Ashby Hiring Intelligence Scraper
Pricing
from $1.80 / 1,000 job-results
Ashby Hiring Intelligence Scraper
Scrape public Ashby job boards by board name or URL into clean, CSV-ready hiring-signal data - titles, locations, departments, compensation, descriptions, remote flags, and signal tags. No login or cookies required.
Pricing
from $1.80 / 1,000 job-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share

Scrape public Ashby job boards by board name or URL, and turn them into clean, flat, CSV-ready rows — plus lightweight hiring-signal fields (department/team, workplace type, compensation presence, seniority hint, role family, signal score + reason tags). Built for lead-generation, sales teams, recruiters, staffing agencies, and market researchers.
No login, no cookies, no session tokens, no authenticated Ashby API keys. The actor uses Ashby's public job posting API over HTTP — a single request returns every published job for a board — so it stays fast and cost-predictable. You pay one flat event per unique job row that passes your filters.
✨ Why this scraper
- Public API-first — not a fragile browser scraper. Each board is read directly from Ashby's public posting endpoint.
- Two input modes — Ashby board slugs (
ramp,notion, …), or paste Ashby careers / API URLs (board slug extracted for you). - 33 flat fields — job identity, company/board, department/team, location, compensation, description, and hiring signals. No nested objects; drops straight into Sheets/Excel/CRMs.
- Pay-Per-Event — one flat
job-resultevent per saved unique job. Duplicates and filtered rows are never charged. - Compensation when public — currency, min/max, period, and a readable summary when the board exposes it.
- Transparent hiring-signal score — rule-based (no AI), explained below.
🚀 Quick start — sample inputs
Example 1 — board names + filters
Example 2 — Ashby careers URL + remote-only + custom proxy via your own provider
Provide at least one of
jobBoardNamesorstartUrls. If you provide both, the actor runs both and deduplicates across the whole run.
The actor blocks Apify Residential proxy; if you need residential routing, supply your own provider via
proxyConfiguration.proxyUrlsas shown. See 🚦 Proxy policy below.
📦 Output
The dataset has one view: Jobs & hiring signals — a 33-column flat table.
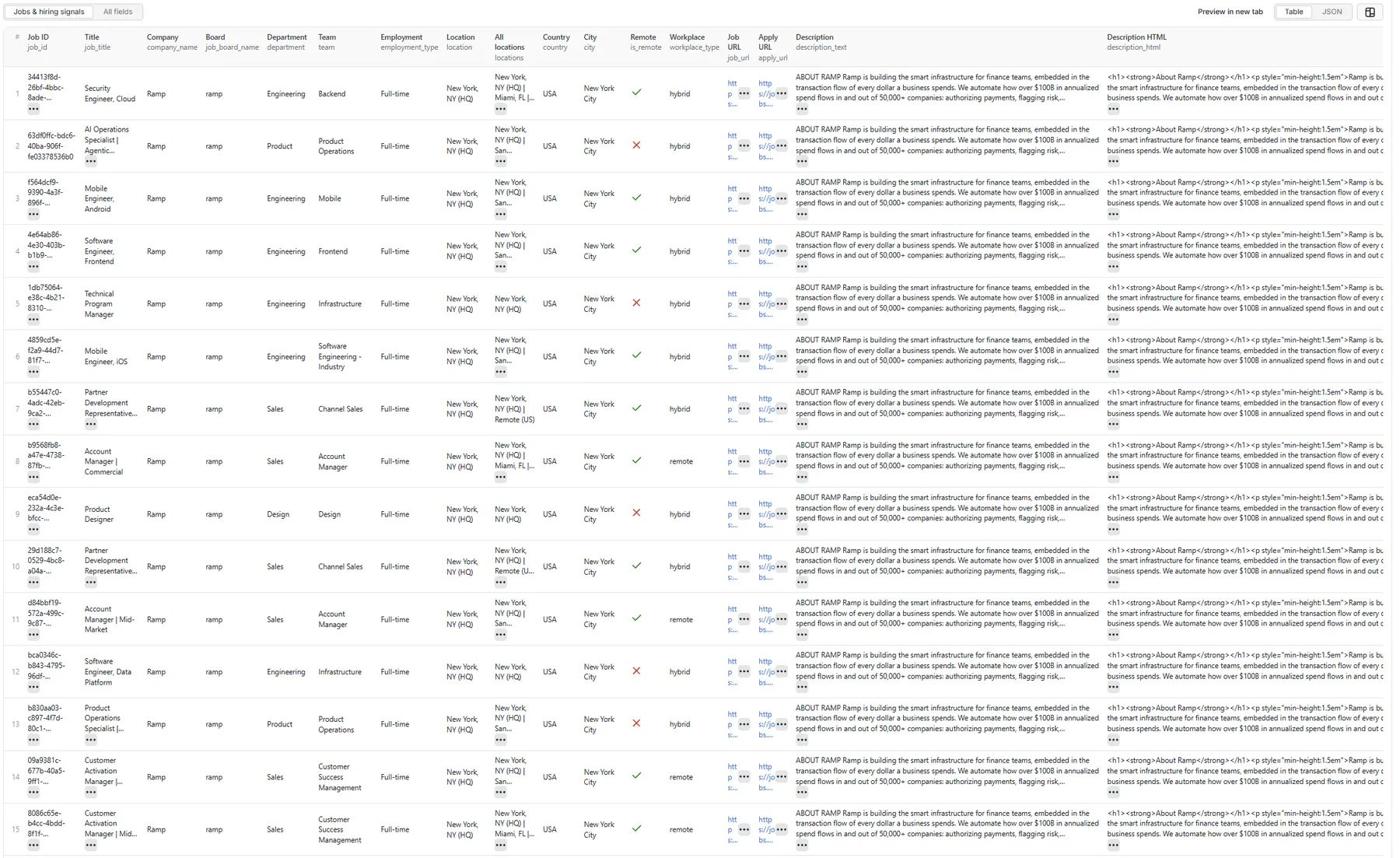
Output fields (33)
job_id, job_title, company_name, job_board_name, department, team, employment_type, location, locations, country, city, is_remote, workplace_type, job_url, apply_url, description_text, description_html, published_at, compensation_currency, compensation_min, compensation_max, compensation_period, compensation_text, has_compensation, seniority_hint, role_family, hiring_signal_score, hiring_signal_label, reason_tags, source_type, source_input, source_api_url, scraped_at.
