Competitor Hiring Intelligence Scraper
Pricing
from $1.80 / 1,000 competitor-job-results
Competitor Hiring Intelligence Scraper
Monitor public competitor hiring from career pages and job listings. Returns one flat row per job with competitor name, role category, seniority, location, work mode, ATS platform, a transparent hiring-signal score, and reason tags. No login or cookies.
Pricing
from $1.80 / 1,000 competitor-job-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share

Monitor public competitor hiring from career pages and public job listings. For each competitor you get one flat, CSV-ready row per job posting: title, department, role category, seniority, location, work mode, ATS platform, a transparent hiring-signal score (0–100), and explainable reason tags.
Built for competitor research, sales intelligence, recruiting, and market research teams who want competitor-level hiring signals — not just a raw job dump — without login, cookies, residential proxy, or expensive enrichment APIs.
- ✅ No login, no cookies, no API keys. Public data only, over HTTP.
- ✅ One row per unique job posting, with derived hiring intelligence.
- ✅ Transparent, non-AI scoring you can audit field-by-field.
- ✅ Reliable extraction via public ATS JSON APIs (Greenhouse, Lever, Ashby, SmartRecruiters, Recruitee, Workable), schema.org JSON-LD, and a careers-page HTML fallback.
What it does
For every competitor the actor:
- Resolves a careers/listing source — a direct
careerUrl, or shallow discovery fromwebsiteUrl(common paths like/careers,/jobs,/join-us). - Extracts visible job postings (public ATS JSON first, then JSON-LD, then a conservative HTML fallback).
- Derives per-job fields: role category, seniority, work mode, country/region, department.
- Scores a transparent
hiring_signal_scoreand tags the reasons behind it. - Filters, deduplicates, and emits one flat row per unique job, capped per competitor and globally.
It does not do login/session scraping, deep crawling, contact/email enrichment, AI summaries, or historical tracking (see Future Features in the PRD).
Input
| Field | Type | Default | Description |
|---|---|---|---|
competitors | array of objects | [] | Each { companyName, careerUrl, websiteUrl }. At least one required; each needs a careerUrl or websiteUrl. |
maxResultsPerCompetitor | integer | 100 | Saved-job cap per competitor (1–500). |
maxTotalResults | integer | 1000 | Global saved-row cap (1–5000). |
discoveryMode | string | career_url_first | career_url_first or shallow_website_discovery_only. |
includeJobDetails | boolean | false | Fetch one detail page per job (only when the card is sparse) to fill snippet/salary/date. |
includeKeywords | array of strings | [] | Keep jobs matching at least one keyword. |
excludeKeywords | array of strings | [] | Remove jobs matching any blocked keyword. |
roleCategories | array of strings | [] | Keep only these derived categories (engineering/sales/marketing/product/data/finance/hr/operations/customer_support/legal/security/other). |
locations | array of strings | [] | Keep only jobs whose location/region matches. |
remoteMode | string | any | any, remote, hybrid, onsite, unknown. |
postedWithinDays | integer | 0 | Posted-date window when visible (0 disables; 1–365). |
strictDateFilter | boolean | false | Drop undated rows when the date filter is enabled. |
deduplicate | boolean | true | Remove duplicate job rows so duplicates are not charged. |
proxyConfiguration | object | { "useApifyProxy": true } | Datacenter, no proxy, or custom proxy URLs. Apify Residential rejected at startup. |
Example inputs
1. Track two competitors and filter to high-value, recent roles
2. Discover careers pages from competitor websites only
3. Minimal run — just give it competitors with career URLs
Output
One flat row per unique job posting. Key fields:
- Competitor / source:
competitor_name,competitor_website_url,career_url,source_type(direct_career_url/discovered_career_url/job_detail_page),source_url,input_index,ats_platform - Job:
job_title,job_url,job_id,department,role_category,seniority_level,location,country_or_region,work_mode(remote/hybrid/onsite/unknown),posted_date,salary_text,job_snippet - Signals:
hiring_signal_score(0–100),hiring_signal_label(low/medium/high/very_high),reason_tags,matched_include_keywords - Runtime:
scraped_at
Rows without a job_title, or without either job_url or career_url, are invalid and never pushed.
