Business Name & Phrase to URL Resolver - Google Search
Pricing
$7.50 / 1,000 search query executeds
Business Name & Phrase to URL Resolver - Google Search
Resolve business names or distinctive footer phrases into deduped website URLs via Google. Used as a sub-actor by Website Contact Scraper and B2B Lead Gen Suite, or standalone for URL discovery. Country-aware TLD filtering, drops social and directory hosts. Pay-per-query, no subscription.
Pricing
$7.50 / 1,000 search query executeds
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
0
Bookmarked
15
Total users
4
Monthly active users
2.9 hours
Issues response
a month ago
Last modified
Categories
Share
Business Name & Phrase to URL Resolver
Business Name & Phrase to URL Resolver is a deterministic company website resolver for Apify that converts company names and marketing phrases into canonical domains with automation-safe trust signals. Give it a list of names (or distinctive marketing phrases) and it returns a deduped list of website URLs from Google, each scored with a confidence level so you know which results to trust before spending on downstream scraping.
This is the discovery front door of a lead pipeline. It feeds Website Contact Scraper: paste names instead of URLs and the resolver turns them into domains for the next step. It also runs standalone whenever you only need the name-to-URL step.
What it is
The Business Name & Phrase to URL Resolver is a deterministic company website resolver for Apify. It is also a pre-enrichment firewall: a deterministic gate that decides which resolved domains are safe to send downstream, before you spend on scraping or enrichment.
- Is: a deterministic company website resolver, a pre-enrichment firewall, an entity-normalization step, a workflow-safe domain-discovery actor.
- Is not: a generic Google scraper, a contact scraper, an email verifier, an enrichment database, an LLM-powered resolver.
Compared to enrichment databases (Apollo, Clearbit, ZoomInfo) and agentic pipelines (Clay, AI SDR stacks), it focuses narrowly on one job: turning names into canonical domains with deterministic confidence, ambiguity detection, and automation-safe routing.
Why not use Apollo or Clay for this?
Apollo, ZoomInfo, and Clearbit are enrichment databases; Clay is an enrichment-orchestration pipeline. They start after the entity's identity is assumed. This actor establishes that identity first, deterministically, against Google's live index, so the wrong company never enters those tools in the first place. Use it in front of them, not instead of them.
What makes this different
- It scores the resolution, not just returns it. Every domain comes with a deterministic
confidenceLevel(high / medium / low) built from SERP rank and how well the domain matches the searched name. A generic Google scraper hands you the top result and leaves you guessing whether it's the right company. - It tells you what failed. Names that resolve to nothing come back as
unresolvedrecords with afailureTypeand an actionable reason, never a silently shorter list. You always know your real hit rate. - It is built to chain. Every record carries an
actorGraph.nextpointer to the contact scraper, so wiring the pipeline in Make, n8n, or Dify is a field read, not hard-coded plumbing.
| This actor | A generic Google/SERP scraper | |
|---|---|---|
| Deterministic confidence per result | ✅ | ❌ |
safeToAutomate gate | ✅ | ❌ |
| Ambiguity detection | ✅ | ❌ |
| SERP noise analysis (confidence dampened on directory-heavy pages) | ✅ | ❌ |
| Unresolved inputs surfaced with a reason | ✅ | ❌ (silent gaps) |
Per-result audit trail (confidenceBreakdown) | ✅ | ❌ |
Pipeline-chaining metadata (actorGraph) | ✅ | ❌ |
| Directory/social hosts auto-excluded | ✅ | ❌ (returns them) |
Before vs after
Before: you have a CRM export or a prospect list of 200 company names and no URLs. You paste them into a search box one by one, eyeball the top result, copy the domain, and hope it's the right company. An hour later you have a half-finished spreadsheet and no idea which rows are wrong.
After: one run returns 200 rows in a couple of minutes, each with a website URL, a confidence level, and a flag on the ones worth double-checking. You pipe the high-confidence rows straight into the contact scraper and review only the handful flagged verifyBeforeUse.
