Amazon Bestsellers Scraper
Pricing
from $3.20 / 1,000 items
Amazon Bestsellers Scraper
Scrape the Amazon Best Sellers categories and extract details on top 100 most popular items on Amazon. Download product name, price, URL, and thumbnail image. Best used on .com, .co.uk, .de, .fr, .es, and .it domains. Download your data in various formats: HTML table, JSON, CSV, Excel, and more.
Pricing
from $3.20 / 1,000 items
Rating
5.0
(10)
Developer
Junglee
Maintained by ApifyActor stats
102
Bookmarked
4.3K
Total users
363
Monthly active users
6.8 days
Issues response
4 days ago
Last modified
Categories
Share
⭐️ What is Amazon Best Sellers Scraper?
This Amazon Best Sellers Scraper allows you to scrape the 100 top-selling items on Amazon. It extracts data from Amazon Best Sellers pages in structured formats such as JSON, XML, CSV, or Excel. With this Amazon API, you will be able to:
- extract data from different domains: US, GB, DE, FR, ES, and IT.
- extract all Amazon Best Seller product details: name, price, URL, and thumbnail image.
- scrape Amazon Best Seller categories and subcategories.
- besides Amazon Best Seller categories, you can now also scrape the following Amazon categories with this scraper: Most Wished, Movers and Shakers, New Releases, and Gift Ideas. For examples of URLs that be scraped, head over to the Input section.
If you would prefer a more general Amazon product data scraper, you should try Amazon Scraper instead.
📚 How do I scrape Amazon Best Sellers?
Amazon Best Sellers Scraper was designed for an easy start even if you've never extracted data from the web before. Here's how you can scrape bestsellers with this tool:
- Create a free Apify account using your email.
- Open Amazon Best Sellers Scraper.
- Add one or more Amazon URLs to scrape product info.
- Click "Start" and wait for the data to be extracted.
- Download your data in JSON, XML, CSV, Excel, or HTML.
For a step-by-step guide on how to scrape Amazon Best Seller products, follow our tutorial.
📦 How many results can you scrape with Amazon Best Seller scraper?
Amazon Best Sellers scraper can return up to tens of thousands of results on average. However, you have to keep in mind that scraping amazon.com has many variables to it and may cause the results to fluctuate case by case. There’s no one-size-fits-all-use-cases number. The maximum number of results may vary depending on the complexity of the input, location, and other factors. Some of the most frequent cases are:
- website gives a different number of results depending on the type/value of the input
- website has an internal limit that no scraper can cross
- scraper has a limit that we are working on improving
Therefore, while we regularly run Actor tests to keep the benchmarks in check, the results may also fluctuate without our knowing. The best way to know for sure for your particular use case is to do a test run yourself.
🎯 Need to do product matching between Amazon and another online shop?
Use the AI Product Matcher. This AI model allows you to compare items from different web stores, identifying exact matches and comparing real-time data obtained via web scraping. With the AI Product Matcher, you can use scraped product data to monitor product matches across the industry, implement dynamic pricing for your website, replace or complement manual mapping, and obtain realistic estimates against your competition for upcoming promo campaigns.