Sample record — Jobs & hiring signals
(Real run output; the description_text / description_html are truncated here for readability.)
🎯 Hiring-signal score
Transparent rule-based score (0–100) computed from the extracted public fields — no AI, no external enrichment.
| Signal | Points |
|---|---|
| Base score | +30 |
| Public compensation present | +15 |
| Remote or hybrid role | +10 |
| Senior / lead / executive seniority hint | +10 |
| Department / team populated | +10 |
| Location populated | +10 |
| Description text longer than 500 chars | +10 |
| Apply URL present | +5 |
Score is capped at 100.
Labels: high (70–100) · medium (40–69) · low (0–39).
reason_tags is a pipe-separated list explaining the score — e.g. salary_visible, remote_role, hybrid_role, senior_role, department_known, detailed_description, application_url_available.
💰 Pricing
Pay-Per-Event. One flat event per saved row (final per-event price is configured on the Apify console):
| Event | Charged when |
|---|---|
job-result | Once per unique job row that passed all filters and was successfully written to the dataset. |
So your bill is simply results_saved × price_per_event. The actor honors the user-configured per-run spending cap (Apify eventChargeLimitReached): it both caps how many results it collects up-front to what the limit can pay for, and stops cleanly the moment the cap is reached during charging.
Not charged:
- Duplicates (deduplicated by
job_id+ board, canonicaljob_url, andapply_url/ title+company keys). - Rows filtered out by keyword / location / department / remote / compensation filters.
- Rows missing a
job_idorjob_title. - Failed boards, empty boards, or blocked requests.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for Ashby's public posting API at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor will fail at startup if proxyConfiguration.apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
📊 Run summary
After each run, a RUN_SUMMARY entry is written to the key-value store:
charged_events equals the number of successfully saved unique rows.
⚙️ Filters
| Filter | Effect |
|---|---|
keywordInclude | Keep rows containing any keyword in title, description, department, team, location, or company. |
keywordExclude | Remove rows containing any keyword in those same fields. Exclusion wins over inclusion. |
locationInclude | Keep rows matching any term in location, all-locations, city, country, or workplace type. |
departmentInclude | Keep rows matching any term in department, team, or role family. |
remoteOnly | Keep only rows where is_remote is true. |
compensationRequired | Keep only rows where has_compensation is true. |
dedupe | Drop duplicates by Ashby job ID + canonical URL across boards (recommended ON). |
Filters are applied before any dataset push or event charge.
🚧 Limitations (V1)
- Public posting data only: no login, cookies, sessions, or authenticated Ashby Data API. Only currently published jobs are returned.
- Compensation is only present when the board publicly exposes it and
includeCompensationis on;compensation_*fields arenullotherwise. - No
updated_atfield: the public posting API exposespublishedAtbut not an updated timestamp, so the output carriespublished_atonly. company_nameis derived from the board slug (title-cased) because the public posting API does not return an organization name.- No recruiter/contact extraction, email enrichment, company-website crawling, AI scoring, or historical change tracking.
- For non-Ashby careers URLs, the actor does a single best-effort HTML scan to discover an embedded Ashby board; if none is found, that input is marked failed and the run continues.
maxResultscaps saved unique rows across the whole run (not per board).
❓ FAQ
Do I need an Ashby account or API key? No. The actor only uses Ashby's public job posting API.
Where do I find a board slug?
It is the path segment in an Ashby careers URL: https://jobs.ashbyhq.com/{board} → {board}. You can paste the URL into startUrls and the actor extracts it for you.
Why is company_name just the board slug, title-cased?
The public posting API does not return an organization name, so the readable board slug is the safe public fallback.
Can I export to CSV?
Yes — every field is flat (no nested objects). Use Apify's CSV / Excel export, or call the dataset API with format=csv.
Will I get blocked? Ashby's posting API is public and stable. The actor uses conservative concurrency, realistic headers, session rotation, and retry/backoff. Default Apify Proxy or no proxy is sufficient for typical runs.
🛠️ Technical notes
- Stack: Node.js 22 · Apify SDK 3 · Crawlee
HttpCrawler(JSON over HTTP). No browser. - Endpoint: Ashby public
posting-api/job-board/{board}(optionalincludeCompensation=true). - Concurrency:
min=1,max=10(one request per board; conservative). - Memory: 1 GB min · 2 GB default · 4 GB max.
- Proxy: Apify Proxy enabled by default; custom configs accepted; Apify Residential rejected at startup.