RAG Web Browser
Pricing
Pay per usage
RAG Web Browser
Web search and fetch tool for AI agents and RAG pipelines. It queries Google Search, scrapes the top N pages using a full web browser, and returns their content as clean Markdown for further processing by an LLM. Can also fetch individual URLs.
Pricing
Pay per usage
Rating
4.1
(27)
Developer
Apify
Maintained by ApifyActor stats
253
Bookmarked
133K
Total users
27K
Monthly active users
a month ago
Last modified
Categories
Share
🌐 RAG Web Browser
This Actor provides web browsing functionality for AI agents and LLM applications, similar to the web browsing feature in ChatGPT. It accepts a search phrase or a URL, queries Google Search, then crawls web pages from the top search results, cleans the HTML, converts it to text or Markdown, and returns it back for processing by the LLM application. The extracted text can then be injected into prompts and retrieval augmented generation (RAG) pipelines, to provide your LLM application with up-to-date context from the web.
Main features
- 🚀 Quick response times for great user experience
- ⚙️ Supports dynamic JavaScript-heavy websites using a headless browser
- 🔄 Flexible scraping with Browser mode for complex websites or Plain HTML mode for faster scraping
- 🕷 Automatically bypasses anti-scraping protections using proxies and browser fingerprints
- 📝 Output formats include Markdown, plain text, and HTML
- 🔌 Supports OpenAPI and MCP for easy integration
- 🪟 It's open source, so you can review and modify it
Example
For a search query like fast web browser in RAG pipelines, the Actor will return an array with a content of top results from Google Search, which looks like this:
If you enter a specific URL such as https://openai.com/index/introducing-chatgpt-search/, the Actor will extract
the web page content directly like this:
⚙️ Usage
The RAG Web Browser can be used in two ways: as a standard Actor by passing it an input object with the settings, or in the Standby mode by sending it an HTTP request.
See the Performance Optimization section below for detailed benchmarks and configuration recommendations to achieve optimal response times.
Normal Actor run
You can run the Actor "normally" via the Apify API, schedule, integrations, or manually in Console. On start, you pass the Actor an input JSON object with settings including the search phrase or URL, and it stores the results to the default dataset. This mode is useful for testing and evaluation, but might be too slow for production applications and RAG pipelines, because it takes some time to start the Actor's Docker container and a web browser. Also, one Actor run can only handle one query, which isn't efficient.
Standby web server
The Actor also supports the Standby mode, where it runs an HTTP web server that receives requests with the search phrases and responds with the extracted web content. This mode is preferred for production applications, because if the Actor is already running, it will return the results much faster. Additionally, in the Standby mode the Actor can handle multiple requests in parallel, and thus utilizes the computing resources more efficiently.
To use RAG Web Browser in the Standby mode, simply send an HTTP GET request to the following URL:
where <APIFY_API_TOKEN> is your Apify API token.
Note that you can also pass the API token using the Authorization HTTP header with Basic authentication for increased security.
The response is a JSON array with objects containing the web content from the found web pages, as shown in the example above.
Query parameters
The /search GET HTTP endpoint accepts all the input parameters described on the Actor page. Object parameters like proxyConfiguration should be passed as url-encoded JSON strings.
🔌 Integration with LLMs
RAG Web Browser has been designed for easy integration with LLM applications, GPTs, OpenAI Assistants, and RAG pipelines using function calling.
OpenAPI schema
Here you can find the OpenAPI 3.1.0 schema
or OpenAPI 3.0.0 schema
for the Standby web server. Note that the OpenAPI definition contains
all available query parameters, but only query is required.
You can remove all the others parameters from the definition if their default value is right for your application,
in order to reduce the number of LLM tokens necessary and to reduce the risk of hallucinations in function calling.
OpenAI Assistants
While OpenAI's ChatGPT and GPTs support web browsing natively, Assistants currently don't. With RAG Web Browser, you can easily add the web search and browsing capability to your custom AI assistant and chatbots. For detailed instructions, see the OpenAI Assistants integration in Apify documentation.
OpenAI GPTs
You can easily add the RAG Web Browser to your GPTs by creating a custom action. Here's a quick guide:
- Go to My GPTs on ChatGPT website and click + Create a GPT.
- Complete all required details in the form.
- Under the Actions section, click Create new action.
- In the Action settings, set Authentication to API key and choose Bearer as Auth Type.
- In the schema field, paste the OpenAPI 3.1.0 schema of the Standby web server HTTP API.