Most importantly, it is relatively easy to get started with (just follow this guide).⬇️
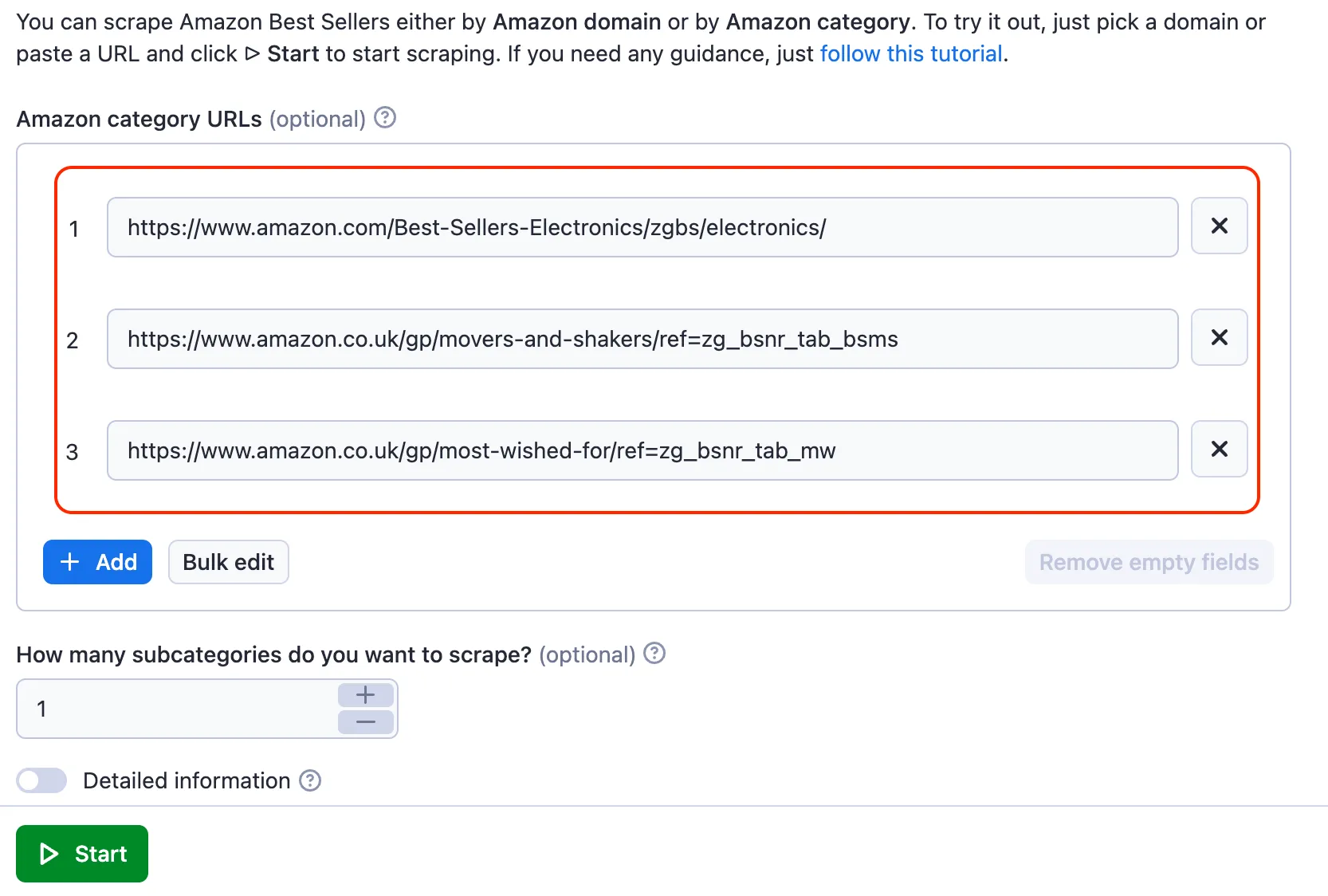
⬇️ Input parameters
You can scrape Amazon Best Sellers by Amazon URLs from 6 different Amazon domains: .com, .de. .co.uk, .fr, .es and .it. You can get all the details from a chosen category and its subcategories. You can add as many URLs as you want.
