Incremental Web Crawler
Pricing
$10.00/month + usage
Incremental Web Crawler
The Incremental Crawler efficiently fetches URLs of recently added or updated web pages on a target site, optimizing resources by focusing only on new content. Ideal for keeping up with the latest updates, it integrates seamlessly into workflows for content monitoring and analysis.
Pricing
$10.00/month + usage
Rating
0.0
(0)
Developer
AIRabbit
Maintained by CommunityActor stats
4
Bookmarked
42
Total users
0
Monthly active users
2 years ago
Last modified
Categories
Share
Apify Incremental Link Crawler for Recent Web Pages
Are you frustrated by the time, money, and resources wasted on repeatedly crawling entire websites just to track a few new or updated pages? The majority of websites undergo minimal changes between crawls, yet you are required to process the same outdated content repeatedly, which results in the inefficient use of resources and a more complex workflow.
The Incremental Crawler eliminates the need for this process. This tool identifies the most recent pages, automatically detecting new or updated content and integrating it directly into your workflow. Instead of re-evaluating the entire content set, your process focuses on a small fraction of the content, significantly reducing costs and processing time. You can now run your crawls more frequently and obtain up-to-date data with minimal delay—typically within a day. Keep your information pipeline fresh and efficient without the hassle of redundant crawls.
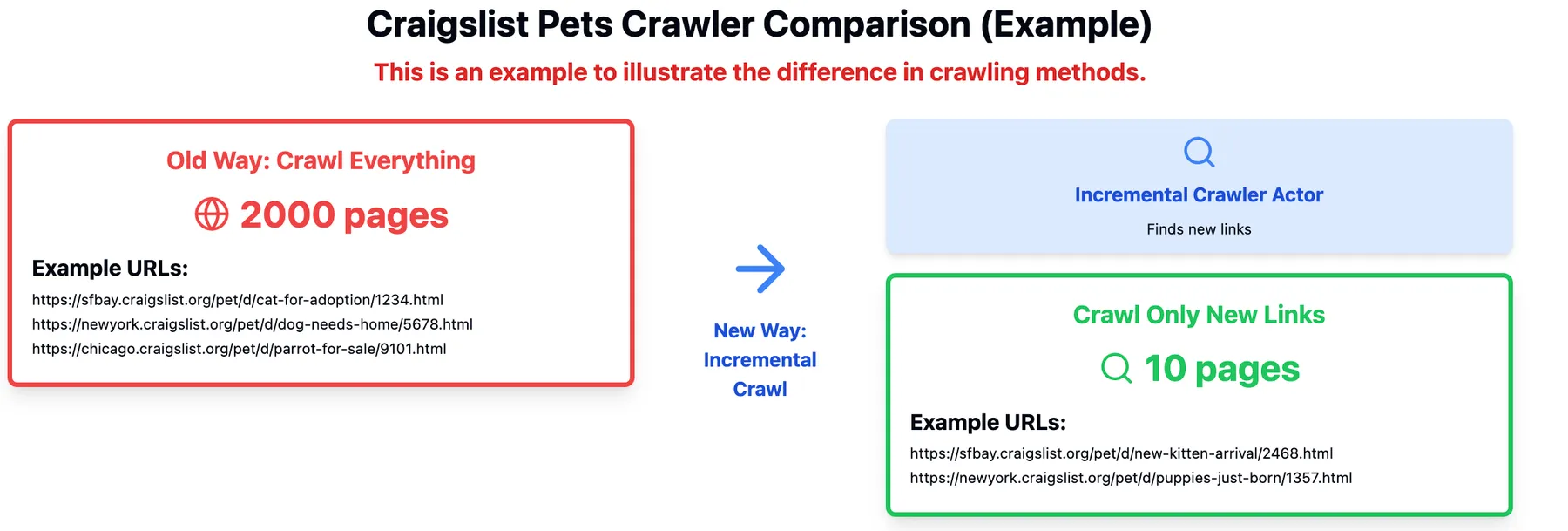 Why Use Incremental Crawler?
Why Use Incremental Crawler?
- Efficient: The actor scans any website for recent updates, saving users time and resources.
- Cost-saving: By handling less data, Apify reduces your computing and storage costs, both online and offline. This eliminates the need to process large amounts of unchanged data, which in turn reduces your overall costs.
- Up-to-date: Keeps you informed about the latest changes on the website.
- Flexible: Its flexibility allows it to integrate seamlessly into other tasks, such as monitoring, indexing, or analyzing content. It can be integrated with minimal disruption to existing workflows.
How It Works
- Enter the Website URL and Time Frame: Provide the URL of the website and specify how many days back you want to check for updates.
- Find New or Updated Pages: The crawler will identify pages that have been added or updated within that time frame.
- Receive a List of URLs: You'll get a list of URLs for the newly added or updated pages.