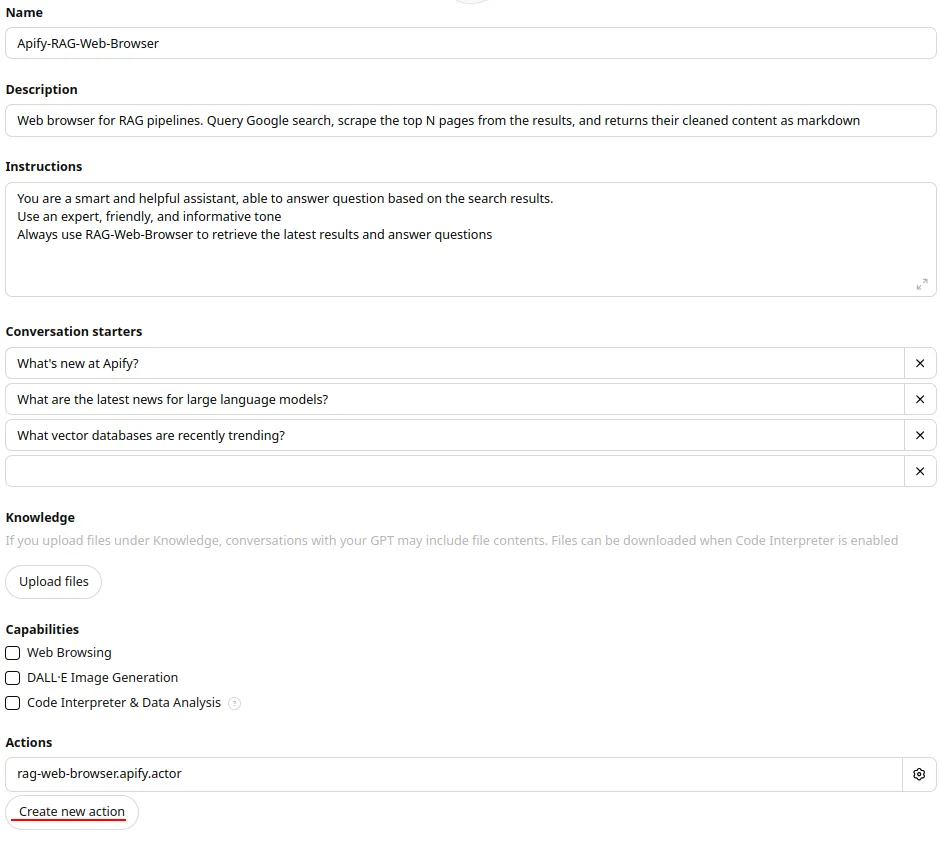
Learn more about adding custom actions to your GPTs with Apify Actors on Apify Blog.
Anthropic: Model Context Protocol (MCP) Server
The RAG Web Browser Actor can also be used as an MCP server and integrated with AI applications and agents, such as Claude Desktop. For example, in Claude Desktop, you can configure the MCP server in its settings to perform web searches and extract content. Alternatively, you can develop a custom MCP client to interact with the RAG Web Browser Actor.
In the Standby mode, the Actor runs an HTTP server that supports the MCP protocol via SSE (Server-Sent Events).
-
Initiate SSE connection:
curl https://rag-web-browser.apify.actor/sse?token=<APIFY_API_TOKEN>On connection, you'll receive a
sessionId:event: endpointdata: /message?sessionId=5b2 -
Send a message to the server by making a POST request with the
sessionId,APIFY-API-TOKENand your query:curl -X POST "https://rag-web-browser.apify.actor/message?session_id=5b2&token=<APIFY-API-TOKEN>" -H "Content-Type: application/json" -d '{"jsonrpc": "2.0","id": 1,"method": "tools/call","params": {"arguments": { "query": "recent news about LLMs", "maxResults": 1 },"name": "rag-web-browser"}}'For the POST request, the server will respond with:
Accepted -
Receive a response at the initiated SSE connection: The server invoked
Actorand its tool using the provided query and sent the response back to the client via SSE.event: messagedata: {"result":{"content":[{"type":"text","text":"[{\"searchResult\":{\"title\":\"Language models recent news\",\"description\":\"Amazon Launches New Generation of LLM Foundation Model...\"}}
You can try the MCP server using the MCP Tester Client available on Apify. In the MCP client, simply enter the URL https://rag-web-browser.apify.actor/sse in the Actor input field and click Run and interact with server in a UI.
To learn more about MCP servers, check out the blog post What is Anthropic's Model Context Protocol.
⏳ Performance optimization
To get the most value from RAG Web Browsers in your LLM applications, always use the Actor via the Standby web server as described above, and see the tips in the following sections.