Here's an input example of acceptable Amazon URLs:
- Best Sellers: https://www.amazon.com/Best-Sellers-Appliances/zgbs/appliances/ref=zg_bs_nav_appliances_0
- Movers and Shakers: https://www.amazon.de/-/en/gp/movers-and-shakers/garden/ref=zg_bsms_nav_garden_0
- New Releases: https://www.amazon.co.uk/gp/new-releases/ref=zg_bsms_tab_bsnr
- Most Wished: https://www.amazon.es/gp/most-wished-for/ref=zg_bs_tab_mw
- Most Gifted: https://www.amazon.fr/gp/most-gifted/books/ref=zg_mg_nav_books_0
⬆️ Output example
The scraped Amazon items will be shown as a dataset which you can find in the Output or Storage tabs. Note that the output will first be organized as a table for viewing convenience:
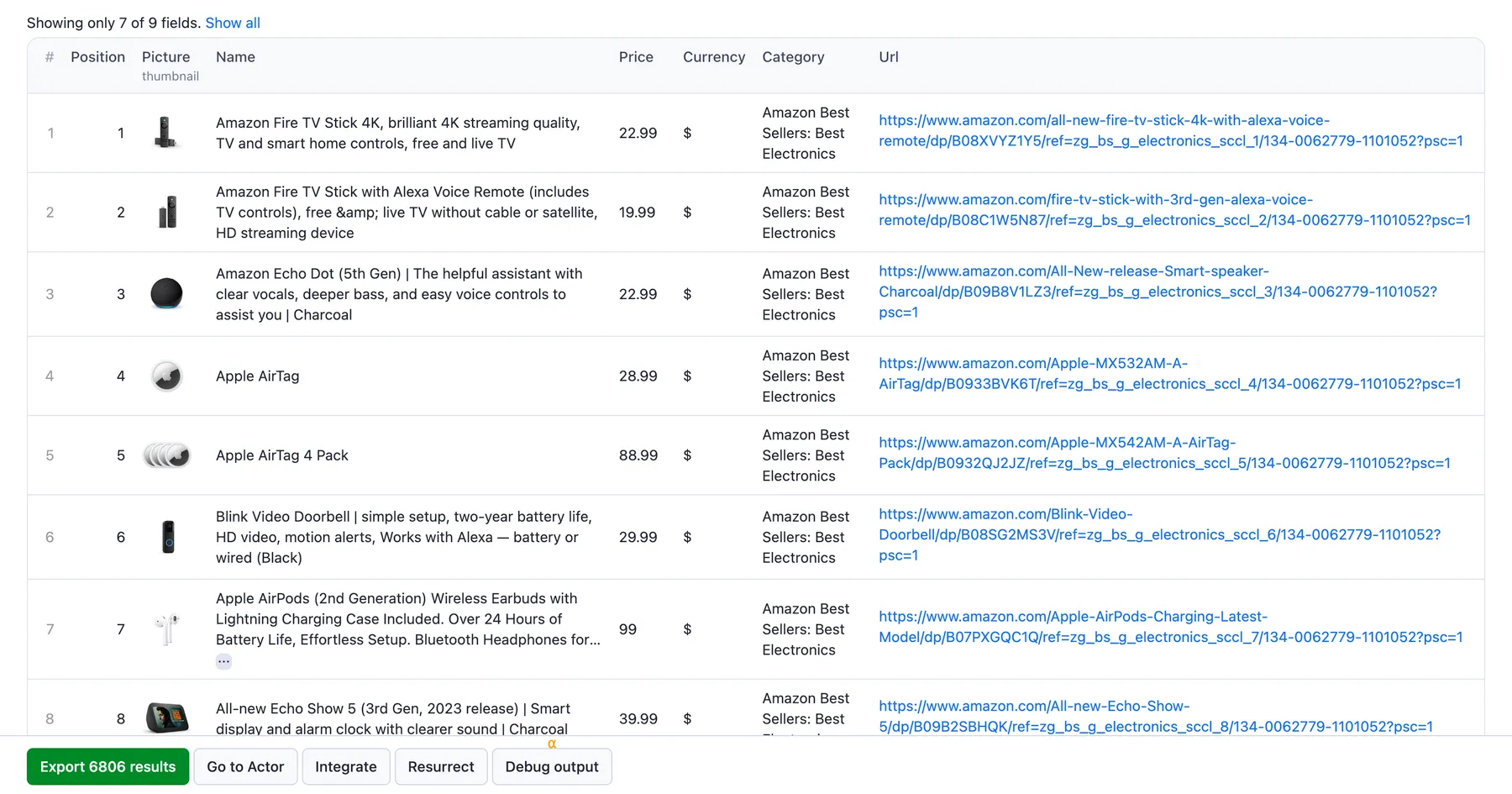
You can preview all the fields and choose in which format to download the data you’ve extracted: JSON, Excel, HTML table, CSV, or XML. Here below is the same dataset in JSON:
☝️ Tips and tricks
- By default, this Amazon scraper extracts the 37 top Best Seller subcategories. A deeper level of extraction can be added to allow you to scrape the top-selling items from the first level of the main categories' sub-divisions.
