Wellfound Scraper
Pricing
$24.99/month + usage
Wellfound Scraper
Access high quality startup job and company data from Wellfound (AngelList) skills, experience, salary, remote policies, company linkedin, funding rounds, teams and investors. Built for recruiters, analysts, and job seekers with fast export to JSON, CSV, Excel, RSS & more.
Pricing
$24.99/month + usage
Rating
4.9
(6)
Developer
Radeance
Maintained by CommunityActor stats
51
Bookmarked
1.1K
Total users
17
Monthly active users
16 hours
Issues response
7 hours ago
Last modified
Categories
Share
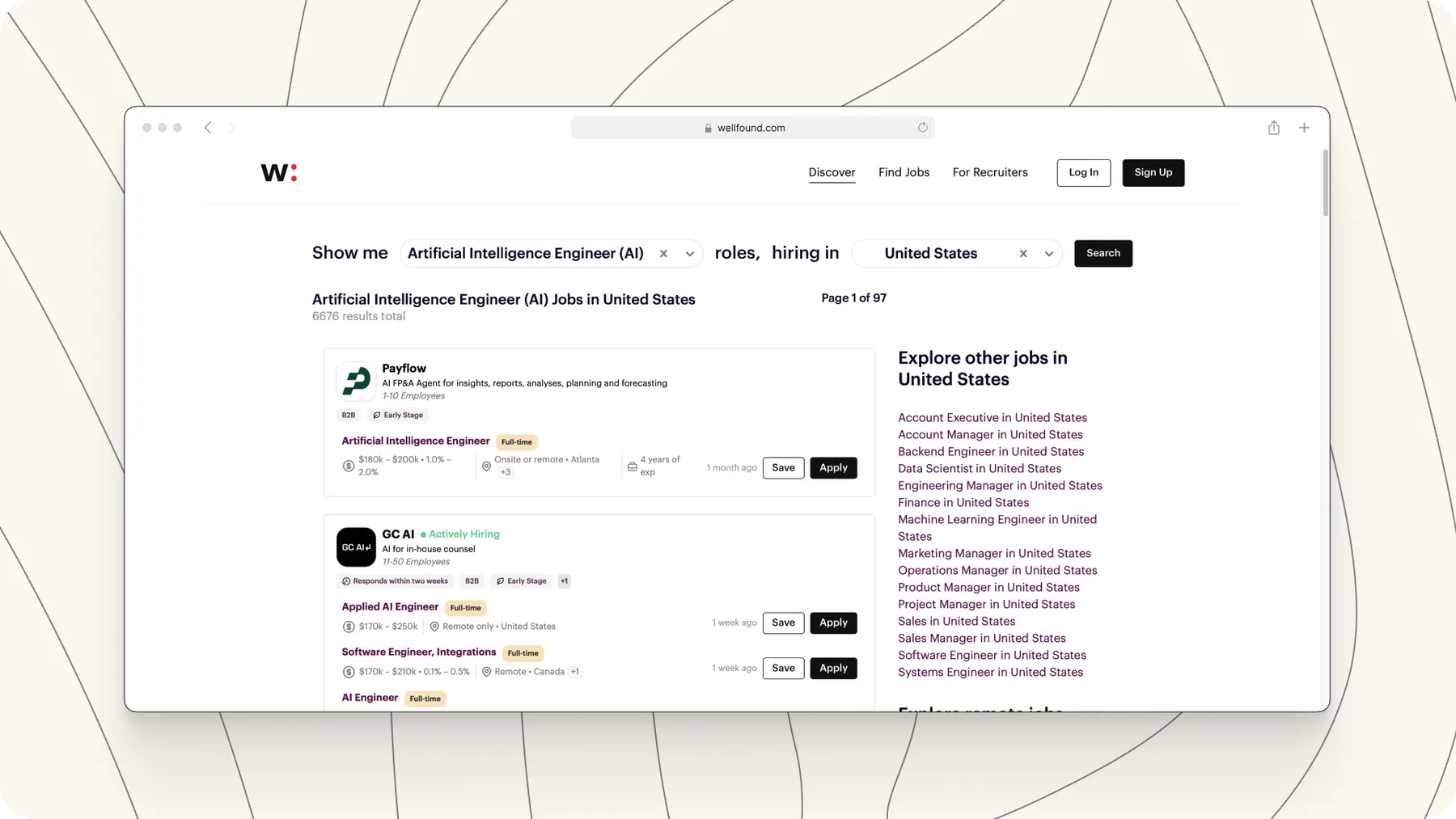
Wellfound Jobs & Company Scraper
| Discover more ➤ | Glassdoor Jobs Scraper | Ahrefs Scraper | Amazon Price History API | Amazon Sales Rank Scraper 🆕 |
|---|
The Wellfound Jobs & Company Scraper on Apify lets you capture rich, structured data from Wellfound at scale.
It extracts everything from job listings, job pages (Compensation, Skills, Experience, Work arrangements) to company profiles (LinkedIn, Funding, Markets, Size, Locations), team members, founders, and even in-depth investor information perfect for market research and lead generation.
Designed for job seekers, recruiters, headhunters and analysts, this Actor delivers one of the most complete startup datasets available — with high-performance scraping that processes thousands of listings in minutes and outputs clean JSON, CSV, XLSX, and more.
❶ Key Features
-
Full Job Information ✅
Job title, Description, Compensation (Salary + Equity), Skills, Experience required -
Work Arrangement Details ✅
Remote policies, Visa sponsorship, Relocation allowance, Collaboration hours -
Rich Company Information ✅
Company LinkedIn, Social media links, Size, Funding rounds, Locations, Website (optional) -
Team & People Data ✅
Founders, Team members, Board members, Years at company (optional) -
Funding & Investment Data ✅
Total funding raised, Investor details, Funding rounds, Valuations (optional) -
Advanced Options ✅
Custom URLs, Pagination control, Flexible output formats -
High Performance ✅
Process thousands of jobs & companies in no-time with pinpoint accuracy -
Flexible Data Output ✅
We support various formats: CSV, XLSX, JSON, JSONL, XML, RSS
❷ Output
Job Listings / Posts Search
ℹ️ Optional: include_job_page can be set to true to include the job related fields below
Company Profile Option
ℹ️ Optional: The fields below will be included when include_company_profile is set to true
Company People Option
