Similarweb Scraper
Pricing
from $5.00 / 1,000 results
Similarweb Scraper
Extract website traffic, global rank, country rank, bounce rate, visit duration, and traffic sources from Similarweb. Get detailed insights on SEO, referrals, and audience demographics. Scrape single or multiple URLs effortlessly. Export data as HTML Table, JSON, JSONL, CSV, Excel, XML, or RSS.
Pricing
from $5.00 / 1,000 results
Rating
3.2
(10)
Developer
Radeance
Maintained by CommunityActor stats
67
Bookmarked
1.5K
Total users
279
Monthly active users
2.9 hours
Issues response
3 days ago
Last modified
Categories
Share
💎 Similarweb SEO Scraper
| Discover more ➤ | Ahrefs Scraper | Semrush Scraper | MOZ Scraper | Ubersuggest Scraper |
|---|
The Similarweb Scraper on Apify gives you complete website traffic intelligence. Whether you’re a marketer, SEO analyst, or business strategist, this scraper helps you extract global and country-level visits, traffic sources, engagement metrics, keyword data (volume, CPC, value), top referral & social channels and many more key data points all in one dataset.
With optional in-depth data, you can uncover company insights, audience demographics (age & gender), competitor comparisons, and historical rank trends across industries and regions. Lookup competitors or similar sites to analyze market share and audience overlap with SimilarSites.com data.
Whether you’re benchmarking competitors, analyzing digital performance, or building marketing dashboards, this Actor provides accurate, export-ready analytics (JSON, CSV, XLSX, and more) for comprehensive market intelligence at scale.
❶ Key Features
- 🌍 Comprehensive Website Analytics:
- Scrapes detailed web traffic insights from SimilarWeb
- Extracts essential metrics like global rank, country rank, and category rank
- Retrieves title, description, and domain details automatically
- 📊 In-Depth Traffic Data:
- Provides total visits and monthly visits for the last 3 months
- Breaks down traffic by top countries with monthly traffic estimates
- Extracts engagement metrics like bounce rate, pages per visit, and average time on site
- 🚦 Traffic Source Breakdown:
- Scrapes direct, referral, search, social, paid, and mail traffic distribution
- Analyzes country-specific traffic shares for regional insights
- ⚡ Fast and Efficient:
- Blazing-fast performance, capable of scraping thousands of entries in minutes
- 🔧 Advanced Customization:
- Allows scraping a specific website URL for targeted insights
- Easy to configure for extracting custom datasets
- 📁 Flexible Data Output:
- Exports data in multiple formats: CSV, XLSX, JSON, JSONL, XML, and RSS
❷ Output
Base Data
ℹ️ When include_base_data is enabled the output looks like this
Addon: Indepth Data
ℹ️ When include_indepth_data is enabled this additional data is included in the output
Addon: Similar Sites Data
ℹ️ When include_similar_sites is enabled this additional data is included in the output
Field Reference
| Field | Type | Description |
|---|---|---|
data_captured_at | string (ISO datetime) | Timestamp when the dataset was captured. |
searchUrl | string (URL) | The original URL used for the lookup request. |
url | string (URL) | Canonical URL of the analyzed website. |
domain | string | Domain name of the analyzed website. |
rankGlobal | number or null | Global ranking of the website based on traffic metrics. |
country | string or null | Primary country associated with the website traffic or ranking. |
countryRank | number or null | Ranking of the website within the specified country. |
