YouTube Scraper
Pricing
$5.00 / 1,000 videos
YouTube Scraper

YouTube crawler and video scraper. Alternative YouTube API with no limits or quotas. Extract and download channel name, likes, number of views, and number of subscribers.
4.6 (31)
Pricing
$5.00 / 1,000 videos
960
Total users
26K
Monthly users
5.9K
Runs succeeded
>99%
Issues response
1.3 days
Last modified
10 days ago
title | id | url | viewCount | likes | channelName | numberOfSubscribers | duration |
|---|---|---|---|---|---|---|---|
Crawlee, the web scraping and browser automation library | g1Ll9OlFwEQ | https://www.youtube.com/watch?v=g1Ll9OlFwEQ | 10150 | 136 | Apify | 6640 | 00:03:15 |
Crawlee for Python: Build reliable crawlers. Fast. | Ejhudr7e-h4 | https://www.youtube.com/watch?v=Ejhudr7e-h4 | 916 | 23 | Apify | 6640 | 00:03:39 |
Build a Web Scraper from Scratch | JavaScript | Playwright | Crawlee | DOtJEwVsJic | https://www.youtube.com/watch?v=DOtJEwVsJic | 4411 | 109 | deejaydev | 1680 | 00:22:43 |
The data above is synthetic and does not reflect real-world values. View full dataset
What does YouTube Scraper do?
YouTube Scraper is a data extraction tool created to go beyond the limitations of the YouTube Data API. It extracts public data from YouTube video platform without limitations such as quotas or units. This tool is perfect for you if you need to:
- scrape YouTube channel videos, titles, description, metadata, etc.
- scrape YouTube videos with view count, release date, number of likes, number of comments, etc.
- scrape YouTube subtitles
- scrape YouTube playlists and streams
- scrape YouTube search results
What data can you scrape from YouTube?
| 📺 Channel name | 👍 Number of likes |
| 📱 Social media links | 💬 Comments count |
| 📝 Video title | 🔗 Video URL |
| 🖍 Subtitles | 📍 Channel location |
| 📼 Total videos | 🌐 Channel URL |
| 👀 Number of views | 👁️ Video view count |
| 🧿 Total views | 📈 Number of subscribers |
| ⏱️ Duration | 📅 Release date |
How many videos can you scrape with YouTube Scraper?
YouTube Scraper can extract up to 20,000 videos per URL. However, you have to keep in mind that scraping youtube.com has many variables to it and may cause the results to fluctuate case by case. There’s no one-size-fits-all-use-cases number. The maximum number of results may vary depending on the complexity of the input, location, and other factors.
Therefore, while we regularly run scraper tests to keep the benchmarks in check, the results may also fluctuate without our knowing. The best way to know for sure for your particular use case is to do a test run yourself.
⬇️ Input example
For input, you can either use the fields in Console to set up your Actor or input it directly via JSON. You can also use this scraper locally — head over to the input schema tab for technical details.
