Google Trends Scraper
Pricing
from $0.30 / 1,000 results
Google Trends Scraper
Scrape data from Google Trends by search terms or URLs. Specify locations, define time ranges, select categories to get interest by subregion and over time, related queries and topics, and more. Export scraped data, run the scraper via API, schedule and monitor runs, or integrate with other tools.
🌍 What is Google Trends Scraper?
Our Google Trends Scraper crawls specified search queries and Google Trends URLs, and extracts data from Google Trends pages in structured formats such as JSON, CSV, XML, or Excel. With this Google Trends API, you will be able to extract the following Google trends data:
| 🔍 Search term | 🏙 Interest by city |
| 🌍 Interest by subregion | 🗺 Geo code and Geo name |
| 📊 Average interest over time | 📆 Timeline of the interest over time |
| 🔺 Rising related queries | 🔝 Top related queries |
| ⬆️ Rising related topics | ⭐️ Top related topics |
🌐 How do I use Google Trends Scraper?
Google Trends Scraper is designed to be user-friendly, even for those who have never extracted data from the web before. Here’s how you can use Google Trends Scraper to extract data from Google trends:
- Create an Apify account
- Open Google Trends Scraper.
- Enter your search term, location, and time range. Or use a Google Trends URL with applied filters instead.
- Click the “Start” button and wait for the data to be extracted.
- Download your data in JSON, CSV, Excel, XML or HTML.
If you need guidance on how to run the scraper, you can read our step-by-step guide to scraping Google Trends, it includes use cases, screenshots, and examples. Or watch a short video tutorial ▷ on YouTube.
📉 What can you do with scraped Google Trends data?
🔍 Back up your market research by tracking the popularity of search terms and identifying trending topics
📊 Find business insights by comparing the popularity of multiple search terms and see how they relate to each other
📍 Generate content ideas by exploring regional interest and see which areas are searching for specific topics the most
💡 Discover related queries and topics to gain a deeper understanding of user interests
🕒 Improve your SEO game by analyzing search trends over time to identify seasonal patterns or long-term changes in user behavior
⬇️ Input example
You can scrape Google Trends either by search query or by a Google Trends URL. For a full explanation of input including an example in JSON, head over to the input tab.
You can set up the input programmatically or use the fields in scraper’s interface:
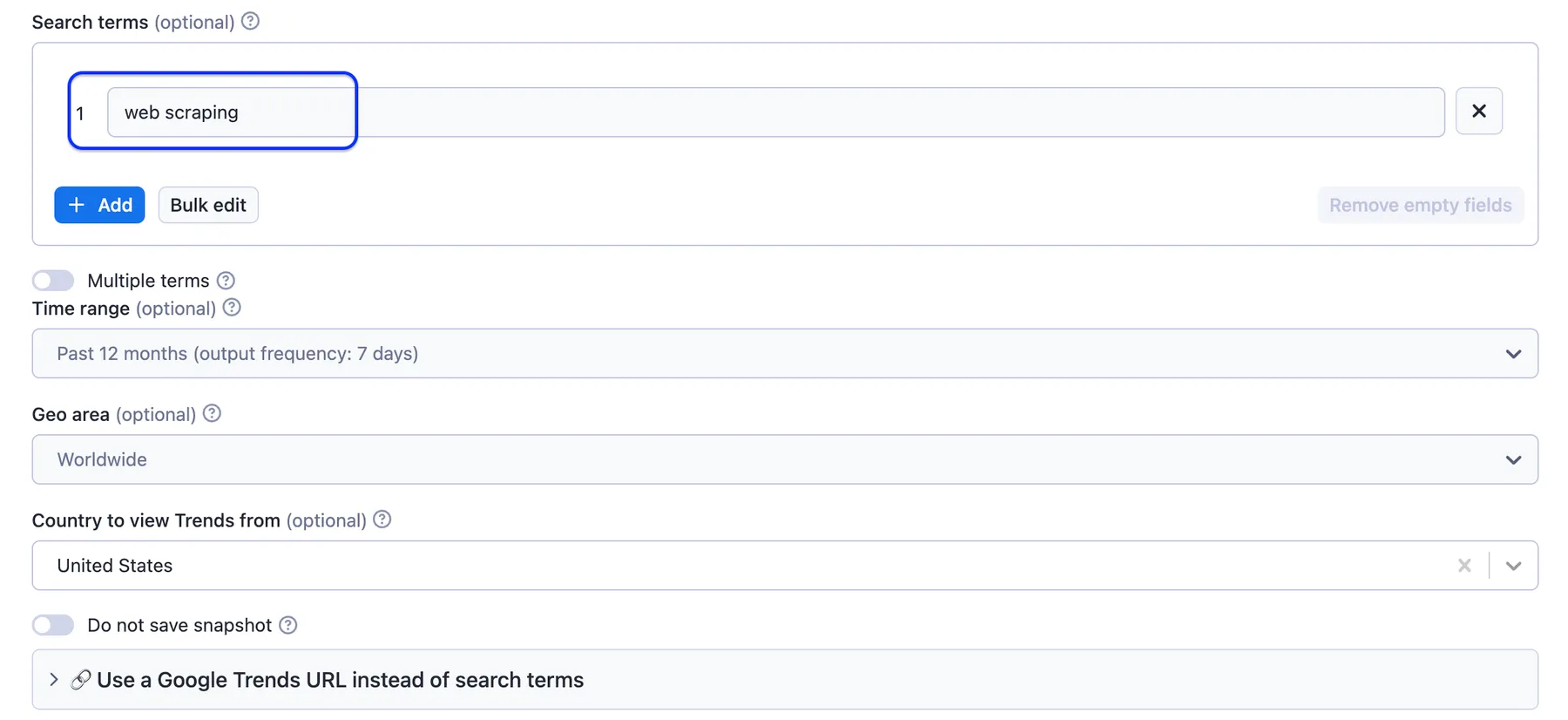
⬆️ Output example
The scraped Google Trends data will be shown as a dataset which you can find in the Output tab. Note that the output is organized as a table for viewing convenience:
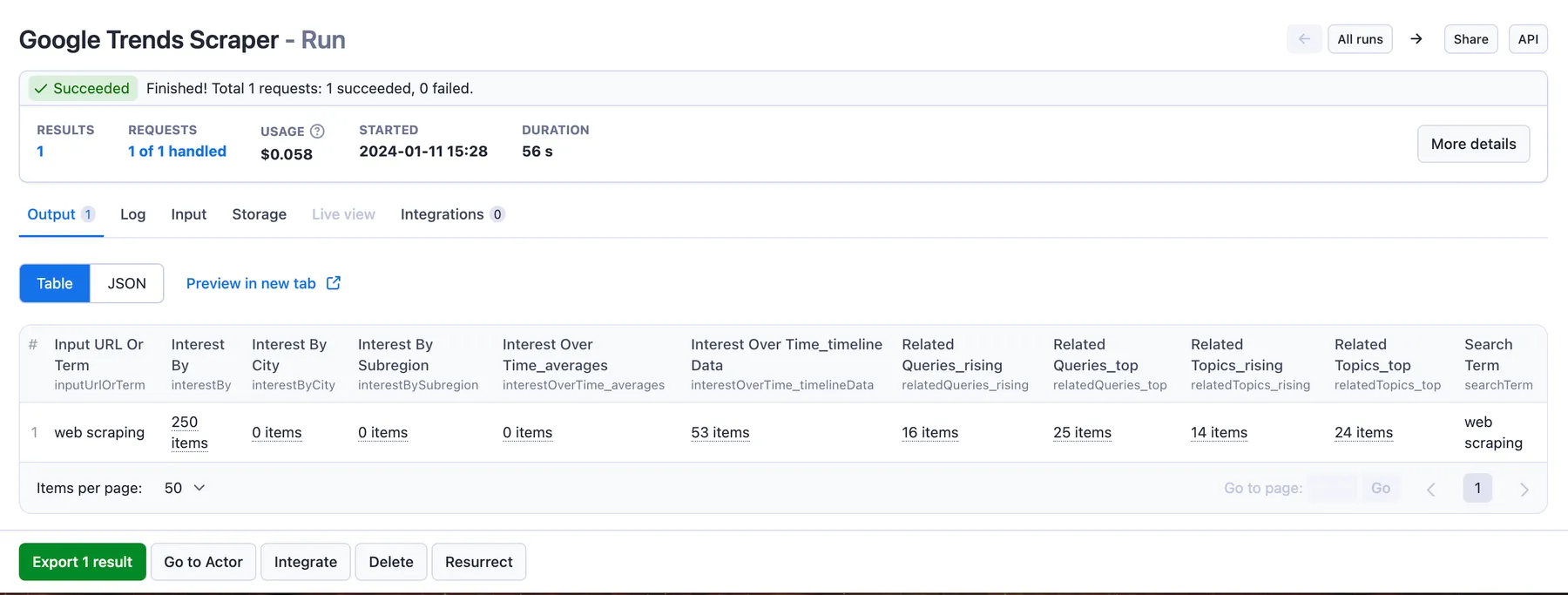
You can preview all the fields and choose in which format to download Google Trends data you’ve extracted: JSON, Excel, HTML table, CSV, or XML. Here below is the same dataset in JSON:
📍 Want to try other Google scrapers?
Use the dedicated scrapers below if you want to scrape specific public data from Google services. Each of them is built particularly for the relevant scraping case be it Google places, images, Google trending searches or Google SERP data. Feel free to browse them:
❓FAQ
Is there a Google Trends API?
Google Trends does not offer an official API for public use. This means there isn't a dedicated Application Programming Interface provided by Google specifically for Google Trends data. But you can use scrapers and crawlers as a stand-in for a web scraping API, e.g. 📈📉Google Trends Scraper.
Can I use Google Trends Scraper data with API?
Yes, you can do so by using Apify API. It gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify Actors such as this one. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Check out the Apify API reference docs for full details or click on the API tab for code examples and API Endpoints.
Can I create a Google Trends integration using data from this scraper?
Yes. Google Trends Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Make, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, LangChain and more.
Or you can use webhooks to carry out an action whenever an event occurs, e.g. get a notification whenever Google Trends Scraper successfully finishes a run.
Can I use this Google Trends API in Python?
Yes, by using Apify API. To access the Google Trends API using Python, use the apify-client PyPI package. You can find more details about the client in our Docs.
Is it legal to scrape Google Trends data?
It is legal to scrape publicly available data from Google Trends. However, you should always review and comply with Google's terms of service and any applicable laws and regulations regarding web scraping. Additionally, be mindful of any rate limits or restrictions imposed by Google to avoid potential issues.
Not your cup of tea? Build your own scraper.
Google Trends Scraper doesn’t exactly do what you need? You can always build one of your own! We have various scraper templates in Python, JavaScript, and TypeScript to get you started. Alternatively, you can write it from scratch using our open-source library Crawlee. You can keep the scraper to yourself or make it public by adding it to Apify Store (and find users for it).
Your feedback
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for Google Trends Scraper or simply found a bug, please create an issue on the Actor’s Issues tab in Apify Console.