What you get from one call
One row per unique discovered domain (recordType: "domain"), including:
url— full https URLdomain— bare domainconfidenceLevel—high/medium/low: how likely this domain is the right answerconfidenceScore— deterministic 0-1 score behind the levelsafeToAutomate— our default opinion:trueonly when confidence is high AND the result isn't ambiguouspolicyResult— your definition of safe:{ passed, failedRules[] }after evaluating the row against yourresolutionProfile/automationPolicy(see below)recommendedAction— the routing decision in one enum:auto-enrich/verify/retry/skipreasonCodes— stable machine enums (TOP_RANK,LOW_DOMAIN_MATCH,SERP_DIRECTORY_HEAVY,GENERIC_ENTITY, ...) for branching without parsing proseambiguous—truewhen the name had several weak candidates and the top result is likely wrong (add anameSuffixto disambiguate)candidateEntities— for ambiguous names, the scored alternatives[{ domain, confidenceScore, rank }]so an agent can pick its own policy instead of trusting one forced resultcandidateGap— for ambiguous names, the separation between the top two candidates{ topScore, secondScore, gap, weakWinner }entityFingerprint— a portable identity record{ entityId (sha256 of the domain), normalizedName, normalizedDomain, country }for downstream dedup and cachingaliases— other input names in the same run that resolved to this domain (the CRM-dedup signal: Stripe Inc and Stripe Payments both →stripe.com)verifyBeforeUse—truewhen the resolution isn't high-confidence or is ambiguous; route these to a check before spending on downstream scrapingconfidenceBreakdown—{ rankScore, nameMatchScore, serpEnvironment, candidateCount, components[] }, the audit trail behind the score (thecomponents[]array is the deterministic resolution trace), including how noisy the SERP wasrejectedCandidates— the other results from the same query that didn't win, each with a reason (social-host/directory/region-filtered/lower-ranked), so you can see why this domain was chosenoriginalQuery— the Google query that found itqueryType—'name'or'phrase'matchedName/matchedPhrase— provenance back to your inputrank— SERP position (1 = top)actorGraph—{ previous: null, current, next }, wherenextpoints at the website contact scraper for chaining
Names that resolve to nothing come back as recordType: "unresolved" rows with a stable failureType (no-data / directory-only / geo-mismatch / blocked) and an actionable reason telling you what to try next. Run-level totals (resolution rate, confidence distribution, unresolved count, safe-to-automate count) are written to the SUMMARY key in the run's key-value store. Results are sorted best-first, so the top of the dataset is your strongest resolutions.
Social-media hosts, search engines, directory sites, and major real-estate portals are excluded automatically. Output is filtered to your selected country's TLDs.
Resolution confidence
Each resolved domain carries a deterministic confidence score, so you know which rows to trust and which to verify before piping into expensive downstream actors:
namequeries blend SERP rank with how well the resolved domain matches the searched name (e.g. Stripe →stripe.comscores high; a generic name whose top result shares no tokens scores low).phrasequeries are discovery, not direct resolution: every organic result is a candidate, so they are capped at medium confidence and always flaggedverifyBeforeUse: true.
The score is reproducible (same input, same output): no LLM, no randomness.
The field hierarchy
Four fields, four jobs, so you read the right one for your use:
| Field | Meaning |
|---|---|
confidenceScore | the internal 0-1 number (for sorting / thresholds) |
confidenceLevel | the human-readable band (high / medium / low) |
ambiguous | a risk factor: was the name itself unclear? |
safeToAutomate | the operational decision: pass it through unattended, or not |
Most pipelines branch on safeToAutomate. Analysts read confidenceLevel. Dashboards sort on confidenceScore.
Why deterministic matters
The scoring path uses no LLM and no randomness, which is the point:
- Same input, same output. Re-run the same name list and you get identical domains, scores, and decisions.
- No hallucinated confidence. Every score traces to SERP rank, name-token match, and SERP composition. You can audit it in
confidenceBreakdown. - Safe for retries and caching. Because output is reproducible, a workflow can cache resolutions, retry idempotently, and trust that a re-run won't silently change a decision.
This is what makes it a pre-enrichment firewall: a deterministic gate that stops bad or ambiguous domains before they reach expensive downstream steps (email scrapers, enrichers, verification APIs, outreach systems), so you don't pay to scrape the wrong company.
Operational characteristics
- Up to 5,000 names per run, charged per query, not per result
- Deduped at the domain level (one row per unique website)
- Deterministic scoring (no LLM latency, no model variability)
- Stateless execution (no cross-run state to manage or reset)
- Block/CAPTCHA pages are never charged
Fields to branch on
| Field | Type | Meaning | Stable for branching |
|---|---|---|---|
safeToAutomate | boolean | Our default: high confidence, not ambiguous | Yes |
policyResult.passed | boolean | Your policy passed (resolutionProfile / automationPolicy) | Yes |
recommendedAction | enum | auto-enrich / verify / retry / skip | Yes |
confidenceLevel | enum | high / medium / low | Yes |
ambiguous | boolean | Multiple viable entities for the name | Yes |
candidateGap.weakWinner | boolean | Winner barely beat the runner-up | Yes |
recordType | enum | domain / unresolved / error | Yes |
failureType | enum | Why an input didn't resolve | Yes |
Stable enums
These values are additive across minor versions (new values may appear; existing ones are never renamed or repurposed), so they are safe to branch on.
recordType:domain,unresolved,errorrecommendedAction:auto-enrich,verify,retry,skipconfidenceLevel:high,medium,lowfailureType:no-data,directory-only,geo-mismatch,blocked,invalid-inputserpEnvironment:clean,mixed,noisyreasonCodes:TOP_RANK,STRONG_NAME_MATCH,LOW_DOMAIN_MATCH,SERP_DIRECTORY_HEAVY,GENERIC_ENTITY,PHRASE_DISCOVERY,DIRECTORY_ONLY,GEO_MISMATCH,NO_RESULTS,BLOCKEDrejectedCandidates[].reason:social-host,directory,region-filtered,lower-ranked
Example
Input:
Output (one record per unique domain, plus any unresolved inputs):
(confidenceBreakdown, rejectedCandidates, actorGraph, and discoveredAt fields omitted above for brevity: every domain row carries them.)
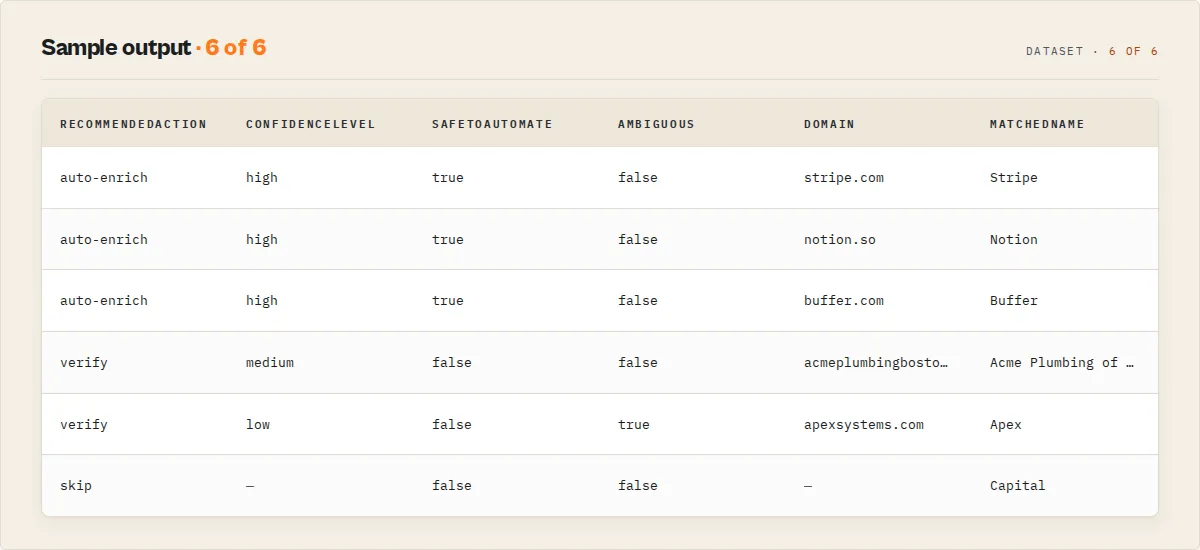
Cost for this run: 4 queries × $0.0075 = $0.03.
Minimal examples
Safe resolution:
Ambiguous resolution:
Policy failure:
Quick answers
How do I convert a list of company names into website URLs?
Paste the names into knownNames and run the actor. Each name is searched on Google and the top organic result that survives filtering becomes that company's website, with a confidence level attached.
How do I find a company's website from just its name?
That is exactly what this actor does. For a single branded name (e.g. Stripe) you get a high-confidence domain at rank 1. For generic names, add a nameSuffix (like "plumbing" or "insurance") to disambiguate.
Can I turn a CRM export of company names into domains in bulk?
