minutes of automated data collection, providing structured access to one of the internet's largest job databases.
Scraper Overview
The Jooble Jobs Search Scraper is a sophisticated data extraction tool designed specifically for harvesting job posting information from Jooble's extensive database. This scraper excels at collecting detailed job information including position details, salary ranges, company information, location data, and job-specific attributes that are crucial for recruitment analytics and market research.
Key strengths of this scraper include its ability to handle Jooble's complex page structure, extract both visible and metadata information, and organize the output into a comprehensive format suitable for analysis. The tool is particularly valuable for recruitment agencies, HR departments, job aggregation services, and market researchers who need large-scale access to employment data.
The scraper is designed for professionals who require systematic job data collection, including talent acquisition specialists, competitive analysts, salary researchers, and employment market analysts. Its robust architecture ensures reliable data extraction while respecting website performance and terms of service.
Input and Output Details
Example url 1: https://jooble.org/jobs/Houston%2C-TX?p=5
Example url 2: https://jooble.org/SearchResult?rgns=Los%20Angeles%2C%20CA
Example url 3: https://jooble.org/SearchResult?rgns=Huntsville%2C%20AL
Example Screenshot of jobs information page:
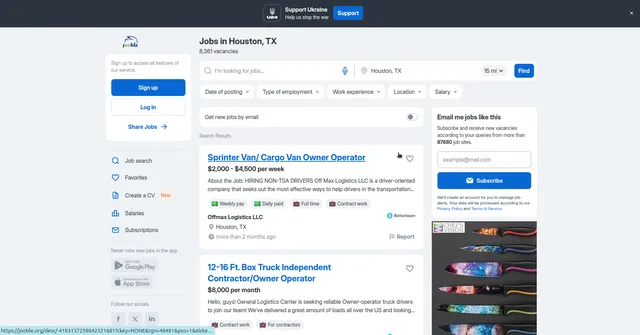
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of job listing page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find jobs (e.g., "software engineer", "accountant", "nurse", "manager").
The region parameter: Enter the location/region to search for jobs (e.g., "Houston, TX", "New York, NY", "Los Angeles, CA").
The posted_date parameter: Filter jobs by posting date:
""- All time"8"- Last 24 hours"2"- Last 3 days"3"- Last 7 days
The salary_min parameter: Filter jobs by minimum salary (annual):
""- Any salary"30000"- Higher than $30,000"50000"- Higher than $50,000"80000"- Higher than $80,000"100000"- Higher than $100,000"150000"- Higher than $150,000
The job_type parameter: Filter jobs by employment type:
"1"- Full-time"2"- Temporary"3"- Part-time
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of job listings extracted from each listing page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., US for jooble.org).
Output Format
You get the output from the Jooble Jobs Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The scraper generates a comprehensive dataset with 25+ fields for each job posting, providing extensive information for analysis:
Core Identification Fields:
UID: Unique identifier for database management and duplicate preventionURL: Direct link to the original job posting for verification and applicationDate Caption: Human-readable posting date as displayed on JoobleDate Updated: Timestamp indicating when the job was last modified
Compensation Information:
Salary: Posted salary information when availableEstimated Salary: Algorithm-generated salary estimates for positions without posted ranges
Job Content:
Content: Condensed job description with key detailsFull Content: Complete job description including all requirements and benefitsPosition: Exact job title as posted by the employer
Job Attributes:
Is New: Boolean indicating recently posted positionsIs Premium: Identifies premium or featured job listingsIs Easy Apply: Flags positions with simplified application processesIs Remote Job: Indicates remote work opportunitiesIs Resume Required: Specifies if resume submission is mandatoryIs Advert Label: Identifies sponsored or advertising contentIs Favorite: User interaction data (when available)
Company and Location:
Company: Employer name and branding informationLocation: Geographic job location with city/state/country detailsDestination: Specific work location or multiple location indicatorsProject Logo URL: Company branding assets for enhanced presentation
Application Intelligence:
Has Few Applies: Competitive advantage indicator for applicantsHas Questions: Indicates pre-screening questions in application processJob Type: Employment classification (full-time, part-time, contract, etc.)
Advanced Categorization:
Tags: Industry and skill-based categorization labelsHighlight Tags: Special emphasis tags for standout qualificationsIs DTE Job: Direct-to-employer posting classificationMatching: Relevance scoring for search queriesFitly Job Card: Enhanced presentation format indicators
Data Management:
Is Deleted: Status tracking for removed postings
Usage Guide
Step 1: Choose Your Scraping Approach
Option A - URL-Based Preparation: Navigate to Jooble.org and perform your desired job search using the website's search and filtering features. Copy the complete resulting URLs, ensuring they include proper location and search parameters. Multiple URLs can be processed simultaneously for comprehensive data collection.
Option B - Filter-Based Preparation: Define your search criteria using the built-in filters:
- Set
keywordfor specific job titles or roles (e.g., "software engineer", "nurse", "accountant") - Enter
regionto target specific locations (e.g., "Houston, TX", "New York, NY") - Select
posted_dateto filter by job posting recency (24 hours, 3 days, 7 days) - Choose
salary_minto set minimum salary requirements ($30k, $50k, $80k, $100k, $150k+) - Select
job_typeto filter by employment type (full-time, part-time, temporary)
Step 2: Configuration Setup
Configure proxy settings to match your target geographic region (US recommended for Jooble.org) for optimal data access. Set appropriate retry limits (max_retries_per_url) and item counts (max_items_per_url) based on your data volume requirements and time constraints. Enable ignore_url_failures for robust scraping.
Step 3: Execution Monitoring Launch the scraper and monitor progress through the provided dashboard. The tool handles pagination automatically and provides real-time status updates on data collection progress.
Step 4: Data Processing Review the extracted data for completeness and accuracy. The structured output format facilitates easy import into analytical tools, databases, or visualization platforms.
Best Practices:
Method Selection:
- Use URL-based scraping for complex search queries with multiple filters or specific geographic targeting
- Use filter-based scraping for simpler keyword searches with standard filtering options
- Combine both approaches: use filters for broad job discovery, then URLs for targeted deep dives
Scraping Strategy:
- Use US residential proxies for improved success rates and reduced blocking
- Implement reasonable delays between requests to avoid overwhelming the target server
- Regularly update your input URLs or refresh filter-based searches to capture fresh job postings
- Monitor for changes in Jooble's page structure that might affect extraction accuracy
Filter Optimization:
- Location Strategy: Use specific cities/states in
regionfor targeted local job markets - Recency Filtering: Use
posted_date: "8"(24 hours) for real-time job tracking, or"3"(7 days) for weekly analysis - Salary Analysis: Combine
salary_minwithkeywordto analyze compensation trends by role - Job Type Segmentation: Use
job_typeto separate full-time, part-time, and temporary opportunities
Advanced Filter Combinations:
- Entry-level jobs:
keyword: "junior developer", salary_min: "50000", job_type: "1" - High-paying roles:
keyword: "senior", salary_min: "150000", job_type: "1", region: "San Francisco, CA" - Recent postings:
keyword: "nurse", posted_date: "8", region: "Houston, TX" - Contract work:
keyword: "consultant", job_type: "2", salary_min: "80000" - Part-time opportunities:
keyword: "customer service", job_type: "3", region: "New York, NY"
Common Issues:
CAPTCHA Challenges:
- Adjust proxy settings to use residential IPs
- Reduce request frequency and implement delays
- Enable
ignore_url_failuresto continue despite some failures
Incomplete Data Extraction:
- For URL-based: Verify URL formats are correct and include all necessary parameters
- For filter-based: Test filter combinations with broader criteria
- Ensure stable internet connectivity
- Increase
max_retries_per_urlto 3-5 for better reliability
Empty Results:
- For filter-based: Verify keyword spelling and try broader terms
- Test different
regionvalues if location seems too specific - Adjust
salary_minto be more inclusive - Try removing some filters to broaden search scope
Geographic Issues:
- Ensure
regionformat matches Jooble's expected format (e.g., "Houston, TX" not "Houston Texas") - Use US proxies for better access to US job listings
- Test region-specific searches separately to identify issues
Salary Filter Issues:
- Verify
salary_minvalues match available options ("30000", "50000", "80000", "100000", "150000") - Note that salary filtering may exclude jobs without listed salaries
- Try searches without salary filters first, then add progressively
Date Filter Strategy:
- Use
posted_date: "8"for daily job monitoring - Use
posted_date: "2"for catching recent opportunities - Use
posted_date: "3"for weekly job market analysis - Leave empty for comprehensive historical data
Market Research Use Cases:
- Salary Benchmarking: Use combinations of
keyword + region + salary_minto analyze compensation by location - Job Market Trends: Track
posted_date: "8"over time to monitor hiring activity - Geographic Analysis: Compare job availability across different
regionfilters - Employment Type Analysis: Use
job_typeto analyze full-time vs contract market trends
Benefits and Applications
The Jooble Jobs Search Scraper delivers significant time savings by automating what would otherwise require hundreds of hours of manual data collection. Instead of visiting individual job pages and copying information by hand, users can extract comprehensive job market data in minutes.
Business Applications: Recruitment agencies can build comprehensive candidate databases and track market trends across multiple locations and industries. HR departments can conduct competitive salary analysis and monitor hiring patterns in their sectors. Market researchers can analyze employment trends, skill demand patterns, and geographic job distribution.
Strategic Advantages: The tool enables real-time monitoring of job market conditions, helping organizations make data-driven hiring decisions. Companies can track competitor hiring activities, identify emerging skill requirements, and adjust their recruitment strategies based on market intelligence.
Conclusion
The Jooble Jobs Search Scraper represents a powerful solution for automated job data extraction from one of the world's largest employment platforms. With its comprehensive output format and robust configuration options, this tool transforms manual job research into systematic data collection that supports strategic business decisions.
Whether you're conducting market research, building recruitment databases, or analyzing employment trends, this scraper provides the reliable, scalable solution needed to access Jooble's extensive job repository efficiently. Start leveraging this tool today to gain competitive advantages in talent acquisition and market analysis.
Related Actors
- Jooble Jobs Details Scraper: Your comprehensive tool for extracting valuable business information from Yell extensive directory platform.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Jooble Jobs Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.