- The default depth of the crawl is limited to two subcategories. There is a way around this restriction. Start on the main category, scrape two departments. Then remove duplicate category URLs from there and feed them back into the scraper again.
Error items
When the scraper cannot retrieve data for a given input — for example a bestsellers category page does not exist or a start URL is malformed — it pushes an error item to the dataset instead of silently skipping it. Normal output items are never affected; you can tell them apart by the presence of an error field.
Error item structure
Error codes reference
error | Meaning |
|---|---|
invalid_url | One or more start URLs were malformed or not recognized |
invalid_input | Actor failed due to bad configuration (run is also terminated) |
product_not_found | Product URL returns a 404 page |
shortened_url_invalid | Amazon shortened URL could not be resolved |
bestsellers_category_not_found | Bestsellers category page could not be found |
no_relevant_reviews_found | Reviews exist but none match the active filters |
no_results_found | No results were found for the given input |
❓FAQ
Do I need proxies to scrape Amazon?
For the most reliable results of scraping, you will need to use some sort of proxy along with the scraper to prevent its detection by target websites. You can use both Apify Proxy and custom HTTP or SOCKS5 proxy servers.
To engage custom proxies specifically, you will need to specify them in the scheme://user:password@host:port format. Multiple proxies should be separated by a space or new line and the URL scheme can be either HTTP or SOCKS5. User and password might be omitted, but the port must always be present.
Can I integrate Amazon Best Sellers Scraper with other apps?
Yes. Amazon Best Sellers can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Make, Zapier, LangChain, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and more.
Or you can use webhooks to carry out an action whenever an event occurs, e.g. get a notification whenever this Amazon web scraper successfully finishes a run.
Can I use Amazon Best Sellers Scraper with API?
Yes, you can do so by using Apify API. It gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify Actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Check out the Apify API reference docs for full details or click on the API tab for code examples.
How can you use Amazon Best Sellers data?
If you're web scraping Amazon for retail or market research, the Amazon Best Sellers list can tell you a lot about the top trends in e-commerce. Competing directly against top-selling items across Amazon can be difficult, but it also can be a source of inspiration for new products for e-commerce retailers. Data collected on those top-selling items can help you:
- stay ahead of the competition
- improve sales for your business
- track up-and-coming products
- adjust your product prices to market levels
Not your cup of tea? Build your own scraper
Amazon Best Sellers Scraper doesn’t exactly do what you need? You can always build your own! We have various scraper templates in Python, JavaScript, and TypeScript to get you started. Alternatively, you can write it from scratch using our open-source library Crawlee. You can keep the scraper to yourself or make it public by adding it to Apify Store (and find users for it). Or let us know if you need a custom scraping solution.
Resources on how to scrape data from Amazon Best Sellers
- Platform pricing page with pricing specifications.
- Video guide ▷ on how to choose the right subscription plan.
- Step-by-step guide on how to use Amazon Best Sellers scraper.
- Input tab with all the technical parameters of this scraper.
- Is web scraping legal on the legal aspects of web scraping.
Your feedback
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for Amazon Best Sellers or simply found a bug, please create an issue on the Actor’s Issues tab in Apify Console.