Yes. The actor takes up to 5,000 names per run, charges per query, and returns one row per resolved domain plus unresolved rows for the ones it couldn't find, so you can re-work or skip them.
How do I know which resolved URLs are correct?
Filter by confidenceLevel. high rows matched both SERP rank and the company name; verifyBeforeUse: true rows should be spot-checked before you spend downstream budget on them.
What happens to names it can't resolve?
They come back as recordType: "unresolved" with a failureType (no-data or blocked) and a plain-English reason telling you what to try next. Nothing is dropped silently.
How do I find websites for businesses that use a specific marketing phrase?
Put the phrase in footerPhrases (e.g. "we buy land in any state"). It runs as an exact-match Google query and collects every organic result, useful for niche operator and competitor discovery.
Which rows can I pass straight into an automated pipeline without review?
The ones where safeToAutomate is true. That flag is true only when confidence is high and the name wasn't ambiguous, so a Zapier/Make/n8n filter on safeToAutomate == true gives you the rows you can scrape or enrich unattended; everything else routes to review.
Can I exclude specific sites from the results?
Yes. The actor already drops social and directory hosts automatically; add your own (a known partner, parent company, or niche aggregator) via the excludeDomains input.
AI-agent contract
The actor is designed to be safe for autonomous workflows and AI agents because every routing signal is deterministic, structured, and machine-readable.
- Inputs: company names, business names, footer/marketing phrases.
- Outputs: canonical domains, candidate entities, routing decisions, reason codes.
- Branch-safe fields:
policyResult.passed,safeToAutomate,recommendedAction,failureType. - Deterministic guarantees: same input = same output; no LLM scoring; stable, additive-only enums; reproducible confidence (safe for caching and idempotent retries).
- Chaining:
actorGraph.nextnames the recommended next actor (ryanclinton/website-contact-scraper), so a long-running agent chains the pipeline without re-deciding each step.
It is the first tool to reach for when an agent has a name but needs the website before it can scrape, enrich, or verify: one call replaces an open-ended web search plus manual disambiguation.
When it works well — and when it doesn't
Works well:
- Specific, branded company names (e.g. Stripe, Twilio, Acme Plumbing of Boston)
- Distinctive marketing/footer phrases that locate operators ("we buy land in any state", "24-hour mobile mechanic")
- Names paired with
nameSuffixfor category disambiguation (e.g. Apex + suffix"plumbing")
Lower hit rate / verify before use:
- Generic single-word names ("Capital", "Acme"): top SERP result is rarely the company you mean (these score
lowand flagverifyBeforeUse) - Franchise / multi-location brands: Google may return a regional listing or a directory above the corporate site
- Industries dominated by directories (legal, healthcare, real-estate aggregators): corporate sites get pushed below G2/Yelp/Zillow-style hosts; the directory blocklist mitigates but doesn't eliminate
- Foreign-language names searched in the wrong country code
The confidence score is built for exactly this: trust the high rows, spot-check the rest.
Why a row becomes safeToAutomate: false
| Example query | What happens | Field that flags it |
|---|---|---|
Apex | Many competing brands own the name | ambiguous: true |
Capital | Generic word, top result rarely the company you mean | confidenceLevel: low |
Smith Plumbing | SERP dominated by directories (Yelp, Angi) | confidenceBreakdown.serpEnvironment: noisy |
Acme (searched with country: UK) | Real site exists on a .com excluded by the UK TLD filter | unresolved, failureType: geo-mismatch |
In each case the actor tells you why rather than handing you a confident wrong answer.
Ambiguous names: see the candidates, don't guess
When a name is ambiguous (several real companies own it), the actor still picks a best result, but it also returns candidateEntities — the scored alternatives. An agent or automation rule can then apply its own policy (e.g. "only proceed if the top candidate leads the next by 0.2") instead of trusting a single forced pick:
Define your own "safe" (trust policy)
safeToAutomate is our default opinion. Different workflows tolerate different risk: cold outreach wants near-zero false positives, competitor discovery happily accepts noise. Set a resolutionProfile (conservative / balanced / aggressive) or a custom automationPolicy, and every row gets a policyResult against your rules:
→ each row returns "policyResult": { "passed": false, "failedRules": ["noisy-serp-not-allowed"], "profile": "custom" }. Branch your pipeline on policyResult.passed to enforce your own bar. This only changes the pass/fail evaluation; it never changes scraping behaviour or cost.
Example policies:
- Conservative outreach:
{ "minimumConfidenceScore": 0.9, "allowAmbiguous": false }(orresolutionProfile: "conservative") - Broad competitor discovery:
{ "minimumConfidenceScore": 0.4, "allowAmbiguous": true }(orresolutionProfile: "aggressive")
De-duplicating company-name lists
CRM exports are messy: Stripe, Stripe Inc, and Stripe Payments are one company. When several input names resolve to the same domain, the resolved row's aliases lists the variants, and entityFingerprint.entityId gives a stable hash you can group on. That collapses a noisy name list into deduped entities in one pass.
Country / TLD filtering
country controls two things at once:
- Google country code (
gl=): biases SERP rankings toward that country. - TLD whitelist: domains that don't match the country's TLDs are dropped.
country | TLDs kept |
|---|---|
US | .com, .net, .org, .us, .co |
UK | .co.uk, .uk |
CA | .ca |
AU | .com.au, .au |
EU | .eu, .de, .fr, .es, .it, .nl, .be, .pl, .se, .dk, .fi, .ie, .pt, .at, .cz |
Pick the country that matches the bulk of your list: UK/CA/AU exclude .com, so a mixed UK list with .com results will lose those rows. For mixed regions, US is the loosest filter but biases SERP rankings toward US results. (EU filters by TLD only; Google has no single eu country code, so no country bias is applied for that group.)
How it works
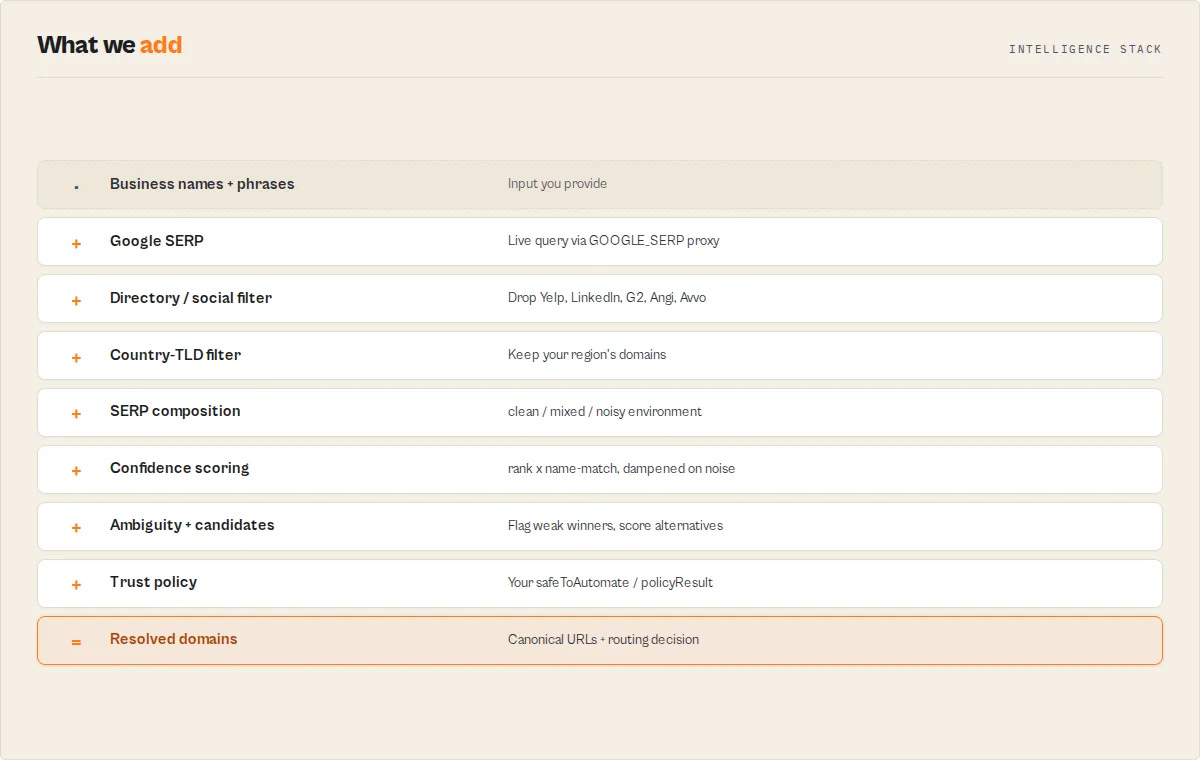
- Each
knownNamesentry is searched on Google as<name> <nameSuffix>. The top organic result that survives filtering is treated as that company's website. - Each
footerPhrasesentry is searched verbatim (exact-match). Every organic result on the SERP is collected. - Results are deduped, filtered to your country's TLDs, scored for confidence, sorted best-first, and capped at
maxDomains.
Uses Apify Proxy GOOGLE_SERP group by default, designed for Google scraping and handling rotation and CAPTCHA. If Google blocks the whole run, a circuit breaker stops it early rather than burning queries.
Pricing
Pay-per-event: $0.0075 per query executed ($7.50 per 1,000). A query is one name or one phrase. 100 names + 5 phrases = 105 queries = $0.79.
You are charged per query, not per result, so you pay the same whether a query returns 50 results or zero. Block/CAPTCHA pages are not charged: the actor only bills a query once it confirms a real Google results page came back.
Use cases
- Feeding Website Contact Scraper with a list of names instead of URLs (most common)
- Building a domain list from competitor footer phrases
- Resolving a CRM export of company names to verified websites
- Niche buyer/operator discovery (real estate cash buyers, junk car buyers, contractor franchises, etc.)
Who uses it
RevOps teams, lead-enrichment pipelines, AI research agents, CRM-normalization workflows, SDR automation, and any website-discovery step that runs before scraping.
Typical pipeline
Use in Dify
Drop this actor into Dify workflows via the Apify plugin's Run Actor node. Every resolved row returns scored and classified as structured JSON: confidenceLevel (high / medium / low), a verifyBeforeUse boolean, and a recordType discriminator (domain / unresolved) your downstream if/else node branches on. A generic Google scraper returns raw SERP HTML; this returns a routing decision per name.
- Actor ID:
ryanclinton/serp-name-resolver - Sample input (resolve a CRM export of company names to websites):
- Branching example — a Dify if/else node routes each record on one boolean:
safeToAutomate == true→ passurlstraight to the Website Contact Scraper Run Actor nodesafeToAutomate == false(low confidence orambiguous) → send to a human-review / manual-check branch firstrecordType == "unresolved"→ route byfailureType(blocked→ retry node;directory-only→ skip;no-data→ re-query with anameSuffix;geo-mismatch→ switch country)
Because every domain record carries actorGraph.next (pointing at ryanclinton/website-contact-scraper), the chaining target is a field read, not hard-coded wiring. The actor never calls an LLM in its scoring path, so the confidenceLevel / verifyBeforeUse values are reproducible and safe to branch on.
What this does NOT do
This actor resolves a business name or phrase to a website URL. It is the discovery step, not the enrichment step. For everything downstream, use the sibling actor:
| Need | Use this instead |
|---|---|
| Scrape contacts (emails, phones, names) from the resolved sites | Website Contact Scraper |
| Verify deliverability of found emails | Bulk Email Verifier |
| Guess email format for a domain | Email Pattern Finder |
| Score and qualify the resulting leads | Lead Scoring Engine |
Every domain record carries an actorGraph.next pointer to the website contact scraper, so you can chain the pipeline in Make, n8n, or Dify by reading one field. It does not scrape the resolved sites, validate emails, or rank companies. Resolution confidence tells you which URLs are safe to spend downstream budget on; verifyBeforeUse: true rows are the ones to check first.
Unlike commercial enrichment databases (Clearbit, ZoomInfo, Apollo) that match names against a licensed company dataset, this resolves names live against Google's index. That means it finds long-tail and local businesses those databases miss, but it returns a website URL rather than firmographic data, and it tells you its confidence so you can verify the edge cases yourself.
Summary
The Business Name & Phrase to URL Resolver is a deterministic company website resolver for Apify. It converts company names and distinctive marketing phrases into canonical website domains with deterministic confidence scoring, ambiguity detection, scored candidate entities, machine-readable reason codes, and policy-based automation decisions. It is built for AI agents, lead-enrichment pipelines, CRM normalization, and workflow-safe scraping automation, and acts as a pre-enrichment firewall that stops bad or ambiguous domains before they reach downstream scraping, verification, or outreach. The scoring path uses no LLM and no randomness, so the same input always produces the same output.