Dataset — all fields (table view)
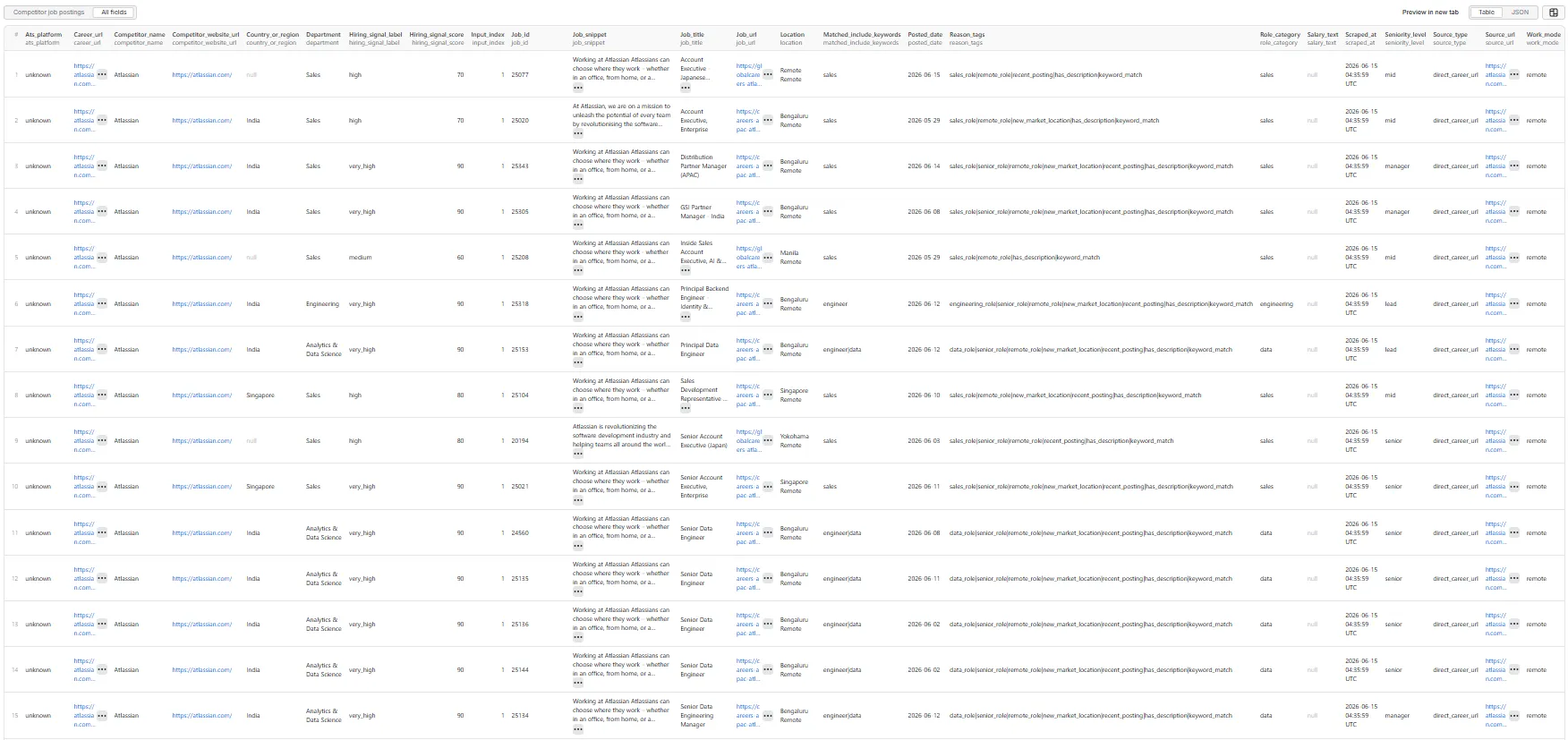
Sample record
One real row from a run on the default competitors (Canva, Atlassian):
A run summary is stored in the default key-value store under RUN_SUMMARY with counters such as inputs_total, competitors_processed, raw_results_found, results_saved, duplicates_removed, filtered_out, and charged_events.
Hiring-signal score
A transparent 0–100 score (PRD §7) based only on visible public fields. Each valid job starts at 20, then:
+15if role category isengineering,data,product,sales, orsecurity+10if seniority issenior,lead,manager,director, orexecutive+10if work mode isremoteorhybrid+10if the job is outside the competitor's primary country (location expansion)+10if posted within 14 days+10if an ATS platform is detected+10if a job snippet/description is available+5if salary text is visible+5if the title matches your include keywords
Labels: 0–39 low, 40–64 medium, 65–84 high, 85–100 very_high. reason_tags lists exactly which rules fired (pipe-separated).
Pricing
Pay Per Event. One event, competitor-job-result, is charged only after a valid, unique, filtered-in job row is successfully pushed to the dataset. Duplicate jobs, filtered-out jobs, failed inputs, blocked requests, and summary records are never charged. The actor honours your per-run spending limit and stops cleanly when it is reached.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for competitor career pages and public ATS APIs at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor fails at startup if apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~$8/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
How sources are found
For each competitor the actor tries, in order of reliability:
- Public ATS JSON APIs when the career URL is hosted on / links to one (Greenhouse, Lever, Ashby, SmartRecruiters, Recruitee, Workable).
- Schema.org
JobPostingJSON-LD embedded in the career page (server-rendered, standardized). - Generic careers-page HTML — job-detail links as a fallback.
- Known-site adapters for notable companies with a custom public listings endpoint (e.g. Atlassian), and ATS-token guessing as a last resort when a website is supplied without a usable career URL.
Notes & limitations
- Coverage is strongest for competitors that publish jobs on a public ATS — which, thanks to JSON-LD and token guessing, includes many companies whose own careers site is a custom app.
- Supplying a direct
careerUrlis the most reliable mode;shallow_website_discovery_onlyprobes only a few common paths and does not deep-crawl. - A custom JavaScript-only careers page with no public ATS board, JSON-LD, or adapter yields no rows for that competitor (this actor is HTTP-only by design — no headless browser; browser fallback is a future feature).
- If a competitor source requires login or blocks public access, that competitor is marked failed/partial and the run continues.