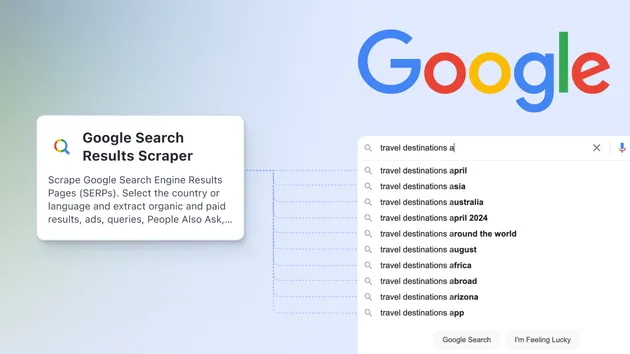
Google Search Videos Scraper
Pricing
$4.00/month + usage
Go to Apify Store
Google Search Videos Scraper
This Google Search Videos Scraper enables you to scrape Google Search Engine Results Pages (SERPs) for videos result. Select a country or language, extract custom attributes, and download your data; no coding is needed.