What You Need to Provide
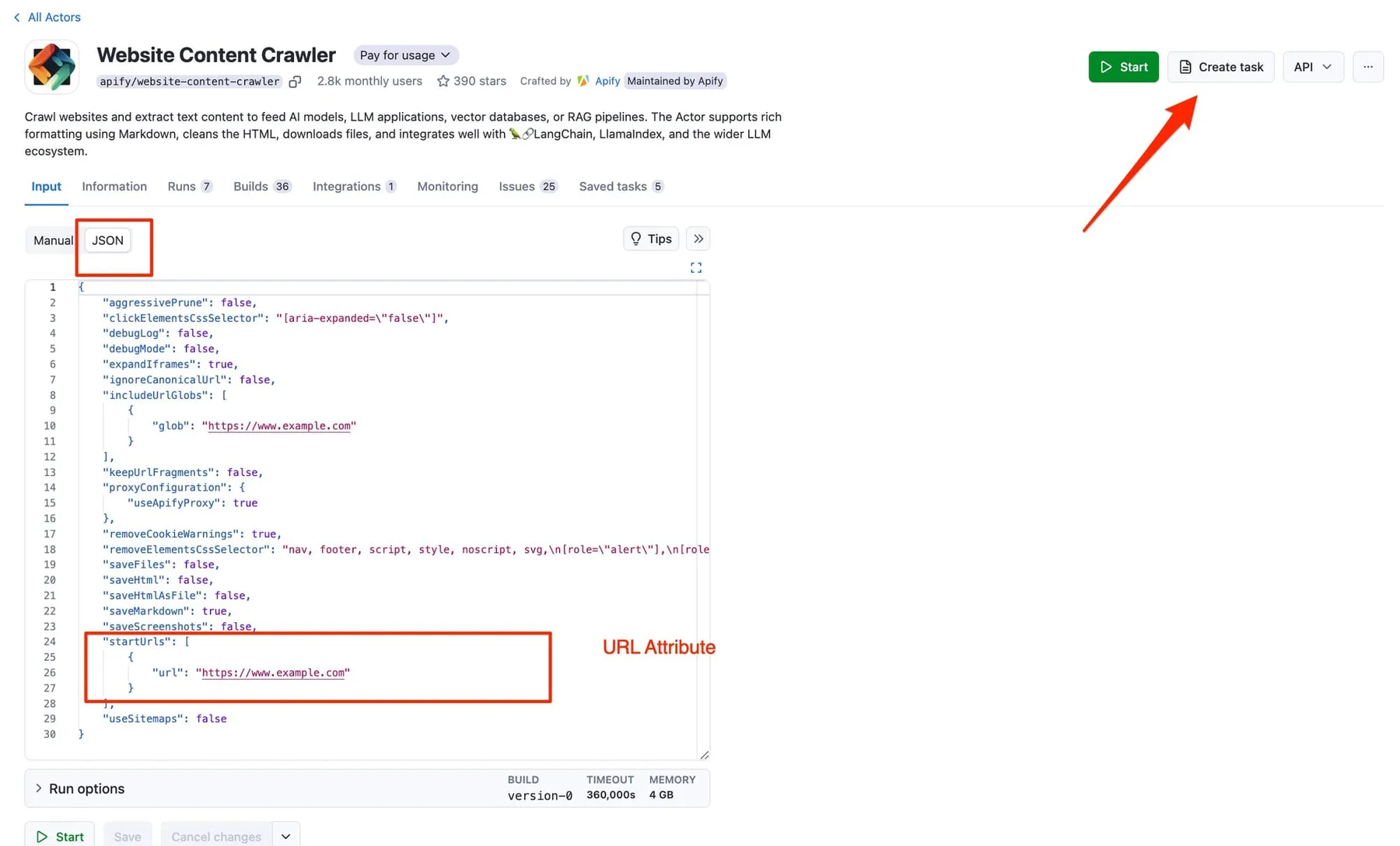
- URL: The website you want to monitor.
- Days Ago: How far back you want to look for changes (default is 1 day).
Optional:
- Max Results: The maximum number of URLs you want to get (default is 50).
- Language: The language of the results (default is 'en').
- Country: The country for the search (default is 'us').
- Search Domain: The domain to use for the search (default is 'com').
- Next Run ID: ID for the next task (optional).
- Next Run Attribute: Attribute to update in the next run (default is 'startUrls', optional).
How to Choose the Right URL?
To make the most of this crawler, ask yourself:
"What is the main URL for the section or category I want to monitor?"
The URL should lead directly to a general page for that section, not a search results page.
Example: Craigslist
✅ DO Use this: https://albany.craigslist.org/pet
This URL points to the main "For Sale" section for the San Francisco Bay Area on Craigslist.
Output: https://albany.craigslist.org/pet/d/amsterdam-bulldog-female/7777952367.html https://albany.craigslist.org/pet/d/johnstown-flemish-bunny/7777825167.html https://albany.craigslist.org/pet/d/schenectady-love-birds/7777992864.html https://albany.craigslist.org/pet/d/mechanicville-rehoming-my-babies-luna/7777864880.html https://albany.craigslist.org/pet/d/mechanicville-bichir/7777915783.html https://albany.craigslist.org/pet/d/schenectady-free-kittens/7778024580.html https://albany.craigslist.org/pet/d/herkimer-siberian-husky/7777994168.html https://albany.craigslist.org/pet/d/schenectady-small-animal-enclosure/7777940237.html https://albany.craigslist.org/pet/d/schenectady-small-zilla-enclosure/7777912041.html https://albany.craigslist.org/pet/d/mechanicville-black-arowana/7777916422.html
❌ DON'T use search or listing URLs like:
- https://sfbay.craigslist.org/search/sss?query=pet (a search results URL)
Please Note
- New pages are usually ready for crawling after about a day, sometimes sooner, but this isn't guaranteed.
