Twitter Scraper
Under maintenance
Pricing
$3.50 / 1,000 posts
Twitter Scraper
Under maintenance

Scrape tweets from any Twitter user profile. Top Twitter API alternative to scrape Twitter hashtags, threads, replies, followers, images, videos, statistics, and Twitter history. Export scraped data, run the scraper via API, schedule and monitor runs or integrate with other tools.
4.3 (11)
Pricing
$3.50 / 1,000 posts
137
Total users
32.5k
Monthly users
737
Runs succeeded
91%
Issue response
1 days
Last modified
2 months ago
ℹ️ This Twitter scraper only collects data that’s publicly available. This means data that’s accessible without logging in to Twitter and without accepting Twitter’s terms of use. Please note that if you accepted Twitter’s terms of use, your ability to scrape Twitter data may be limited. If that’s the case, please review the terms and make an informed decision yourself.
⚠️ This scraper cannot scrape the latest tweets, only the most liked ones. To scrape the latest tweets, try other Twitter scrapers.
🐦 What data can Twitter Scraper extract?
Twitter Scraper crawls specified Twitter profiles and Twitter post URLs, and extracts:
🔍 User tweets: tweet text, timestamp and URL
🏞 Tweet media: images, videos, gifs, hashtags
🦸♂️ Tweet author data: screen name, follower/following count, description, verified status, user mentions
📊 Statistics for each tweet: favorites, replies, and retweets for each tweet
What are the limitations of Twitter Scraper?
Due to the recent changes on Twitter, there are new limitations when it comes to viewing and therefore scraping tweets on this platform:
- The Actor extracts only publicly available information
- For each profile, it is possible to scrape up to 100 tweets
- This scraper cannot scrape the latest tweets due to the changes on Twitter website
- Instead, the scraped tweets are ordered by the number of likes (see the output sample)
Keep in mind that this might affect your experience if you're trying to scrape an older tweet or follow a chronological order of their posts. If these limitations are a deal breaker for you, we recommend switching to other Twitter scrapers in Apify Store, for example: Twitter Scraper 🔗 or Twitter Profile Scraper 🔗.
📚 How do I use Twitter Scraper?
It’s quite easy: pick Twitter Scraper, choose a profile or a tweet to scrape, and click the Start button. If you need guidance on how to run the scraper, you can watch a short video tutorial ▷ on YouTube.
⬇️ Input example
You can scrape Twitter either by using Twitter usernames (handles) or by Tweet URLs. If you want to use the URL option, these are the supported Twitter URL types ⬇️
- Profiles: https://twitter.com/ZelenskyyUa
- Tweets: https://twitter.com/ZelenskyyUa/status/1694240409428299869
This is what the input options of the Twitter Scraper look like:
⬆️ Twitter data output
The results will be wrapped into a dataset which you can find in the Storage tab. Here's an excerpt from the dataset you'd get if you apply the input parameters above:
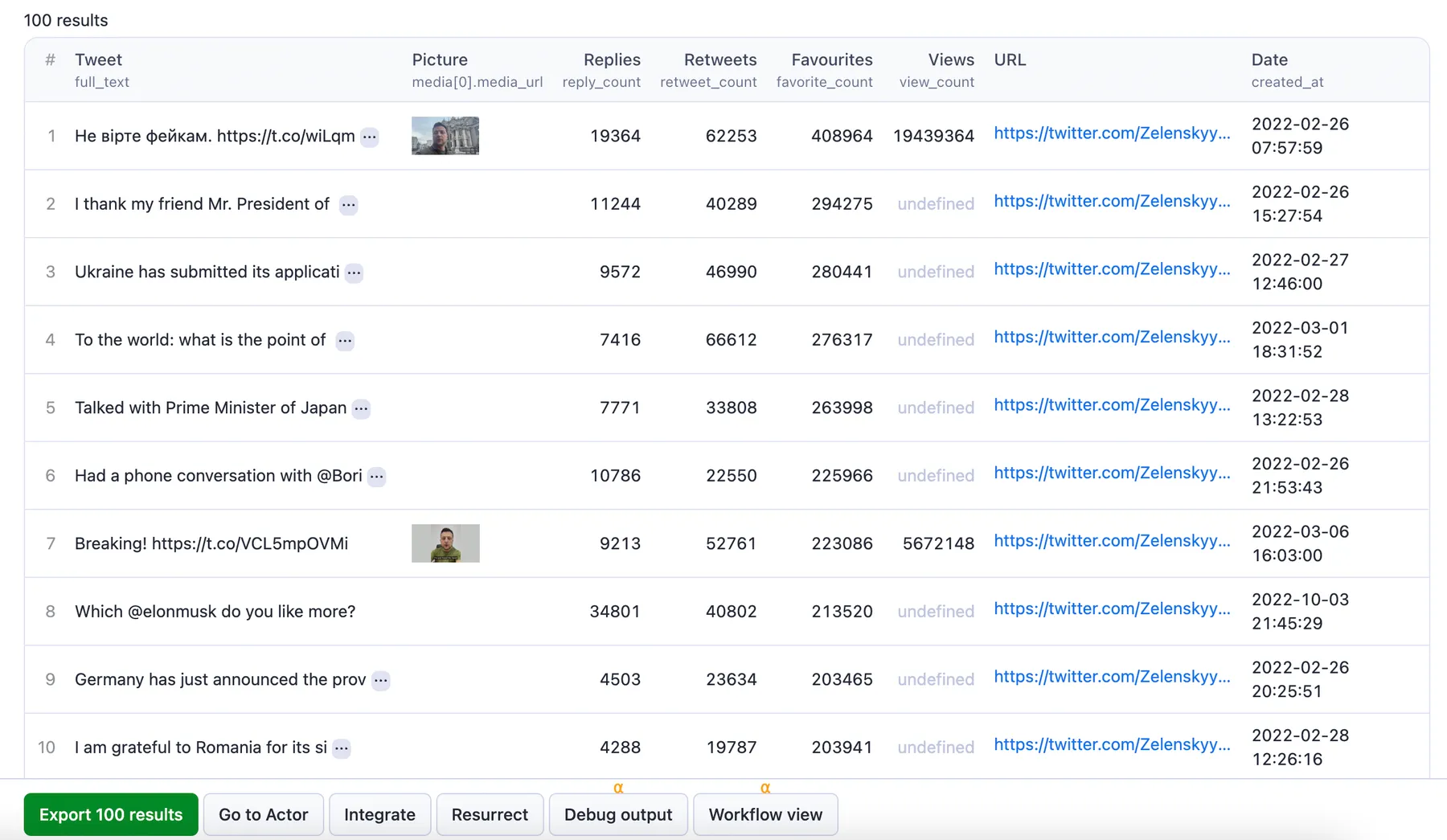
