Facebook Ads Library Scraper
Pricing
from $3.40 / 1,000 ads
Facebook Ads Library Scraper
Extract advertising data from Facebook, Instagram, WhatsApp, Threads. Get ads, publishers, prices, reach estimates, impressions, links, images, IDs, timestamps, product info, and more from Facebook Ad Library. Export ad data, schedule runs via API, and integrate with other tools or AI workflows.
Pricing
from $3.40 / 1,000 ads
Rating
4.3
(55)
Developer
Apify
Maintained by ApifyActor stats
437
Bookmarked
30K
Total users
4.5K
Monthly active users
1.2 days
Issues response
10 hours ago
Last modified
Categories
Share
📢 New: e-commerce data enrichment, powered by Facebook Ads Library Scraper × E-commerce Scraping Tool.
🛍️ With this add-on, you can now extract the products and prices behind each ad, not only the ad data itself to combine competitor ad research, product research, and pricing intelligence in a single run.
What can Facebook Ads Library Scraper do?
Facebook Ads Library Scraper extracts data from the Meta Ad Library across multiple Meta platforms beyond what official APIs provide. Add one or multiple Facebook page URLs or Facebook Ads Library URLs, and you can:
🧩 Scrape ads published across Meta platforms, including Facebook, Instagram, WhatsApp, Threads, Messenger, and Audience Network
🔎 Prefilter ads by brand, keyword, country, language, media type, status (active or inactive), ad type (product, political, housing), and creative format
📅 Refine ads before scraping with date filters, sorting (default, impressions high to low, or most recent), and active status (active or inactive) — for cleaner, cheaper runs
🏢 Get advertiser transparency signals from the Facebook Ads Library About page, including business address, admin countries and counts, and page creation/merging or name change history
🌍 Track ad performance across countries, languages, and brands to compare regional strategies and localization efforts
🎨 Analyze and reuse complete ad creatives, including images, videos, carousels, memes, ad copy, and CTA links
🛒 Enrich ads with the products and prices behind them, more details
⬇️ Export ad data in JSON, CSV, Excel, or XML
🦾 Access the ad data programmatically via API endpoints, SDKs (Python & Node.js), and webhooks
Add Facebook Ads Library Scraper to your ad research and transparency toolkit to support competitor monitoring, content strategy optimization, benchmarking, performance analysis, and regulatory reporting.
What Facebook and Instagram ad data can I extract?
With this Meta Ads API, you will be able to extract the following ad data from Meta platforms:
🏢 Page & advertiser data
| 📝 Page name, ID, alias, category, verification status | 🔗 Page URL & profile links |
| 📊 Page metrics (likes, Instagram followers) | 📸 Page profile & cover images |
| 🧑💼 Page owner & transparency info | 🏢 Advertiser's business address and phone |
| 🌍 Page admin locations by country | 🧮 Page admin count per country |
| 📅 Page creation date & name change history |
🛍 Ad data
| 🛍 Ad text & messaging | 🏷 Ad category & type (e.g. product, political, social issue) |
| 🎨 Ad creatives (images, videos, carousels) | 🖼 Creative variants & display format |
| 🖱 CTA text & CTA type | 🔗 Destination links (when available) |
| 📢 Publisher platforms (Facebook, Instagram, WhatsApp, Threads, Audience Network) | 🌐 Language & country signals (when available) |
| ⏱ Ad start & end dates | 📅 Visibility timeframe & activity history |
| 💸 Ad spend data & currency (when available) | 👀 Reach & impression estimates (when available) |
| 🧮 Report count & user reports | 🚦 Ad status (active/inactive) |
| 📦 Branded content & partner page details | 🔎 Compliance, eligibility & safety flags |
🛒 E-commerce enrichment (add-on)
| 🛒 Product name & URL | 💲 Product price & currency |
| 🏷 Product brand | 🖼 Product image |
| 📄 Product description | ⭐ Product rating & review count |
Enrich ads with product and pricing data 🛍️
With the new e-commerce add-on, Facebook Ads Library Scraper doesn't stop at the ad — it follows the destination link and pulls the actual products and prices behind each ad. The enrichment is powered by the E-commerce Scraping Tool, which extracts data from almost any retail site, marketplace, or delivery platform.
On top of the standard ad data, you can capture:
- 🏷 Product details — name, product description, brand, product URL
- 💲 Pricing — current price and currency
- ⭐ Reviews & ratings — number of reviews and current rating
- 🖼️ Images of the extracted product
This turns a single run into competitor ad research, product research, and pricing intelligence at once — ideal for price monitoring, catalog and offer comparison, and market mapping. See the E-commerce Scraping Tool for the full list of supported data and sites.
How much will scraping ads data from Facebook or Instagram cost you?
Facebook Ads Library Scraper uses a pay-per-result (PPR) pricing model, where one result equals one ad campaign. On the Free plan, it costs $5.80 per 1,000 ads, with no discount applied.
Paid plans offer discounted rates and higher monthly credit. For example, the Starter plan charges $5.00 per 1,000 ads, which allows you to scrape 7,800 ads per month. The Scale and Business plans reduce the price to $4.20 with 47,000 ads per month, and $3.40 with 300,000 ads per month, respectively.
The e-commerce enrichment add-on is billed per 1,000 enriched ads, on top of the ad price, and only when you turn it on. On the Free plan it costs $5.70 per 1,000, and the Starter plan drops it to $3.20 per 1,000 — with bigger discounts on higher plans. Check the pricing tab for full details.
How do I use Facebook Ad Library Scraper?
Facebook Ads Library Scraper was designed to be easy to start with, even if you've never extracted data from the web before. Here's how you can scrape data from the Facebook Ads Library with this tool:
- Create a free Apify account using your email.
- Open Facebook Ad Library Scraper.
- Add a Facebook Page URL to scrape ads from.
- Alternatively, head over to the Facebook Ad Library. Choose the country, advertisement category, and brand name or keyword.
- Filter the results by platform, language, activity, media type, timeframe, or even audience size before scraping them. Copy the URL to the scraper.
- Click "Start" and wait for the data to be extracted.
- Download your data though API or in JSON, XML, CSV, Excel, HTML.
For a step-by-step guide on how to scrape Facebook Ads, follow our tutorial 📝 or this video guide
Please note that this scraper displays the extracted results only at the very end of the run. The rest of the time it will display 0 results. Please be patient to see all the extracted data.
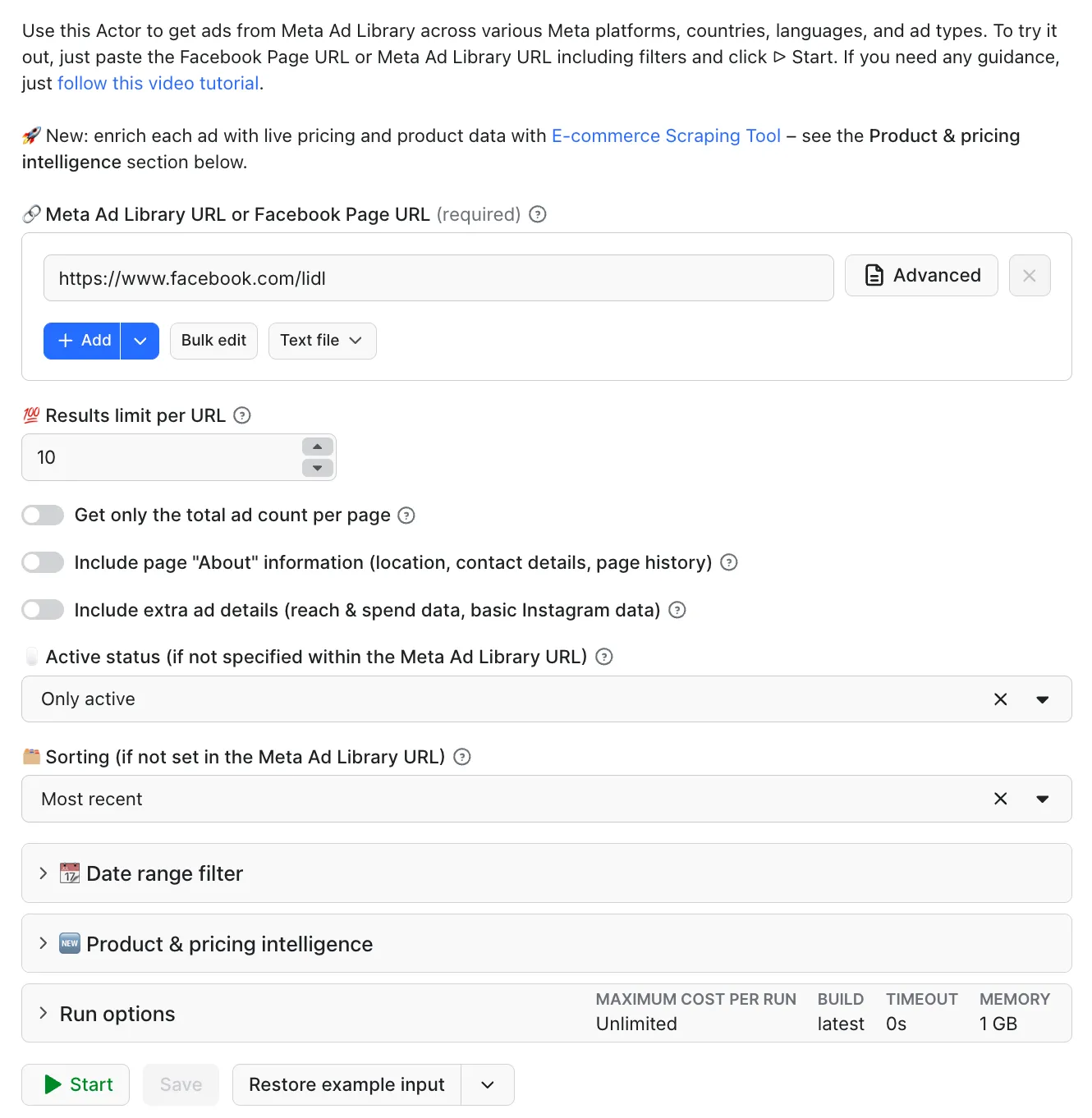
⬇️ Input
Enter either a Facebook page URL or a Facebook Ads Library URL of a brand or an ad.
To scrape Facebook Ads, the input should be either:
- URLs of brands or ads taken directly from Facebook Ads Library, such as
https://www.facebook.com/ads/library/?active_status=active&ad_type=all&content_languages[0]=en&country=ALL&is_targeted_country=false&media_type=image&publisher_platforms[0]=instagram&publisher_platforms[1]=facebook&search_type=page&view_all_page_id=15087023444.- Before you copy&paste this type of URL, don't forget to include various settings, platforms, keywords, or filters available in Facebook Ads Library.
- Alternatively, you can add one or more Facebook page URLs to scrape the ads from, such as
SHEINOFFICIAL - Additionally, choose active or inactive ads, whether to scrape the ad details.
You can input URLs individually or in bulk using the Bulk edit function. You can also input data manually via the UI, JSON, or programmatically via an API. Click on the input tab for a full explanation of input in JSON.
⬆️ Output
Your Facebook Ads Library results will appear in a dataset in the Storage tab. You can view them as a table, download in JSON, CSV, Excel, or XML, or use API endpoints.
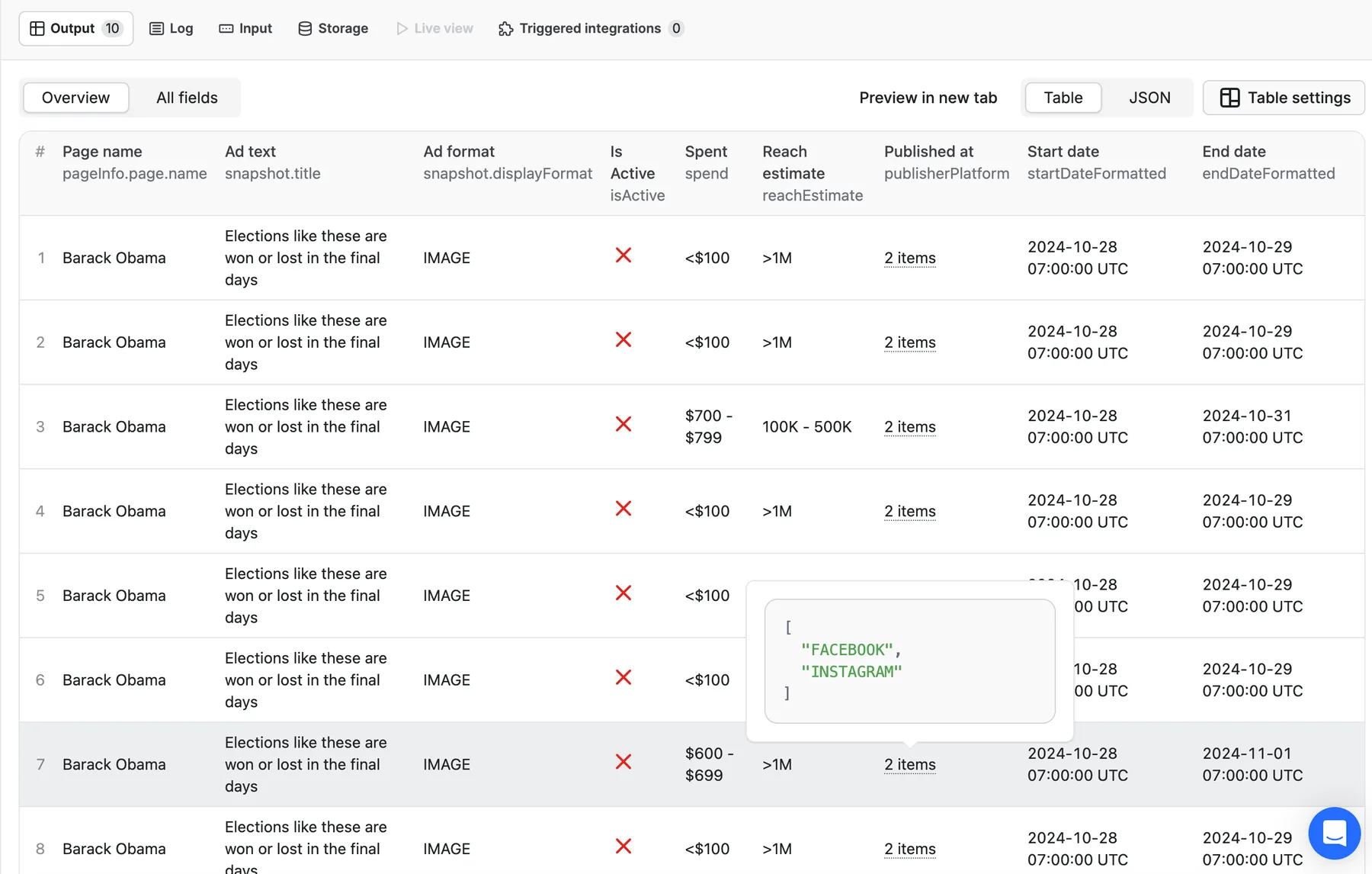
Besides the table view, you can also view your data as JSON, as well as download it as CSV, XML, Excel file, or through an API.
🛍️ Meta ad data sample
Please note that
startDateandendDate(if available) will be added as formatted ISO values asstartDateFormatted: "2026-02-12T07:00:00.000Z" andendDateFormatted: "2026-02-12T07:00:00.000Z"
🛍️ E-commerce enrichment data sample
When the e-commerce enrichment add-on is enabled, each ad's destination is followed to extract the products and prices behind it, returned under ecommerceData:
Want to scrape Facebook comments or groups?
You can use the dedicated scrapers below if you want to scrape specific Facebook data. Each of them is built particularly for the relevant Facebook or Instagram scraping case, be it posts, comments, reels, or search results. Feel free to browse them:
❓FAQ
Is it legal to scrape Facebook Ads data?
Our Facebook Ads Library Scraper only collects data that is publicly available in the Facebook Ad Library. It does not access private content or extract sensitive user information such as email addresses or precise location. You should be aware that some public data may still be considered personal data under regulations like the GDPR. Only scrape data if you have a legitimate reason. For more context, see our blog posts on the legality of web scraping and ethical web scraping.