- The crawler can only reach pages that search engines like Google can see.
- This crawler works well on various sites, but its performance depends on how easily it can be found on search engines. Please test it on your own website before udpating your workflow.
Integrating with other Actors
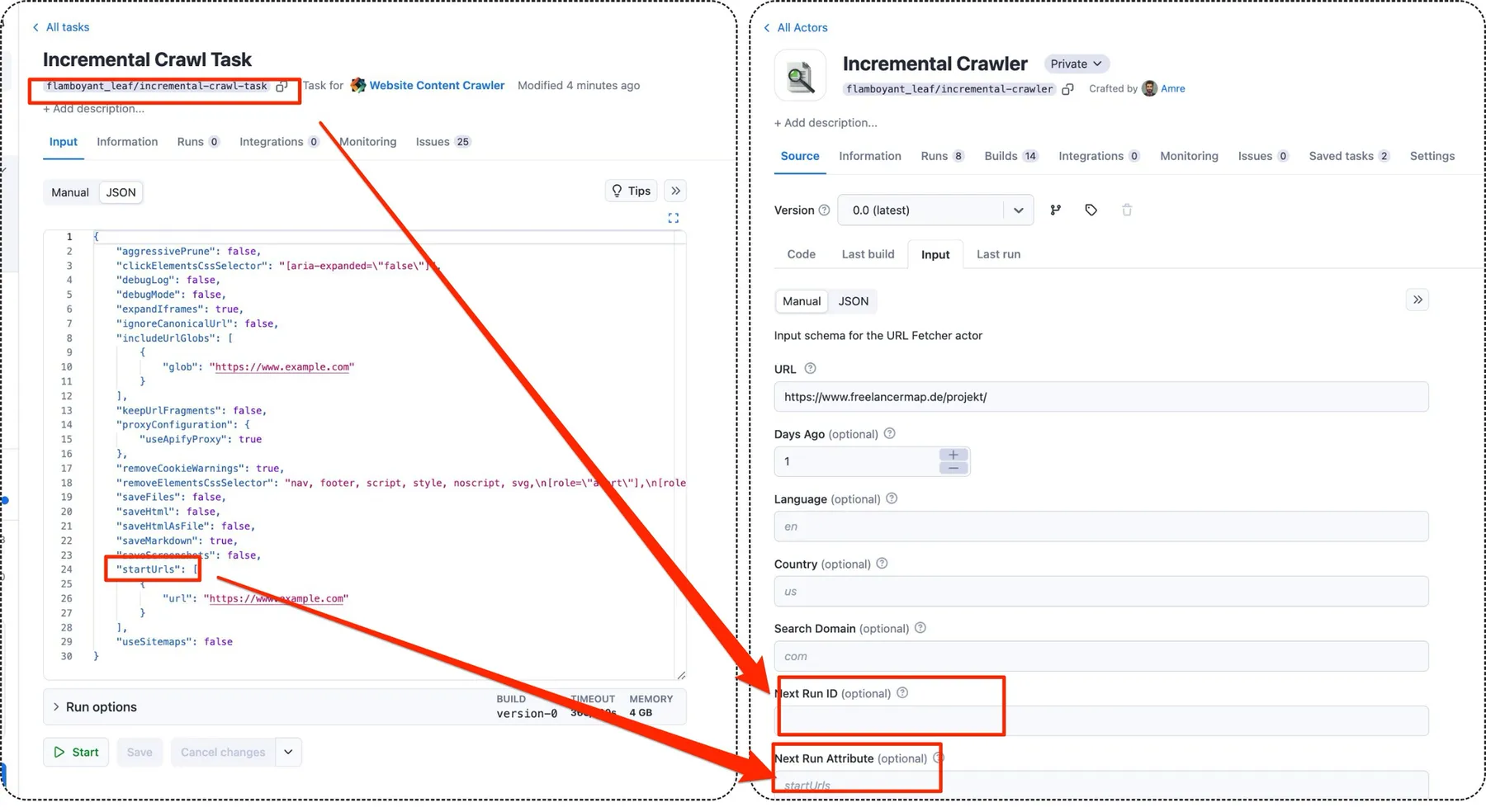
To use the URLs fetched by this crawler in another task:
- Set Up the Next Task: Create a task for the next step in your workflow.
- Configure the Crawler: In the Incremental Crawler's settings, provide the
nextRunId(the ID of the task you created) andnextRunAttribute(usually 'startUrls'). - Automate the Process: The crawler will automatically start the specified task with the fetched URLs.
How can we help?
We're here for you! If you have any questions or need help with anything, please don't hesitate to reach out.
We're always happy to help.