You can download the resulting dataset in various formats such as JSON, HTML, CSV or Excel. Each item in the dataset will contain a separate tweet following this format:
🔍 Want more tools for scraping Twitter?
Use our fast dedicated scrapers if you want to scrape specific Twitter data. Each of them is built particularly for the relevant Twitter scraping case be it URLs, videos, spaces or user profiles. Feel free to browse them:
| 🧑💼 Twitter Profile Search Scraper | 🔗 Twitter URL Scraper |
| 🔎 Tweet Flash - Twitter Scraper | 🔍 Twitter Search |
| 💬 Twitter Comments Scraper | 🧭 Twitter Timeline |
| 🐤 Twitter Scraper | 🆇 X / Twitter Scraper |
❓ FAQ
Is it legal to scrape Twitter?
It is legal to scrape Twitter to extract publicly available information, but you should be aware that the data extracted might contain personal data. Personal data is protected by GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping.
How many results can you scrape with Twitter scraper?
Twitter is currently limiting the tweets per profile to 100 tweets (as of August 2023).
Why use Twitter Scraper?
Scraping Twitter will give you access to more than 500 million tweets posted every day. You can use that data in lots of different ways:
🔍 Track discussions about your brand, products, country, or city.
👥 Monitor your competitors and see how popular they really are, and how you can get a competitive edge.
🔎 Keep an eye on new trends, attitudes, and fashions as they emerge.
🧠 Use the data to train AI models or for academic research.
😊 Track sentiment to make sure your investments are protected.
🚫 Fight fake news by understanding the pattern of how misinformation spreads.
✈️ Explore discussions about travel destinations, services, and amenities, and take advantage of local knowledge.
💰 Analyze consumer habits and develop new products or target underdeveloped niches.
How to build your own Twitter Hashtag Scraper?
If this Twitter scraper doesn’t exactly do what you need, you can always build a crawler of your own! We have various scraper templates in Python, JavaScript, and TypeScript to get you started. Alternatively, you can write it from scratch using our open-source library Crawlee. You can keep the scraper to yourself or make it public by adding it to Apify Store (and find users for it).
Can I integrate Twitter Scraper with other apps?
Last but not least, Twitter Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Make, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and more. Or you can use webhooks to carry out an action whenever an event occurs, e.g. get a notification whenever Twitter Scraper successfully finishes a run.
Can I use API with Twitter Scraper?
Yes. You can use the Apify API which gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Check out the Apify API reference docs for full details or click on the API tab for code examples.
Your feedback
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for Twitter Scraper or simply found a bug, please create an issue on the Actor’s Issues tab in Apify Console.