ℹ️ Optional: The fields below will be included when include_company_people is set to true
Company Funding Option
ℹ️ Optional: The fields below will be included when include_company_funding is set to true
❸ Input
Basic Job Search Parameters
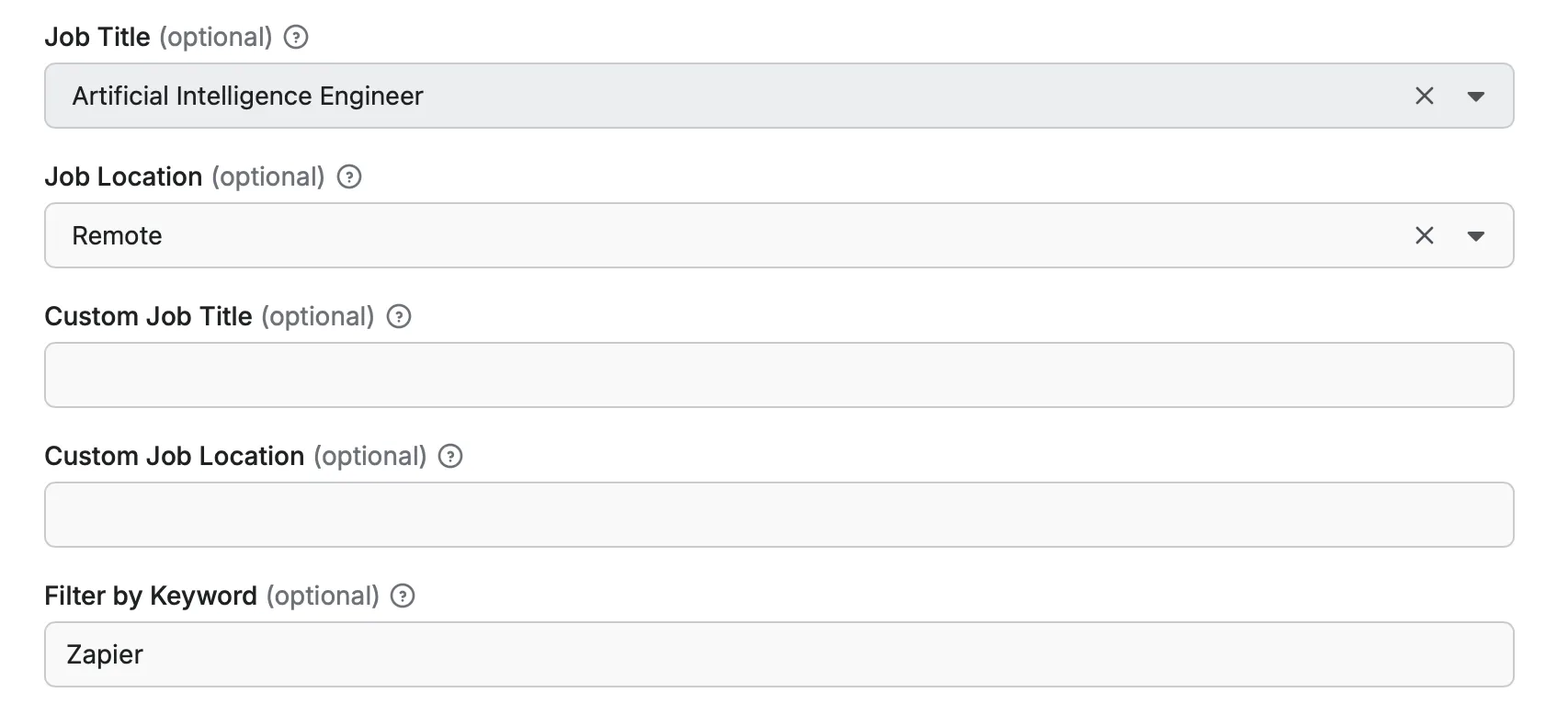
- job_title: (Optional) (String)
Select desired job from the input list. If you can't find your desired job title use Custom Job Title input field. If you use a url in advanced options this gets ignored.
- job_location: (Optional) (String)
Select desired job location from the input list. If you can't find your desired job location use Custom Job Location input field. If you use a url in advanced options this gets ignored.
- custom_job_title: (Optional) (String)
Enter your desired job title (e.g. Big Data Analyst). Please be aware that not every job title is available. You should check that your desired job title is available on Wellfound.
ℹ️ If you use this Field the job_title Field above is ignored.
- custom_job_location: (Optional) (String)
Enter your desired job location (e.g. London). Please be aware that not every job location is available. You should check that your desired job location is available on Wellfound.
ℹ️ If you use this Field the job_location Field above is ignored.
- keyword: (Optional) (String)
Enter any keyword to search for in the job title or description (e.g. "python", "remote", "marketing" etc.). This is a full text search field and it will return all jobs that have the keyword in any of their fields. You can use this field to search for specific skills, technologies, job requirements, company names etc. that are not covered by the other fields.