category | string or null | Category classification of the website. |
categoryRank | number or null | Ranking of the website within its category. |
title | string | Page title of the analyzed website. |
description | string | Meta description of the website. |
bounceRate | number | Percentage of visitors leaving the site after viewing one page. |
pagesPerVisit | number | Average number of pages visited per session. |
timeOnSite | number | Average time (seconds) users spend on the site per visit. |
totalVisits | number | Total estimated visits for the selected time period. |
monthlyVisitsDateFormat | object | Map of monthly visits where keys represent dates and values represent visits. |
monthlyVisits | array of objects | Monthly visit statistics containing month and visits. |
website_traffic_by_country | array of objects | Breakdown of traffic by country including traffic share and monthly visit history. |
topKeywords | array of objects | Top organic keywords driving traffic to the website. |
engagement | object | Summary of engagement metrics for a specific month. |
socialTraffic | number | Share of traffic coming from social media sources. |
paidReferralsTraffic | number | Share of traffic generated through paid referral channels. |
referralTraffic | number | Share of traffic coming from referral links on other websites. |
searchTraffic | number | Share of traffic originating from search engines. |
directTraffic | number | Share of traffic from users visiting directly. |
mailTraffic | number | Share of traffic originating from email campaigns. |
aiTrafficShareChatgpt | number or null | Share of AI-driven traffic attributed to ChatGPT. |
aiTrafficShareClaude | number or null | Share of AI-driven traffic attributed to Claude. |
aiTrafficSharePerplexity | number or null | Share of AI-driven traffic attributed to Perplexity. |
aiTrafficShareGemini | number or null | Share of AI-driven traffic attributed to Gemini. |
aiTrafficShareCopilot | number or null | Share of AI-driven traffic attributed to Copilot. |
aiTrafficShareHistory | array of objects | Historical share of traffic from AI assistants over time. |
aiTopPrompts | array of strings | Most common prompts that generated AI-driven traffic. |
countryShare | array of objects | Traffic share distribution by country. |
isDataFromGoogleAds | boolean | Indicates whether the traffic data includes Google Ads sources. |
isSmall | boolean | Indicates whether the dataset represents a smaller traffic profile. |
policy | number | Internal classification or policy indicator for the dataset. |
previewDesktop | string (URL) | Desktop preview image of the website. |
previewMobile | string (URL) | Mobile preview image of the website. |
snapshotDate | string (ISO datetime) | Date representing the snapshot of the dataset. |
favicon | string (URL) | Website favicon image URL. |
redirect | string | Canonical redirect domain if applicable. |
similarSites | array of objects | List of websites with similar audience or category relevance. |
related_apps | array of objects | List of iOS and Android Apps related to the website based on user interest and category. |
Output Table Views
Overview

Traffic

Engagement

In-Depth

Similar Sites

❸ Input
If you use this actor on the apify platform, the UI Input interface is quite self explaining but here are some guidelines to help you use it:
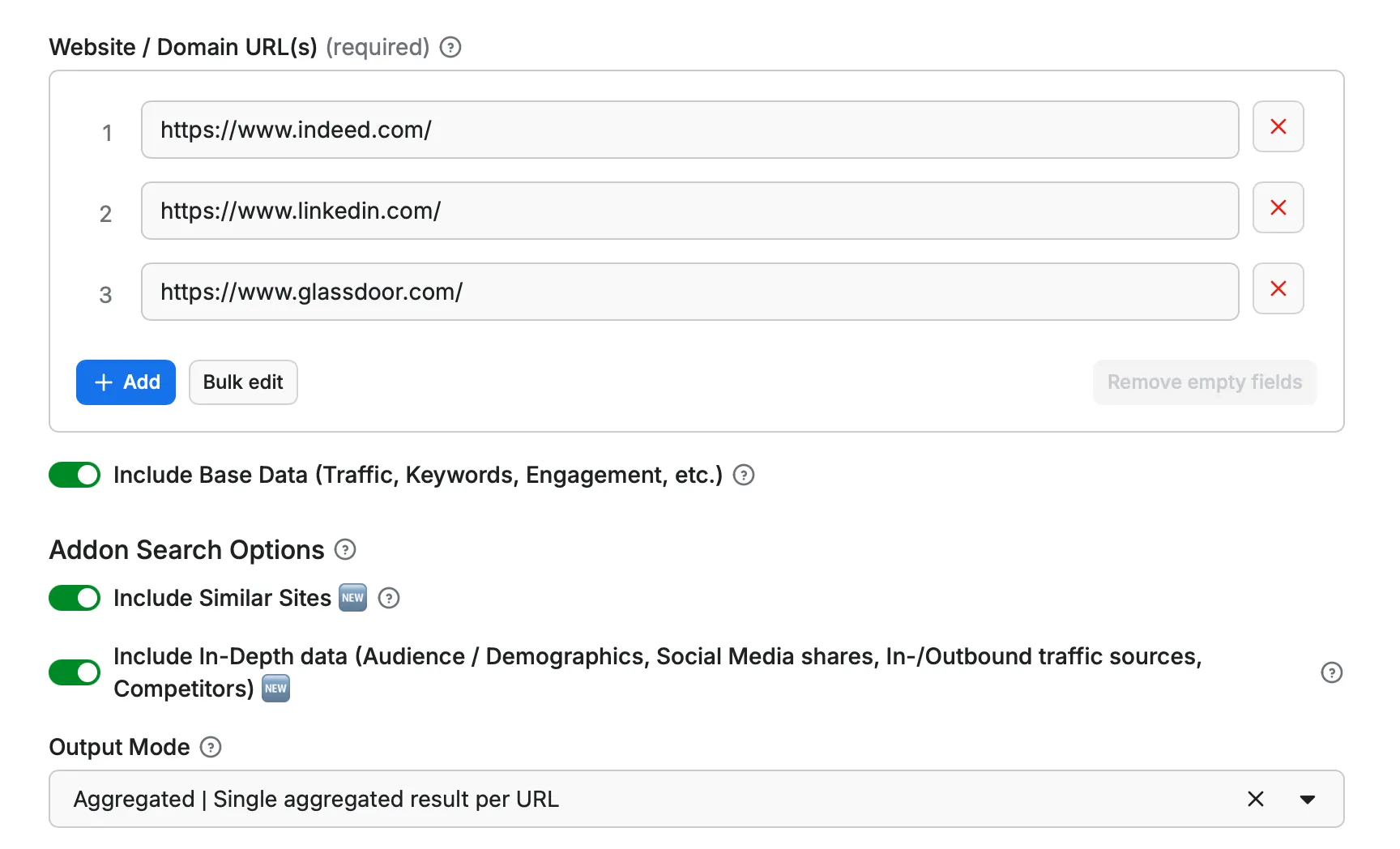
Input Parameters
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
urls | array of strings | Yes | — | List of webpage URLs to analyze. Supports a single URL or multiple URLs for bulk requests. |
include_base_data | boolean | No | true | When enabled, the response will include a list of similar websites along with their traffic statistics, rankings, and category data. |
include_similar_sites | boolean | No | false | When enabled, the response will include a list of similar websites along with their traffic statistics, rankings, and category data from Similarsites.com |
include_indepth_data | boolean | No | false | Includes additional in-depth data such as company information, audience insights, historical rankings, competitors, and more directly from Similarweb.com Note: This data may only be available for websites with significant traffic and presence. |
output_mode | aggregated, individual | No | aggregated | Sets the output format for the retrieved data. Aggregated combines all data to a single search result item. Individual outputs a single search result item per search option. |
Supported URL Formats
| URL Formats | Supported |
|---|---|
https://google.com | ✅ |
http://google.com | ✅ |
www.google.com | ✅ |
google.com | ✅ |
JSON Input
If you decide to use this actor from your favourite programming language. This would be a sample JSON input if you use the Apiy API via CURL, Python, JS etc.
❹ Use Cases
Market Analysis: Efficiently scrape and analyze large volumes of website traffic data to understand market trends, popular categories, and emerging online sectors.
Competitor Benchmarking: Extract and compare website traffic metrics across different domains to determine competitive positioning and performance benchmarks.
Company Insights: Gather detailed company information, including domain authority, global and country ranks, and category ranks to evaluate market presence and performance.
Traffic Source Analysis: Identify and analyze traffic sources, such as direct, referral, social, and search traffic to optimize marketing strategies and improve traffic acquisition.
Regional Market Insights: Collect and analyze country-specific traffic data to understand regional market shares and user demographics for targeted marketing campaigns.
SEO and SEM Optimization: Monitor search traffic and paid referrals to refine SEO strategies and enhance SEM campaigns, ensuring higher visibility and better ROI.
Content Performance Tracking: Analyze the performance of specific content categories and popular topics among users to optimize content marketing strategies and boost engagement.
Audience Segmentation: Segment audiences based on traffic sources and country shares to tailor marketing messages and improve conversion rates.
Technology Usage Analysis: Discover the technologies used by competitors and market leaders to inform technology stack decisions and stay ahead in the digital landscape.
Strategic Planning: Use comprehensive website and traffic data to inform strategic planning, market entry decisions, and business development initiatives.
Ad Campaign Effectiveness: Evaluate the effectiveness of digital ad campaigns by tracking referral and direct traffic metrics, ensuring optimal ad spend and higher conversion rates.
Brand Visibility: Analyze and compare global and local rankings to measure brand visibility and impact in different markets, guiding brand-building efforts.
These use cases demonstrate the versatility and value of the Similarweb Scraper in providing detailed market insights, optimizing digital marketing efforts, and enhancing strategic business planning.
❺ Pricing and Usage Limits
ℹ️ Pricing depends on the Apify subscription plan you are on. Higher plans will usually be charged less:
| Pricing Events | Explanation | Free | Starter | Scale | Business |
|---|---|---|---|---|---|
Result | Cost per result item returned. Each search type counts as one individual result. | $9.00 / 1,000 | $8.00 / 1,000 | $6.00 / 1,000 | $5.00 / 1,000 |
In-depth search | Cost per single in-depth data search. This cost is in addition to the normal price for a successful result due to higher ressource usage. | $3.00 / 1,000 | $2.00 / 1,000 | $1.50 / 1,000 | $1.00 / 1,000 |
Actor start | Charged when the Actor starts running. Number of events charged depends on Actor memory: one event per GB, minimum one event. | $0.001 | $0.001 | $0.001 | $0.001 |
Platform usage | Platform usage costs are covered by us. You are not charged separately for platform usage. | Free | Free | Free | Free |
ℹ️ This service has different usage limits depending on your subscription status:
| User Type | Daily Runs | In-Depth Option | In-Depth Data URL(s) | # Bulk URL(s) Supported | Reset Period |
|---|---|---|---|---|---|
| Free | 10 run(s) | - | 3 per run | 3 per run | 30 days |
| Paid | Unlimited* | Unlimited* | Unlimited* | Unlimited per run* | N/A |
* Unlimited usage is subject to our fair use policy, resource availability, and the technical limitations of our services.
How Limits Work
- Free users: Limited to 10 runs per 30-day period from your first usage.
- Paid users: No fixed limits on the number of runs, In-Depth Option uses, In-Depth Data URL(s), or Bulk URL(s), subject to our fair use policy, resource availability, and the technical limitations of our services.
❻ FAQ
What data can you get with Similarweb Scraper?
The Similarweb Scraper provides a comprehensive set of data points, including:
- Website traffic metrics (visits, bounce rate, pages per visit, time on site)
- Traffic sources (direct, referral, social, search, mail)
- Country-specific traffic shares and monthly traffic trends
- Top keywords driving traffic to the website
- Audience insights (interests, similar sites, top referring domains)
- Technology usage (top technology providers and categories)
- Related iOS and Android apps when available
- In-depth data (company information, historical rankings, competitors, etc.) for websites with significant traffic and presence when enabled
- Similar sites data from Similarsites.com when enabled
For more informtation about the data you can get please check the Output section above.
How many results can you scrape with Similarweb Scraper?
Similarweb Scraper can retrieve as much results as you need. We tested it with on average between 50-100 individual webpages per search request. It's realy up to you how much you need to scale it. Performance wise the scraper is able to return results in less than 3-5 seconds on average.
Please keep in mind that Similarweb is a highly dynamic page with suffisticated bot protection so your results may very depending on your use-case. We do our best so you don't need to worry about this limitations.
For most cases, the Similarweb Actor is perfect for individuals, market researchers, analysts, and digital marketing professionals, as well as businesses looking to analyze web traffic and competitor insights.
Which proxy options should I use for Similarweb Scraper?
You don't need to worry about proxies when using the Similarweb Scraper. The scraper is designed to work with our internal proxy infrastructure, which is optimized for handling the bot protection measures implemented by Similarweb. This means you can run the scraper without needing to set up or manage your own proxies.
❼ While the scraper is running
During the run, the actor will output log messages letting you know what is going on at any point. Each message always contains specific information about the process including which url / page the actor is working on.
If you provide invalid inputs to the actor, it will immediately stop with a failure state and output log messages explaining what is wrong. If you are unsure what went wrong feel free to open up an issue in the Issues tab.
❽ Legality of web scraping
The Similarweb Scraper is designed to ethically extract only publicly available SEO data, and it does not scrape private user data such as personal email addresses or personal identifiers.
Our scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. We therefore believe that our scrapers, when used for ethical purposes by Apify users, are safe. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read this blog post from Apify on the legality of web scraping.
❾ Feedback and Support
Your satisfaction is important to us! Therefore we are constantly striving to enhance the performance of our services.
If you have any technical feedback or encounter any bugs within the Similarweb Scraper, please create an issue in the Actor’s Issues tab on the Apify Console to let us know about it. We will look into it as soon as possible.
You can also contact us directly for general help on issues or integrations at suppport@radeance.com.
For custom projects, general suggestions or new use cases feel free to reach out to us at business@radeance.com