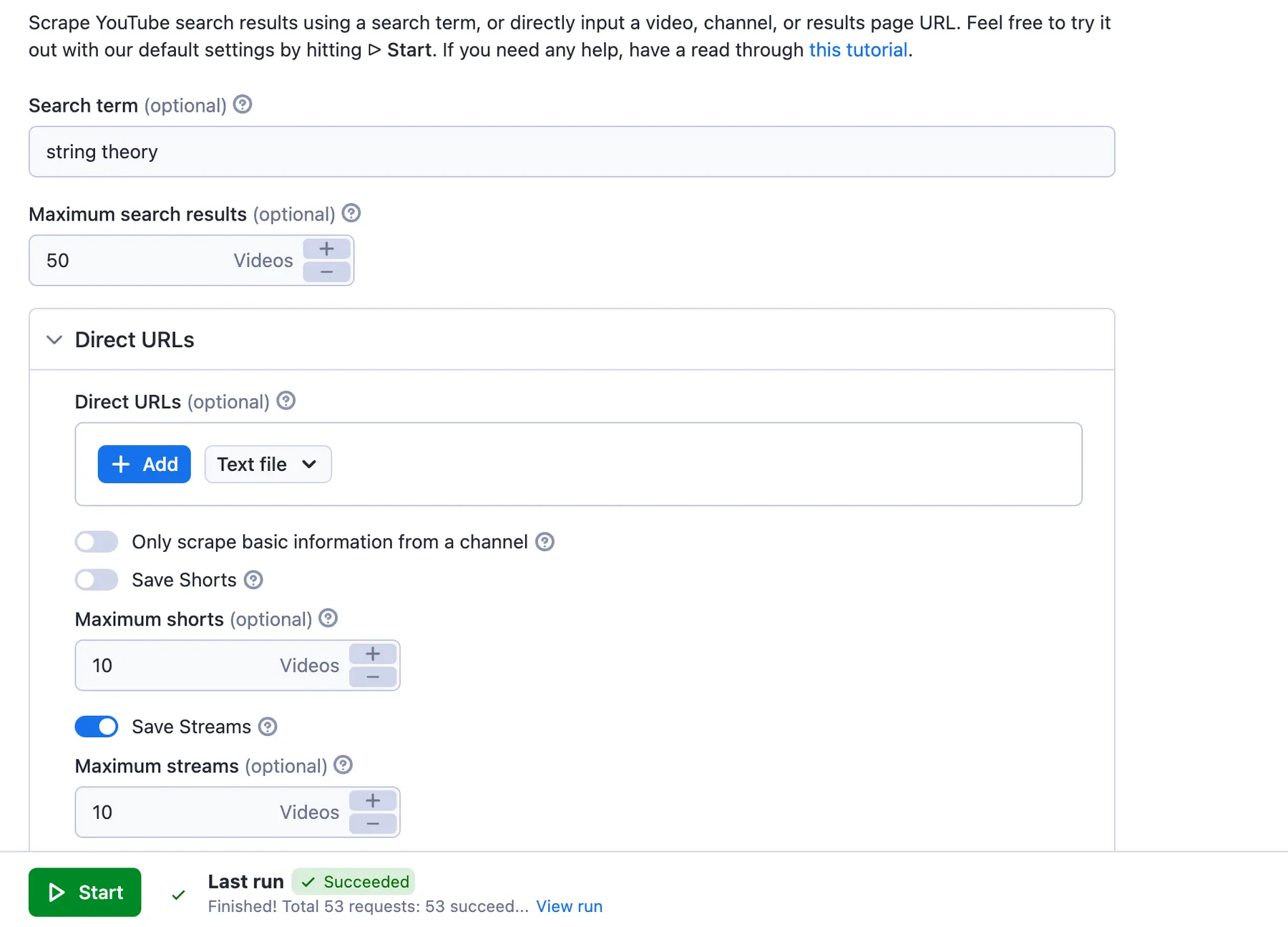
🔗 How to scrape YouTube by URL or search term
There are two ways you can scrape YouTube: either by URL or by search term.
- Scraping by URL 🔗 will get you data from any video, channel, playlist, or search results. You can add as many URLs as you want.
- Scraping by search term 🔑 will get you data from YouTube search results. You can also add as many search terms as you want.
| Scraping by URL | Paste a YouTube link to a YouTube video, channel, playlist, or search results page. You can also import a CSV file or Google Sheet with a prepared list of URLs. Then choose how many results you would like to extract and click Start. |
| Scraping using search term | Type in keywords as you would normally do it in the YouTube search bar. Then choose how many results you would like to extract and click Start. |
⬆️ Output example
The scraped results will be shown as a dataset which you can find in the Storage tab. Note that the output is organized as a table for viewing convenience, but it doesn’t show all the fields:
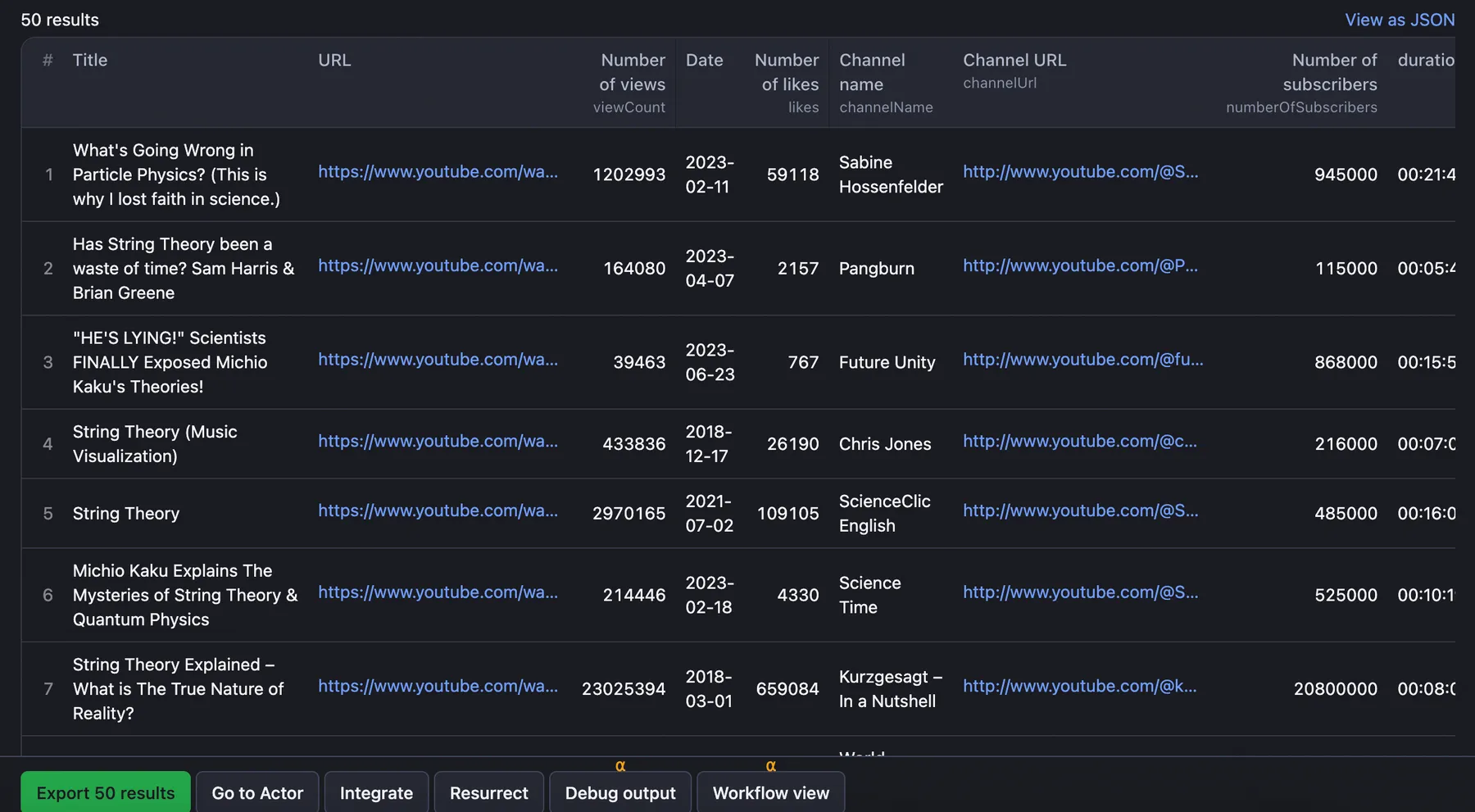
You can preview all the fields and download the file with YouTube data in various formats (JSON, CSV, Excel, and more). Here’s a few JSON examples of different YouTube scraping cases:
💁♂️ Channel info
📹 A single video
🎧 YouTube playlist
🔎 YouTube search results
How much will scraping YouTube cost you?
When it comes to scraping, it can be challenging to estimate the resources needed to extract data as use cases may vary significantly. That's why the best course of action is to run a test scrape with a small sample of input data and limited output. You’ll get your price per scrape, which you’ll then multiply by the number of scrapes you intend to do.
Watch this video for a few helpful tips. And don't forget that choosing a higher plan will save you money in the long run.
How to scrape YouTube data
You can scrape YouTube data by search term or a direct URL of a video, search results page, playlist, or channel. If both fields are filled out, the scraper prioritizes the URLs. Check out how to scrape YouTube in this step-by-step tutorial or this video.
How to use data scraped from YouTube
You can use this YouTube API to scrape data in order to:
- Monitor the market: see mentions of your brand, the position of your content in search results or get insights into the activity of competitors
- Find current trends and opinions shared by content creators and commenting users
- Filter your search results based on more advanced criteria
- Identify harmful or illegal content
- Scrape subtitles for offline reading or increased accessibility
- Accumulate information on products and services from video reviews and automate your buying decisions
