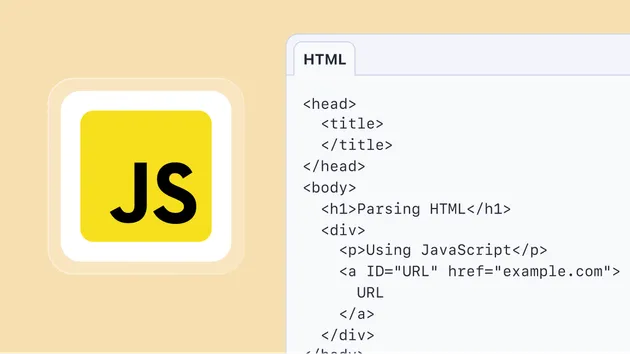
Download HTML from URLs
Pricing
Pay per usage
Go to Apify Store
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Marek Trunkát
Maintained by CommunityActor stats
40
Bookmarked
9.3K
Total users
38
Monthly active users
7 months ago
Last modified
Categories
Share