Scraping tool
The most critical performance decision is selecting the appropriate scraping method for your use case:
-
For static websites: Use
scrapingTool=raw-httpto achieve up to 2x faster performance. This lightweight method directly fetches HTML without JavaScript processing. -
For dynamic websites: Use the default
scrapingTool=browser-playwrightwhen targeting sites with JavaScript-rendered content or interactive elements
This single parameter choice can significantly impact both response times and content quality, so select based on your target websites' characteristics.
Request timeout
Many user-facing RAG applications impose a time limit on external functions to provide a good user experience. For example, OpenAI Assistants and GPTs have a limit of 45 seconds for custom actions.
To ensure the web search and content extraction is completed within the required timeout,
you can set the requestTimeoutSecs query parameter.
If this timeout is exceeded, the Actor makes the best effort to return results it has scraped up to that point
in order to provide your LLM application with at least some context.
Here are specific situations that might occur when the timeout is reached:
- The Google Search query failed => the HTTP request fails with a 5xx error.
- The requested
queryis a single URL that failed to load => the HTTP request fails with a 5xx error. - The requested
queryis a search term, but one of target web pages failed to load => the response contains at least thesearchResultfor the specific page contains a URL, title, and description. - One of the target pages hasn't loaded dynamic content (within the
dynamicContentWaitSecsdeadline) => the Actor extracts content from the currently loaded HTML
Reducing response time
For low-latency applications, it's recommended to run the RAG Web Browser in Standby mode with the default settings, i.e. with 8 GB of memory and maximum of 24 requests per run. Note that on the first request, the Actor takes a little time to respond (cold start).
Additionally, you can adjust the following query parameters to reduce the response time:
scrapingTool: Useraw-httpfor static websites orbrowser-playwrightfor dynamic websites.maxResults: The lower the number of search results to scrape, the faster the response time. Just note that the LLM application might not have sufficient context for the prompt.dynamicContentWaitSecs: The lower the value, the faster the response time. However, the important web content might not be loaded yet, which will reduce the accuracy of your LLM application.removeCookieWarnings: If the websites you're scraping don't have cookie warnings or if their presence can be tolerated, set this tofalseto slightly improve latency.debugMode: If set totrue, the Actor will store latency data to results so that you can see where it takes time.
Cost vs. throughput
When running the RAG Web Browser in Standby web server, the Actor can process a number of requests in parallel. This number is determined by the following Standby mode settings:
- Max requests per run and Desired requests per run - Determine how many requests can be sent by the system to one Actor run.
- Memory - Determines how much memory and CPU resources the Actor run has available, and this how many web pages it can open and process in parallel.
Additionally, the Actor manages its internal pool of web browsers to handle the requests. If the Actor memory or CPU is at capacity, the pool automatically scales down, and requests above the capacity are delayed.
By default, these Standby mode settings are optimized for quick response time:
8 GB of memory and maximum of 24 requests per run gives approximately ~340 MB per web page.
If you prefer to optimize the Actor for the cost, you can Create task for the Actor in Apify Console
and override these settings. Just note that requests might take longer and so you should
increase requestTimeoutSecs accordingly.
Benchmark
Below is a typical latency breakdown for RAG Web Browser with maxResults set to either 1 or 3, and various memory settings.
These settings allow for processing all search results in parallel.
The numbers below are based on the following search terms: "apify", "Donald Trump", "boston".
Results were averaged for the three queries.
| Memory (GB) | Max results | Latency (sec) |
|---|---|---|
| 4 | 1 | 22 |
| 4 | 3 | 31 |
| 8 | 1 | 16 |
| 8 | 3 | 17 |
Please note the these results are only indicative and may vary based on the search term, target websites, and network latency.
💰 Pricing
The RAG Web Browser is free of charge, and you only pay for the Apify platform consumption when it runs. The main driver of the price is the Actor compute units (CUs), which are proportional to the amount of Actor run memory and run time (1 CU = 1 GB memory x 1 hour).
ⓘ Limitations and feedback
The Actor uses Google Search in the United States with English language, and so queries like "best nearby restaurants" will return search results from the US.
If you need other regions or languages, or have some other feedback, please submit an issue in Apify Console to let us know.
👷🏼 Development
The RAG Web Browser Actor has open source available on GitHub, so that you can modify and develop it yourself. Here are the steps how to run it locally on your computer.
Download the source code:
Install Playwright with dependencies:
And then you can run it locally using Apify CLI as follows:
Server will start on http://localhost:3000 and you can send requests to it, for example: