Google Maps Scraper
Pricing
from $1.50 / 1,000 scraped places
Google Maps Scraper
Extract data from thousands of Google Maps locations and businesses, including reviews, reviewer details, images, contact info, including full name, email, and job title, opening hours, prices & more. Export data, run via API, schedule and monitor runs, or integrate with other tools.
Pricing
from $1.50 / 1,000 scraped places
Rating
4.7
(1638)
Developer
Compass
Maintained by ApifyActor stats
4.7K
Bookmarked
514K
Total users
34K
Monthly active users
1.2 days
Issues response
9 hours ago
Last modified
Categories
Share
📍 What is Google Maps Scraper?
Google Maps Scraper lets you extract business data from Google Maps, helping you generate leads, analyze competitors, and fuel growth with just a few clicks.
- Generate qualified leads: extract business names, websites, emails, and phone numbers to build prospect lists for your sales team
- Track competitors across regions: monitor where competitors operate, how they’re rated, and how many reviews they’ve received
- Perform market analysis: analyze market saturation, identify service gaps, or benchmark local businesses by size, rating, and visibility
- Support partnerships: discover top-rated or high-volume locations for outreach and collaboration
- Automate research workflows: replace manual search tasks with repeatable, workflows that keep datasets fresh and consistent.
The scraper expands Google Maps data extraction beyond the limitations of the official Google Places API and bypasses the limitation of Google Maps of displaying (and scraping) no more than 120 places per area.
What data does Google Maps Scraper extract?
| 🔗 Title/place name | 📝 Subtitle, category, place ID, and URL |
| 📍 Address | 🌍 Location, plus code and exact coordinates |
| ☎️ Phone number | 🌐 Website, if available |
| 📝 Company contact details from website (company email, phone number and social media profiles) | 🎯 Business leads enrichment (full name, work email address, phone number, job title, LinkedIn profile) |
| 📱 Social media profile enrichment (detailed profile data for Facebook, Instagram, YouTube, TikTok, Twitter) | ➕ List of detailed characteristics (additionalInfo) |
| 🌐 Search results | 📊 Review count and review distribution |
⭐️ Average rating (totalScore) | 📸 List of images |
| 🏨 Hotel booking URL and price + nearby hotels | 🔒 Temporarily or permanently closed status |
| 🙋 Updates from customers & Questions and answers | 🔍 People also search |
| 🏷 Menu | 💲 Price bracket |
| 🧑🍳 Opening hours | ⌚️ Popular times - histogram & live occupancy |
| 🪑 Table reservation provider | 🛍 Multiple businesses located within indoor venues, such as malls or shopping centers. |
| 🤖 Competitor analysis report (add-on) | 🗺 Interactive map visualization of analyzed competitors |
For maximum usefulness, Google Maps Scraper has the following abilities:
- Extract anything: names, addresses, websites, phone numbers, ratings, review counts, categories, or opening hours
- Flexible search: scrape using any number of criteria, including search query, category, location, coordinates, or URL
- Define the area to scrape: focus on specific locations, or set a wide area using coordinates or geolocation parameters
- Flexible output format: export data into almost any format, with multiple views available
- Integrate with other tools: use webhooks or our MCP server to set up workflows with other Actors or third-party tools like Make or Zapier
- Use add-ons for further enrichment: use paid add-ons to further enrich your data with contact details, images, reviews, or an AI-powered competitor analysis report
⬇️ Input
The input for Google Maps Scraper should be either a Google Maps URL or a location in combination with a search term. You can also extract any details such as images, reviews, amenities, and so on. You can set up the input programmatically or use the fields in scraper’s interface.
Search terms
Using multiple similar search terms can increase the number of scraped places but it also increases the time a run takes. We recommend using a combination of search terms that are distinct or overlap only slightly in meaning. Using a long list of duplicate search terms will just increase the time of a run without providing more results.
Example of a good list of search terms: [restaurant, bar, pub, cafe, buffet, ice cream, tea house]
Example of a bad list of search terms: [restaurant, restaurants, chinese restaurant, cafe, coffee, coffee shop, takeout]
While Google search results often include categories adjacent to your search, e.g. restaurant might also capture some cafe or bar places, but you will get better results if you use them as separate search terms, as well.