Need to scrape YouTube comments or Shorts?
If you want to extract specific YouTube data, you can use one of the specialized scrapers below, each built particularly for the relevant YouTube data scraping case, whether it's Shorts, comments, or channels:
| 💬 YouTube Comments Scraper | 🏎 Fast YouTube Channel Scraper | ▶️ YouTube Shorts Scraper |
If you need to download scraped YouTube videos, you can use YouTube Video Downloader ⬇️.
We also have other video-related scrapers in stock for you; to see more of those, check out the Video APIs in Apify Store or the compilation of Social media scrapers.
❓FAQ
Can I scrape dislikes from YouTube videos?
No. Both dislike and details properties have been removed altogether from new versions. Dislikes are not public info so you cannot scrape them.
Can I scrape subtitles from YouTube videos?
Yes. You can scrape all publicly available data from YouTube using a web scraper, including subtitles. Using this scraping tool, you can extract both autogenerated and added subtitles in SRT, WEBVTT, XML, or plain text format.
Can I integrate this YouTube scraper with other apps?
Last but not least, YouTube Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with LangChain, Make, Trello, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, Asana, and more.
You can also use webhooks to carry out an action whenever an event occurs, e.g., get a notification whenever YouTube Scraper successfully finishes a run.
Can I use YouTube Scraper with the API?
The Apify API gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Check out the Apify API reference docs for full details or click on the API tab for code examples.
Should I use a proxy when scraping YouTube?
Just like with other social media-related actors, using a proxy is essential if you want your scraper to run properly. You can either use your own proxy or stick to the default Apify Proxy servers. Datacenter proxies are recommended for use with this Actor.
Is it legal to scrape data from YouTube?
Scraping YouTube is legal as long as you adhere to regulations concerning copyright and personal data. This scraper deals with cookies and privacy consent dialogs on your behalf, so be aware that the results from your YouTube scrape might contain personal information.
Personal data is protected by GDPR (EU Regulation 2016/679), and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, please consult your lawyers. You can also read our blog post on the legality of web scraping.
Your feedback
We're always working on improving the performance of our Actors. So if you've got any technical feedback on YouTube Scraper, or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.
On this page
Share Actor: