XiaoHongShu Scraper
Pricing
$20.00/month + usage
XiaoHongShu Scraper

[小红书](https://www.xiaohongshu.com/) is a famous social e-commerce platform that combines user-generated content with online shopping, catering to the needs of young Chinese consumers.. This scraper can help you to get data from it. 本工具可以处理小红书首页数据及各频道页的数据。
1.0 (1)
Pricing
$20.00/month + usage
7
Total users
281
Monthly users
28
Runs succeeded
>99%
Last modified
5 days ago
It's useful and easy to use. This scraper can help you to get data from https://www.xiaohongshu.com/.
It scrape from page https://www.xiaohongshu.com/
to get data like this
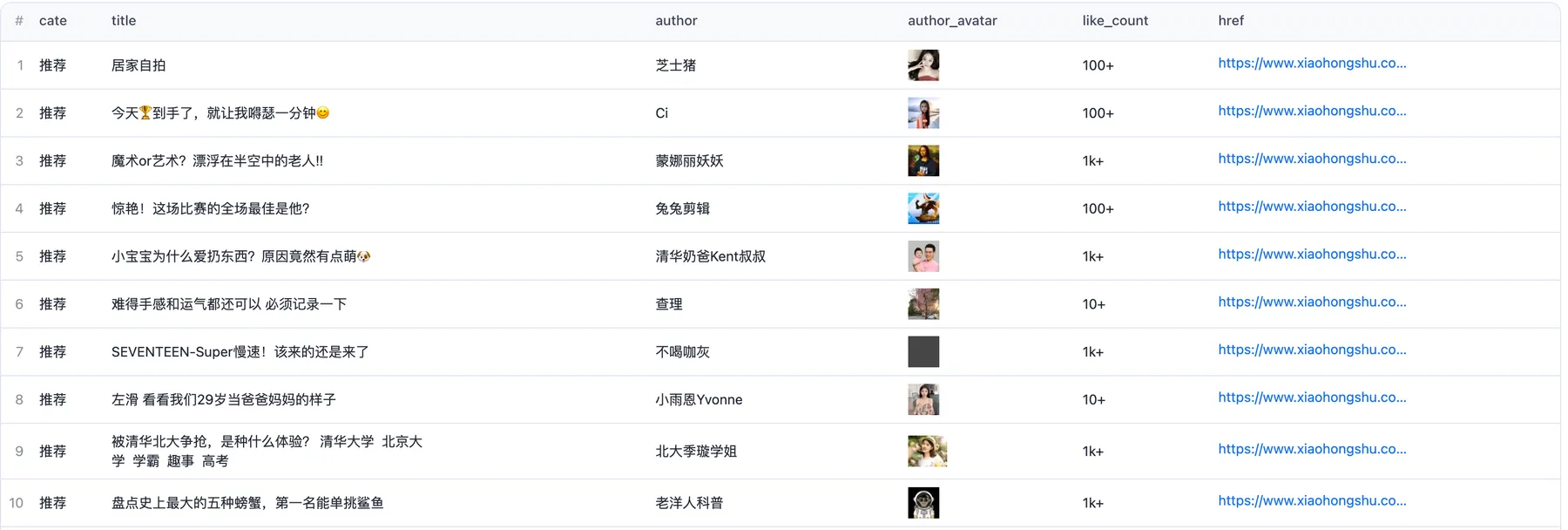
Usage Tips
Based on user feedback, we would like to provide some small suggestions for use, and also recommend that you provide more feedback through issue reports.
-
The only parameter need input is category. You can configure the categories list you want like "cate1,cate2". Or just copy all categories from default value. Just keep in mind, more data cost more (resource, money, time and so on) 必填参数只有 category 信息,格式逗号分隔的分类列表。
-
增加scrape_detail参数,获取帖子的内容。类型,收藏数,回复数,但是会降低抓取速度。Add the scrape_detail parameter to get the content of the post. Type, number of favorites, number of replies, but will slow down the fetching speed.
Features
- Get useful data from page https://www.xiaohongshu.com/