Company Search Options
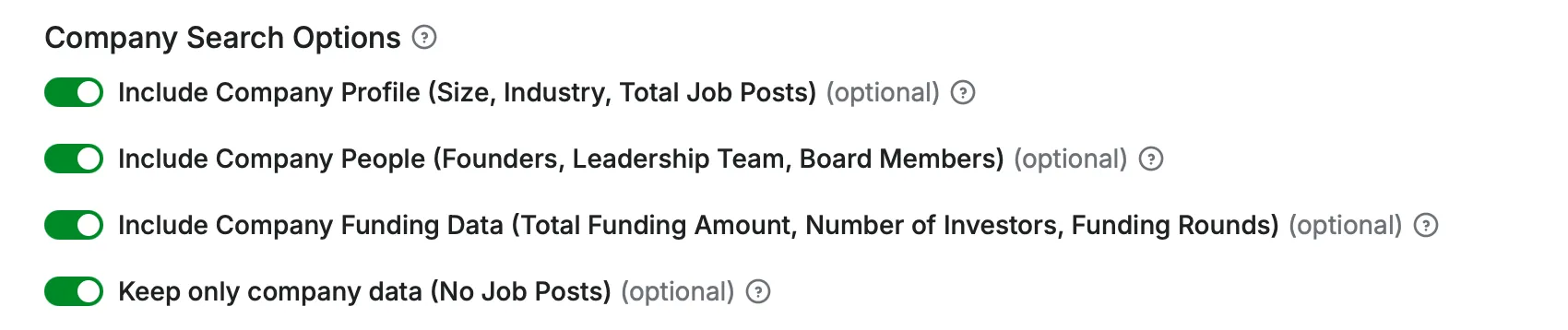
- include_company_profile: (Optional) (Boolean)
If enabled the scraper will extract additional company profile data including socials like company website, linkedin, facebook, twitter etc.
ℹ️ Default: True
- include_company_people: (Optional) (Boolean)
If enabled the scraper will extract additional company people data including founders, board members and team members.
ℹ️ Default: False
- include_company_funding: (Optional) (Boolean)
If enabled the scraper will extract additional company funding data including funding rounds, investors, incubators etc.
ℹ️ Default: True
- only_company: (Optional) (Boolean)
If enabled the scraper will only extract company data without job posts. You should use this if you want to scrape all companies for example in a specific category/location.
ℹ️ Default: False
Quick Filter Options
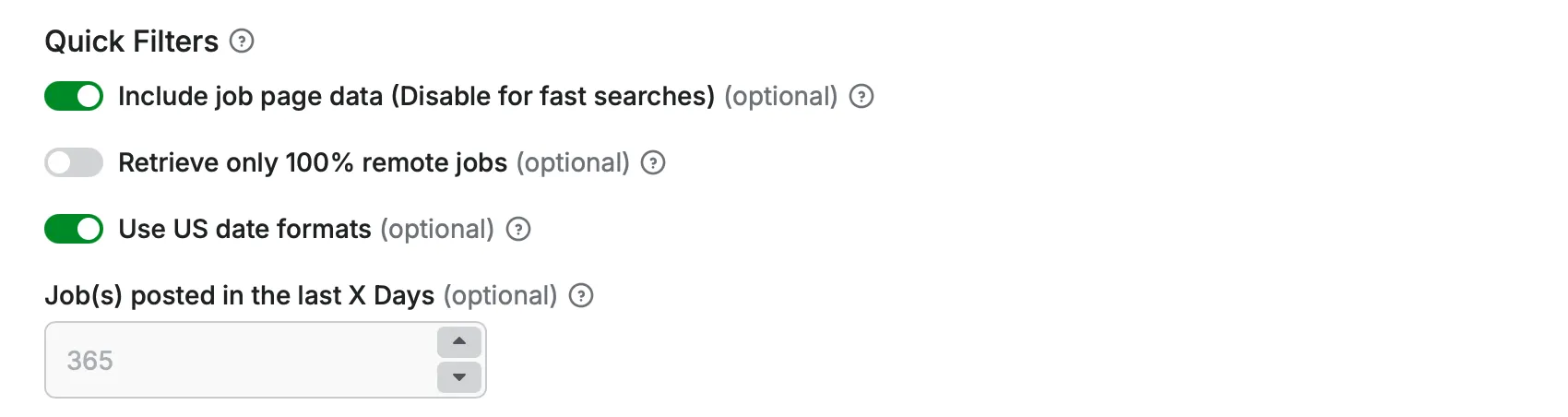
- include_job_page: (Optional) (Boolean)
If enabled the scraper will proccess each listings job page to extract additional details like full job description, benefits, company url, size etc. If disabled only the data available on the listing page will be extracted.