Categories
Using categories can be dangerous!
Search terms can introduce false positives, extracting some irrelevant places. Categories can be used to narrow down the results to just the ones you select.
Categories can also be dangerous because they can cause false negatives, excluding places you might want in the results. Google has thousands of categories and many are synonymous. You must list all the categories you want to match, including all synonyms; for example, Divorce lawyer, Divorce service, and Divorce attorney are three distinct categories and some places might be classified as only one of them, meaning you should input all of them. For this reason, we recommend going through the categories list carefully. For some use cases, you might want to select as many as 100 categories to ensure you don't miss any relevant places.
To help with this, Google Maps Scraper tries to increase the chance of a match by doing the following:
- If any category of a place (each can have several categories) matches any category from your input, it will be included.
- If all words from your input are contained in a category name, it will be included. E.g.
restaurantwill matchChinese restaurantandPan Asian restaurant.
⚠️ If categories are used without search terms, they will be used both as search terms and as category filters. However, for the above reasons, using categories without search terms is not recommended. We generally recommend fewer search terms and many categories.
Search without geolocation
Rather than using the standard search term and location inputs, you may also opt to use only the search term (e.g. "restaurants in berlin") or a direct Google Maps search URL (e.g. https://www.google.com/maps/search/restaurants/@52.5190603,13.388574,13z/) without the location input field. However, this approach will limit the number of results to a maximum of 120 because it only opens a single map screen on Google with a finite scroll. We only recommend skipping location input if you don't need more than 120 results, you need the lowest possible latency, or you want to get the results in the same order as Google would provide.
Direct Place IDs or URLs
Alternatively, you can also upload a direct Google Maps Place ID or URL (or a list of them) to Google Maps Scraper, which will extract the place details directly without going through the search step first. Be aware that if you provide direct place IDs or URLs, you will be charged extra as this is part of a paid add-on, namely that for additional place details scraped.
⬆️ Output
The results will be wrapped into a dataset which you can find in the Output or Storage tab. Note that the output is organized in tables and tabs for viewing convenience. You can view results as a table, JSON, or as a map.
Once the run is finished, you can also download the dataset in various data formats (JSON, CSV, Excel, XML, HTML). Before exporting, you can pick or omit specific output fields; alternatively, you can also choose to download the whole view, which includes thematically connected data.
Reviews and Leads enrichment views spread each review or lead to a separate row for easier data processing.
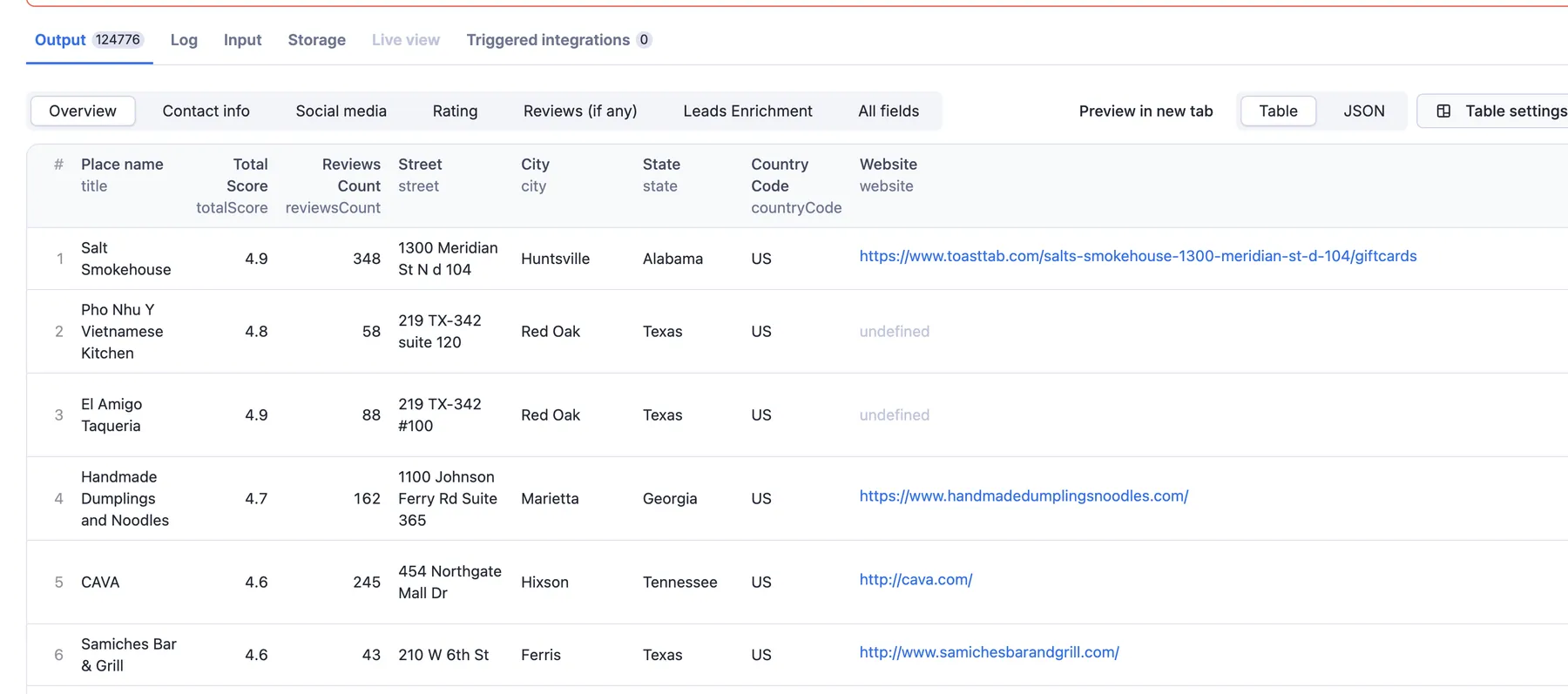
Table view
The table view can be manipulated in different ways. There is a general overview, but you can also sort the table by contact info, location rating, reviews, or other fields.
JSON file
Here's the amount of data you'd get for a single scraped place (this one 📍 so you can compare). Example of 1 scraped restaurant in New York:
🏢 Company contacts enrichment
👥 Business leads enrichment
✅ Add-on: Email verification
When verifyLeadsEnrichmentEmails is enabled, each lead's email address is verified and an emailVerification object is added to the lead output. Requires business leads enrichment to be active.
Charged (decisive results):
ok– Valid, deliverable email addressinvalid– Invalid or non-existent email addressdisposable– Disposable or temporary email address
Not charged:
catch_all– The domain accepts all addresses; individual deliverability cannot be confirmedunknown– Verification result could not be determinederror– Verification encountered a technical error
📱 Social Media Profile Enrichment
When social media profile enrichment is enabled, Google Maps Scraper can enrich discovered social media URLs with detailed profile information (follower counts, descriptions, and verification status...). The enriched profiles are included directly in the place output.
Important Notes:
- Social media profile enrichment requires the Company contacts enrichment feature to be enabled (this is automatically enabled when you enable Social media profile enrichment)
- Each enriched social media profile is a separate billable event
- You can enable enrichment for specific platforms only (e.g., only Facebook and Instagram)
- All enrichment options are disabled by default
- Enriched profiles are available in the Social profiles output view tab
🤖 Competitor analysis add-on
When enableCompetitorAnalysis is enabled, the scraper caps the total scraped places to maxCompetitorsToAnalyze (default: 30, max: 100) across all search terms combined, runs an AI-powered analysis on all of them after the crawl finishes, and pushes a single report to the dedicated competitorAnalysis named dataset. Set maxCompetitorsToAnalyze to 0 to skip the analysis even if the flag is on.
⚠️ Use a single, focused search term for best results. The final report ranks and compares all collected places against each other - they need to be in the same business category and market segment (e.g.
italian restaurants Vienna). Using multiple search terms that span different categories (e.g.restaurants+coffee shops+hair salons) will produce a meaningless comparison because the AI will rank and contrast fundamentally different types of businesses. Multiple search terms are fine if they all target the same segment (e.g.sushi restaurants NYC+japanese restaurants NYC).
Enabling this add-on automatically forces:
- Full place detail scraping for all places (
scrapePlaceDetailPageis overridden totrue) - At least 100 reviews per place (overrides a lower
maxReviewssetting) - Social media profile enrichment for all places
Example cost: 100 competitors analyzed
The table below shows the additional cost of enabling this add-on for 100 places, assuming 100 reviews per place and 1 social media profile found per place. The base place-scraped cost applies regardless of this add-on.
| Event | Count | FREE | SILVER |
|---|---|---|---|
| Additional place details | 100 | $0.20 | $0.15 |
| Company contacts enrichment | 100 | $0.20 | $0.15 |
| Reviews (100 per place) | 10,000 | $5.00 | $3.70 |
| Social media profile enrichment | 100 profiles | $10.00 | $0.70 |
| Competitor analysis event | 100 | $2.50 | $1.80 |
| Total | ~$17.90 | ~$6.50 |
Reviews are the largest cost driver. Social media profile enrichment on the FREE plan is priced significantly higher than on paid plans. The exact cost depends on how many social profiles are actually found per business.
The report covers:
- Per-place analysis - review-backed strengths, weaknesses, and unique selling propositions (each claim cited to a specific review); sentiment breakdown; social media presence summary
- Comparative ranking - all analyzed places ranked with justification
- Aspect-by-aspect comparison - who leads and who lags on dimensions like customer sentiment, price positioning, and operational quality
- Strategic market overview - main competitive battlegrounds, market opportunities, and threats
- Map visualization - interactive HTML map stored in the Key-Value Store
🏩 External places (hotels)
Google sometimes shows these places when searching in certain locations, mainly for hotels. They are however not regular places with pins on the map and offer only some of the regular output fields. These places are marked with 3 extra output fields:
🏩 Hotel-specific info
🍽️ Restaurant-specific info
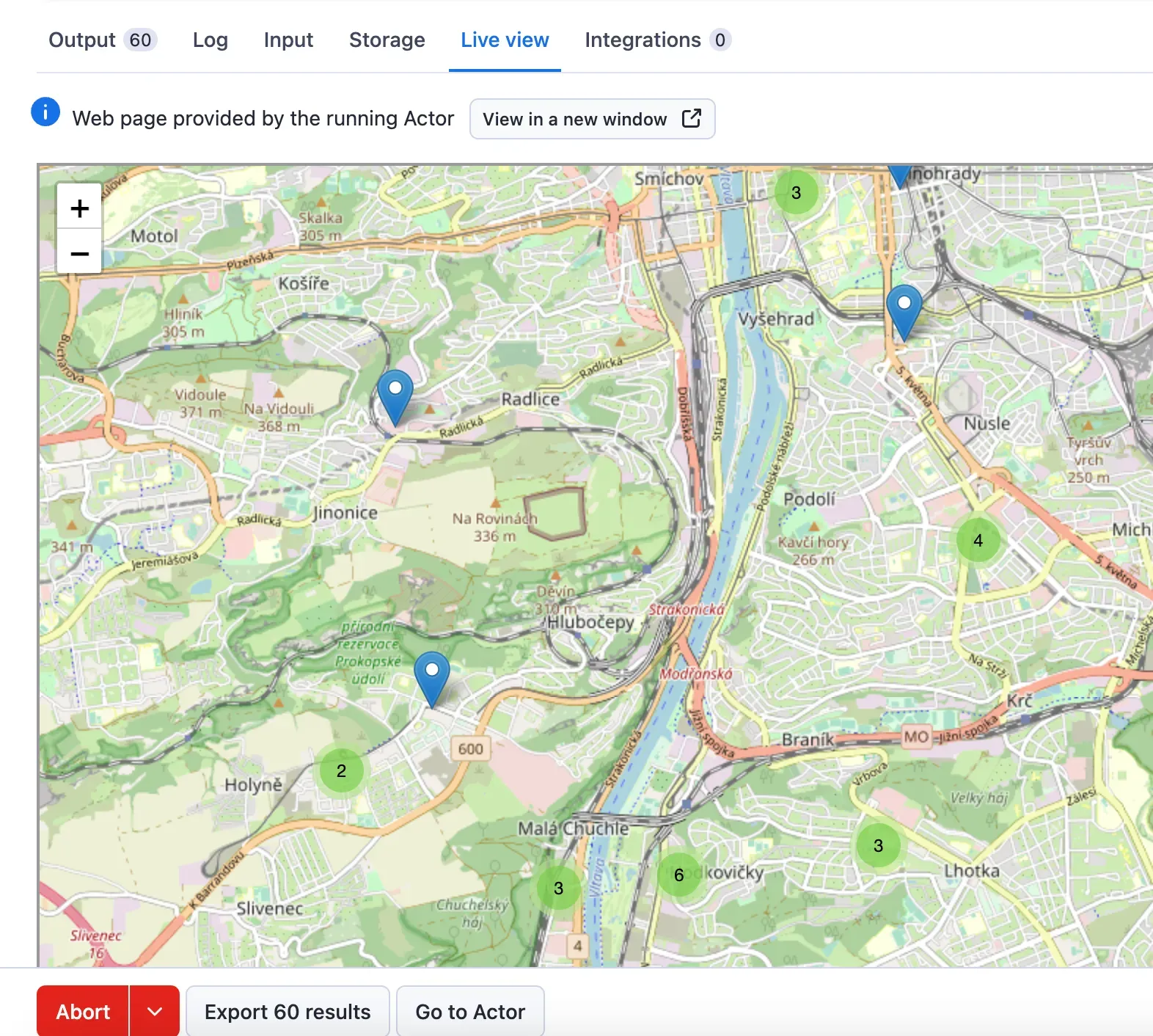
Map view
Google Maps Scraper provides a zoomable map that shows all the places scraped. The map is shown in the Live View tab on the actor run page and also stored in the Key-Value Store as results-map.html record.
📍📡 Using geolocation for pinpoint accuracy
Location, country, state, county, city, and postal code
Using free text in Location field should normally be enough to start scraping. For a more precise search, you can also use the Geolocation parameters field and use a combination of country, state, county, city, and postalCode.
Google Maps Scraper uses Open Street Map as its geolocation API. You can easily check the location matching your geolocation input on the official Open Street Map page.
🛰 Custom search area
If your location can’t be found on Google Maps or you want to customize it for a specific area, you can use the Custom search area function. You’ll have to provide coordinate pairs for an area and the scraper will create start URLs out of them. As an example, see the geojson field in Nominatim Api (example of Cambridge in Great Britain).
There are several types of search area geometry that you can use in Google Maps Scraper: Polygon, MultiPolygon and Point (a circle with a radius of 5 kilometers by default). All of them follow the official Geo Json RFC and all types are supported. We’ve found the polygons and circle to be the most useful ones when it comes to scraping.
Note that the order of longitude and latitude is reversed in GeoJson 🔄 compared to the Google Maps website. The first field must be longitude ↕️, the second field must be latitude ↔️.
We recommend using Geojson.io to create customGeolocation of any type/shape in correct format. You can watch this video on how to use it together with our scraper.
💠 Polygon
The most common type is a polygon, which is a set of points that define the scraped area. Note that the first and last pair of coordinates must be identical (to close the polygon). This example covers most of the city of London, UK:
💠💠 MultiPolygon
MultiPolygon can combine more polygons that are not contiguous (for example, an island close to the mainland). Same as with the polygon, make sure the first and the last pair of coordinates in each polygon are identical.
🔘 Circle
For a circle, we can use the Point type with our custom parameter radiusKm. Don't forget to change the radius to fit your needs. This example covers the city of Basel in Switzerland:
❓FAQ
How does Google Maps Scraper work?
It works exactly as if you were searching through Google Maps and copying information from each page you find. It opens the Google Maps website, goes to a specified location, then writes your search query into the search bar. Then it scrolls down until it reaches the end of the scroll bar or maxCrawledPlacesPerSearch. It enqueues all the places as separate pages and then copypastes all visible data into an organized document. This process is repeated for many map pages inside the input location. To understand the process fully, just try it out in your browser - the scraper does exactly the same thing, only much faster.
What are the disadvantages of the Google Maps API?
With the Google Maps API, you get $200 worth of credit usage every month free of charge. That means 28,500 map loads per month. However, the Google Maps API caps your search results to 60, regardless of the radius you specify. So, if you want to scrape data for bars in New York, for example, you'll get results for only 60 of the thousands of bars in the area. Google Maps Scraper imposes no rate limits or quotas and provides more cost-effective, comprehensive results, and also scrapes histograms for popular times, which aren't available in the official API.
Can I scrape places from multiple locations?
In most cases, you don't need multiple locations at all. A single broad location, such as an entire country or state, works fine on its own, since Google Maps Scraper automatically covers the whole area for you instead of requiring you to search city by city or neighborhood by neighborhood.
Google Maps Scraper does support only a single location query per run, so if you genuinely need separate, non-contiguous locations (e.g. Paris and Tokyo in the same run), you can use Google Maps Scraper Orchestrator to scrape multiple locations with a single list. It will automatically run Google Maps Scraper for each location in the list and merge the results, and it also fully uses your Apify account memory for maximum speed. If you want to use only Google Maps Scraper, you can add multiple locations using customGeolocation with multiple polygons.
How can I increase the speed of the scraper?
You can increase the run memory up to 8 GB per run. To speed up the scraping even more, you can run several runs at once to fully utilize all your account memory. To make this simpler, you can use the Google Maps Scraper Orchestrator to split locations or search terms over multiple runs, deduplicate the results and collect them to a single dataset.
Can I use the Google Maps Scraper to extract Google reviews?
Yes. This Google Maps Scraper also supports the extraction of detailed information about reviews on Google Maps. Note that personal data extraction about reviewers is also possible but has to be explicitly enabled in input (see the Legality of scraping Google Maps section).
| 📝 Review text | 📅 Published date |
| 🌟 Stars | 🆔 Review ID & URL |
| ✅ Response from the owner - text | 📷 List of review images |
| 💬 Review context | 📊 Detailed rating per service |
| 🧛 Reviewer’s name | ✍️ Reviewer’s number of reviews |
| 🖼 Reviewer’s ID, URL & photo | 👋 IsLocalGuide |
How can I get one review per row in the output?
If you need to view reviews in a table with each review in a separate row, you can click on the Reviews (if any) Export dataset view.
To use this view via API, you need to add &view=reviews to the dataset export URL. E.g. https://api.apify.com/v2/datasets/DATASET_ID/items?clean=true&format=json&view=reviews
If you don't use the Reviews (if any) view, each output place item will contain a maximum of 5,000 reviews (in table format, it means a lot of columns). So if there are more reviews for that place, a duplicate place will be stored with the next 5,000 reviews, and so on. For instance, in a case of 50,000 reviews, the resulting dataset will have 10 items for the same place. We have this limitation due to the size limit of a single item in the Apify dataset.
Can I integrate Google Maps Scraper with other apps?
Yes. The Google Maps Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate your Google Maps data with Zapier, Slack, Make, Airbyte, GitHub, Google Sheets, Asana, LangChain and more.
You can also use webhooks to carry out an action whenever an event occurs, for example, get a notification whenever Google Maps Scraper successfully finishes a run.
Can I use Google Maps Scraper as its own API?
Yes, you can use the Apify API to access Google Maps Scraper programmatically. The API allows you to manage, schedule, and run Apify actors, access datasets, monitor performance, get results, create and update actor versions, and more.
To access the API using Node.js, you can use the apify-client NPM package.
To access the API using Python, you can use the apify-client PyPI package.
For detailed information and code examples, see the API tab or refer to the Apify API documentation.
Can I use this Google Maps Scraper API in Python?
Yes, you can use the Apify API with Python. To access the Google Maps Scraper API with Python, use the apify-client PyPI package.
You can find more details about the client in our Python Client documentation.
What are other tools I can use with Google Maps?
Use the dedicated scrapers below and combine them with Google Maps Scraper for more comprehensive analysis.
| 🪢 Google Maps Scraper Orchestrator | ⭐️ AI Text Analyzer for Google Reviews |
| 🤖 Competitor Analysis Agent | 🤖 Market Expansion Agent |
Is it legal to scrape Google Maps data?
Web scraping is legal if you are extracting publicly available data which is most data on Google Maps. However, you should respect boundaries such as personal data and intellectual property regulations. You should only scrape personal data if you have a legitimate reason to do so, and you should also factor in Google's Terms of Use.
Your feedback
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for Google Maps Scraper or simply found a bug, please create an issue on the Actor’s Issues tab.