Why is my ecommerceData showing null?
We only enrich URLs that are actual product pages. If an ad leads somewhere else — for example, a sign-up or landing page — we skip the enrichment to save you money when the add-on is enabled. So a null value most likely means the ad's destination wasn't a product URL.
To check, look into the snapshot field: it contains cards → linkUrl, the link that leads from the ad to its destination page. Open that link and you'll see whether it's a product page or not. If you're convinced it is a product page but still aren't getting your e-commerce data, please open an issue on the Issues tab.
Can I integrate Facebook Ads data with other services?
Yes. Scraped ads data can be integrated with almost any cloud service or web app. Apify supports Make, Zapier, n8n, Slack, Airbyte, Asana, GitHub, Google Sheets, Google Drive, and more. You can also use webhooks to trigger actions when a run finishes, such as sending notifications or syncing results to another system.
Can I access Meta Ads data through an MCP server?
Yes. You can connect your scraped Instagram or Facebook ads to an MCP server using clients like ClaudeDesktop or LibreChat, or build your own integration. For Facebook Ads Library Scraper:
- Start a Server-Sent Events (SSE) session to receive a
sessionId. - Send API messages using that
sessionIdto trigger the scraper. - The message starts the Facebook Ads Library Scraper with the provided input.
- The response should be: Accepted.
Learn more in the MCP setup guide.
Can I use the Facebook Ads Library Scraper with API?
Yes. The Apify API provides programmatic access to run Actors, fetch datasets, monitor performance, and manage versions and schedules. For Node.js, use the apify-client NPM package. For Python, use the apify-client PyPI package. Full details are available in the Apify API reference, or check the API tab for ready-to-use code examples.
Facebook Ads Library Scraper not working
The Apify team continuously improves Actor performance. If you run into technical issues or find a bug, please create an issue on the Actor’s Issues tab in Apify Console.