ℹ️ Default: True
- fully_remote: (Optional) (Boolean)
If enabled the scraper outputs only jobs with remote work policy 'Onsite or remote' and 'Remote only'. If set to False it will output all jobs.
ℹ️ Default: False
- us_date_format: (Optional) (Boolean)
If enabled the scraper outputs every date field to US datetime format. If set to False it uses standard international datetime format.
ℹ️ Default: True
- last_x_days: (Optional) (Integer)
Returns only the jobs that got posted the last x days. Make sure to use a high max_page number if you use a high value here.
ℹ️ Default: 365
ℹ️ Range: 1 - 1,000
Monitoring Mode Options

- monitoring_mode: (Optional) (Boolean)
If enabled, it will only scrape new job posts that have not been previously scraped.
ℹ️ Default: False
- reset_monitoring: (Optional) (Boolean)
If enabled, it will reset the monitoring data and scrape all job posts again.
ℹ️ Default: False
Pagination Options
- max_pages: (Optional) (Integer) - ⚠️ Free Users are limited to first 5 pages
The maximum number pages to crawl. It includes the start URLs, pagination pages. The crawler will automatically finish after reaching this number. If not provided, the crawler will only scrape from the start URL.
ℹ️ Default: 1
ℹ️ Range: 1 - 1,000
- page_offset: (Optional) (Integer) - ⚠️ Feature is only available for paying users
The page number the scraper should scrape from.
ℹ️ Default: 1
ℹ️ Range: 1 - 1,000
- max_items: (Optional) (Integer)
The maximum number of job posts to scrape. Defaults to 500. If there are no more job posts to scrape, the actor will stop even if this number is not reached. If you want to scrape all pages, set it to a high number like 1000.
ℹ️ Range: 1 - 10,000
Job Salary Filter Options
- min_salary: (Optional) (Integer)
Filters job listings by minimum salary. 0 means no filter.
ℹ️ Default: 0
Range: 0 - 1,000,000
- max_salary: (Optional) (Integer)
Filters job listings by maximum salary. 0 means no filter.
ℹ️ Default: 0
Range: 0 - 1,000,000
- include_no_salary: (Optional) (Boolean)
If checked, the actor will include jobs that do not have a salary listed. If unchecked, only jobs with a salary will be included.
ℹ️ Default: True
Advanced Job Filter Options
- job_type: (Optional) (String)
Filter by job type. If you leave this field empty, the actor will return all job types.
ℹ️ Default: all
ℹ️ Options: all, full-time, part-time, contract
- job_experience: (Optional) (String)
Filter by job experience. If you leave this field empty, the actor will not filter by experience.
⚠️ Jobs with no experience level listed will not be included in the results.
ℹ️ Default: all
ℹ️ Options: all, entry, mid, senior
- job_skills: (Optional) (Array)
Filter on one or multiple job skills. If you leave this field empty, the actor will not filter by skills.
⚠️ Jobs with no skills listed will not be included in the results. A too narrow filter may result in no jobs being returned.
ℹ️ Default: []
- company_category: (Optional) (Array)
Filter on company category. If you leave this field empty, the actor will not filter by company category.
⚠️ A too narrow filter may result in no jobs being returned.
Multi-select field supporting categories like: saas, startups, fintech, healthcare, ai/ml, e-commerce, and many more.
Output & Monitoring Options
- only_unique_jobs: (Optional) (Boolean)
If enabled, it will only keep unique job posts adding a deduplication step.
Default: True
- stream_output: (Optional) (Boolean)
If enabled, the output will be pushed to the dataset as soon as a job post is scraped. If disabled, the output will be pushed to the dataset only after the whole scraping process is finished.
Default: True
- sorting: (Optional) (String)
Sorting method for job listings.
