Google Images Scraper
Pricing
from $2.40 / 1,000 images
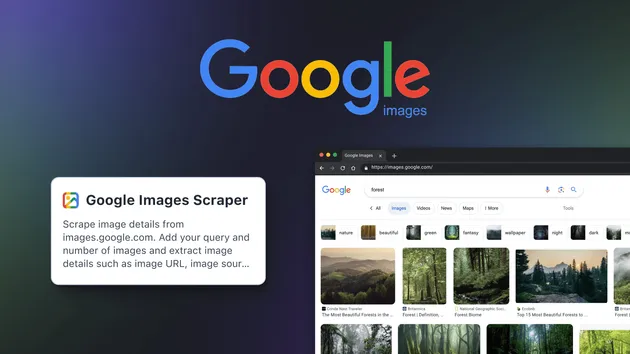
Google Images Scraper

Scrape image details from images.google.com. Add your query and number of images and extract image details such as image URL, image source, description, image dimensions, thumbnail, and more. Export scraped data, run the scraper via API, schedule and monitor runs, or integrate with other tools.
4.2 (8)
Pricing
from $2.40 / 1,000 images
44
Total users
2K
Monthly users
270
Runs succeeded
>99%
Issues response
2.6 days
Last modified
2 months ago
Add an option to download the files to key-value store
Closed
Currently, the Actor only stores links to the images. But that means the users need to implement image downloading and potentially anti-blocking and proxying themselves, which takes an unnecessary extra effort. Let's add flags downloadImages and downloadThumbnails to store the images to the key-value store. Use some hashing for the names to avoid collisions.
We discussed this today on the meeting and agreed that it would be better to intregrate this Actor with a generic image downloader such as: Dataset Image Downloader & Uploader
This way we won't have to implement the downloading logic separately for Google Images Scraper or other actors with image links included in the dataset.
Do you think this solution would be ok?
Hey, yeah that sounds like a good idea. We could add downloader as recommended integration
I've just tested this Actor-to-Actor integration and it works nicely.
The following run of the Dataset Image Downloader & Uploader was triggered with a successful run of Google Images Scraper:
https://console.apify.com/view/runs/MXcJdcN8UC4bsobT2
The images were stored to the named KVS downloaded-images as individual files but it is also possible to store them in a single ZIP file or into the S3 bucket.
We could add downloader as recommended integration
Definitely, I'm just trying to figure out where can I set this (and what is the correct format). Does it need to be in the Actor's code or can we set it up in the Console?
Cool. The Store team will know how to add this
The suggested integration is set up, see the attached image or Google Images Scraper Integrations directly.
I guess we should update the README as well and mention the possible integration there. We can probably close this Console issue now and leave the README updates for the internal GitHub ticket.
Great, thank you
apify_gpt
Test reply
apify_gpt
One more test hello