ℹ️ Default: newest
ℹ️ Options: newest, oldest
Bulk Options (Multi-Location, URLs)
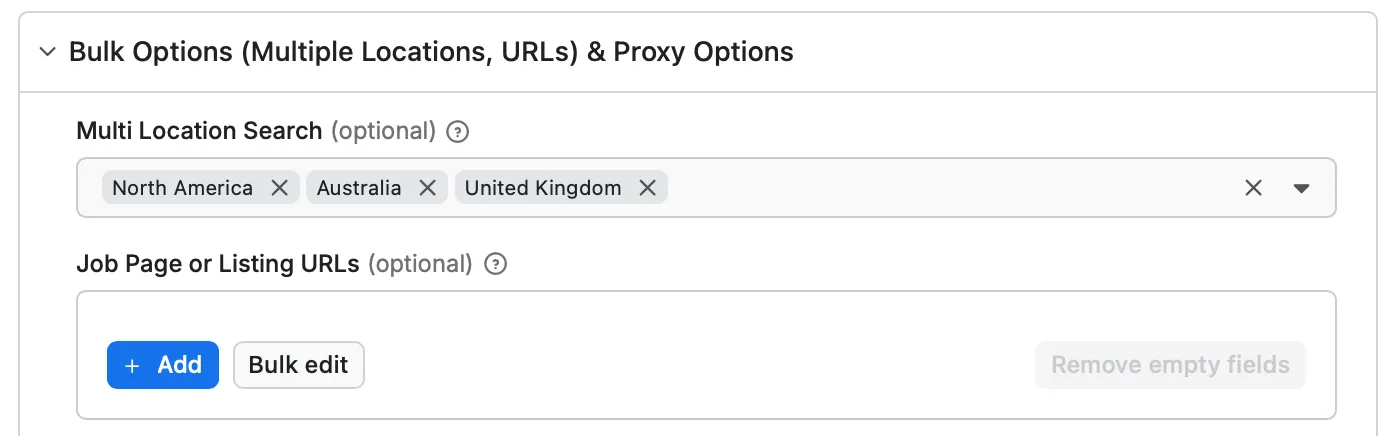
- locations: (Optional) (Array)
Search on multiple location by selecting from the locations list. Leave empty to search on the location parameter above or by the location specified in the URL(s) below. You can specify multiple locations by selecting from the list.
Maximum Allowed Locations at the moment is 5 at a time for paying and 2 for free users, others will be disregarded.
⚠️ Warning, by using this field the job location parameters will be ignored.
ℹ️ Default: []
- urls: (Optional) (Array)
Job Page or Listing URLs to scrape from. You can specify multiple URLs by clicking on the Add button or in bulk by clicking on the Bulk edit button. Maximum Allowed URLs is 5 at a time, others will be disregarded.
⚠️ Warning, by using this field the job & location parameters will be ignored.
See all URL formats we support below.
Supported Keyword Formats
ℹ️ Allowed are a maximum of 30 characters, including spaces and special characters like + @ # .
| Keyword | Supported |
|---|---|
| C++ Developer | ✅ |
| Data Scientist | ✅ |
| Développeur Web | ✅ |
| Data Analyst @Remote | ✅ |
Supported URL Formats
ℹ️ The following URL formats are supported. ⚠️ You can only have 1 URL per run if you are a free user.
JSON Input
Sample JSON input if you use the apify api via CURL, Python, JS etc.
❹ Use Cases
- Job Seekers: To find comprehensive job information, including job type, pay details, remote work policies, and company details.
- Recruiters & Hiring Managers: To gather detailed job listings, including job title, location, pay range, and application and social media URLs.
- Market Researchers: Analyze hiring trends, compensation benchmarks, company growth stages, and funding patterns across industries
- Sales & Business Development: Identify potential clients based on company size, funding status, hiring activity, and growth indicators and technology stack
- Investment Analysts: Research portfolio companies, track funding rounds, analyze investor networks, and monitor hiring patterns
- HR Analytics Teams: Benchmark compensation packages, analyze remote work trends, and study organizational structures
- Developers: Integrate rich job and company data into applications for enhanced job search and company research experiences
Wellfound Jobs & Company Scraper streamlines the process of collecting and analyzing job market data, making it a valuable tool for various professionals.
❺ Usage Limits
This service has different usage limits depending on your subscription status:
| User Type | Daily Runs | Company Search Options | Max Pages per Run | Max URLs per run | Reset Period |
|---|---|---|---|---|---|
| Free | 10 runs | Trial for 3 run(s) | 5 pages | 1 URL per run | 24-hours |
| Paid | Unlimited | Unlimited | Unlimited | Unlimited | N/A |
How Limits Work
- Free users: Limited to 10 runs with up to 5 pages per run in a 24-hour period from your first usage. Company search options (profile, people, funding) are limited to 3 runs total per day.
- Paid users: No limits on the number of runs or the number of pages per run or company search options.
❻ FAQ
How do i make a simple search for "Data Scientist" jobs in "New York"?
You can either use the dropdowns for job title and location or use the custom job title and custom job location fields. If you use the custom fields the dropdowns will be ignored.
How do i scrape jobs from multiple locations?
You can use the locations field in the Bulk Options Section to select multiple locations. You can select up to 5 locations at a time if you are a paying user and up to 2 locations if you are a free user. If you use this field the job location parameter will be ignored.
How do i scrape jobs from multiple urls?
You can use the urls field under Bulk Options to add multiple urls. You can add up to 5 urls at a time. If you use this field the job and location parameters will be ignored.
How do i scrape all jobs from a specific company?
You can use the company url directly from Wellfound to scrape all jobs from a specific company. Input the URl in the URLs field under Bulk Options For example: https://wellfound.com/company/stripe/jobs
How do i monitor for new job posts only?
You can enable the monitoring mode option in the Monitoring Mode Options section and schedule a recurring task for example every 24 hours. This will make the scraper scrape only new job posts that have not been previously scraped. You can also reset the monitoring data by enabling the reset monitoring option once. This will make the scraper scrape all job posts again.
How do i scrape only company data without job posts?
You can enable the only company option in the Company Search Options section. This will make the scraper scrape only company data without job posts. You can use this if you want to scrape all companies for example in a specific category/location.
How do i add company profile data like LinkedIn, Facebook, Twitter, Website etc to the output?
You can enable the include company profile option (former company socials option) in the Company Search Options section. This will add additional fields to the output including socials like company website, linkedin, facebook, twitter etc.
How do i add company board members, founders and team members to the output?
You can enable the include company people option in the Company Search Options section. This will add additional fields to the output including founders, board members and team members.
How do i add company funding data to the output?
You can enable the include company funding option in the Company Search Options section. This will add additional fields to the output including funding rounds, investors, incubators etc.
How do i scrape jobs from a specific category?
You can use the company category field to select one or multiple categories. If you select multiple categories the actor will scrape jobs from all selected categories.
How do i scrape jobs with specific skills?
You can use the job skills field to select one or multiple skills. If you select multiple skills the actor will scrape jobs that match all selected skills.
❼ While the scraper is running
During the run, the actor will output log messages letting you know what is going on at any point. Each message always contains specific information about the process including which url / page the actor is working on.
If you provide invalid inputs to the actor, it will immediately stop with a failure state and output log messages explaining what is wrong. If you are unsure what went wrong feel free to open up an issue in the issue tab.
❽ Legality of web scraping
The Wellfound Jobs & Company Scraper is designed to ethically extract only publicly available job data and company information, and it does not scrape private user data such as personal email addresses or personal identifiers.
Our services are ethical and do not extract any private user data. They only extract what individuals or companies chose to share publicly. We therefore believe that our services, when used for ethical purposes by our users, are safe to use. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. For more information you can read this blog post on the legality of web scraping from Apify.
❾ Feedback and Support
Your satisfaction is important to us! Therefore we are constantly striving to enhance the performance of our services.
If you have any technical feedback or encounter any bugs within the Wellfound Jobs & Company Scraper, please create an issue in the Actor’s Issues tab on the Apify Console to let us know about it. We will look into it as soon as possible.
You can also contact us directly for general help on issues or integrations at suppport@radeance.com.
For custom projects, general suggestions or new use cases feel free to reach out to us at business@radeance.com