Website Crawler API — Markdown for RAG
Pricing
from $2.00 / 1,000 page crawleds
Website Crawler API — Markdown for RAG
Website crawler API for public pages and clean Markdown, text, or HTML output for RAG pipelines, AI agents, documentation indexing, and monitoring. Guide: https://konabayev.com/tools/website-content-crawler/?utm_source=apify_info&utm_medium=referral&utm_campaign=website-content-crawler
Pricing
from $2.00 / 1,000 page crawleds
Rating
0.0
(0)
Developer
Tugelbay Konabayev
Maintained by CommunityActor stats
0
Bookmarked
29
Total users
3
Monthly active users
19 days ago
Last modified
Categories
Share
Website crawler API for public pages: follow bounded same-site links and return source URL, title, clean Markdown/text/HTML, status, metadata, and crawledAt for RAG, documentation indexing, monitoring, and AI agents.
Fast first run — the default input crawls a small 15-page sample. HTTP-first crawler — designed for static or mostly static public pages without browser overhead. RAG-ready output — clean Markdown, text, or HTML with metadata for AI agents and knowledge bases. Pay-per-use after — $0.003/page for extracted dataset rows.
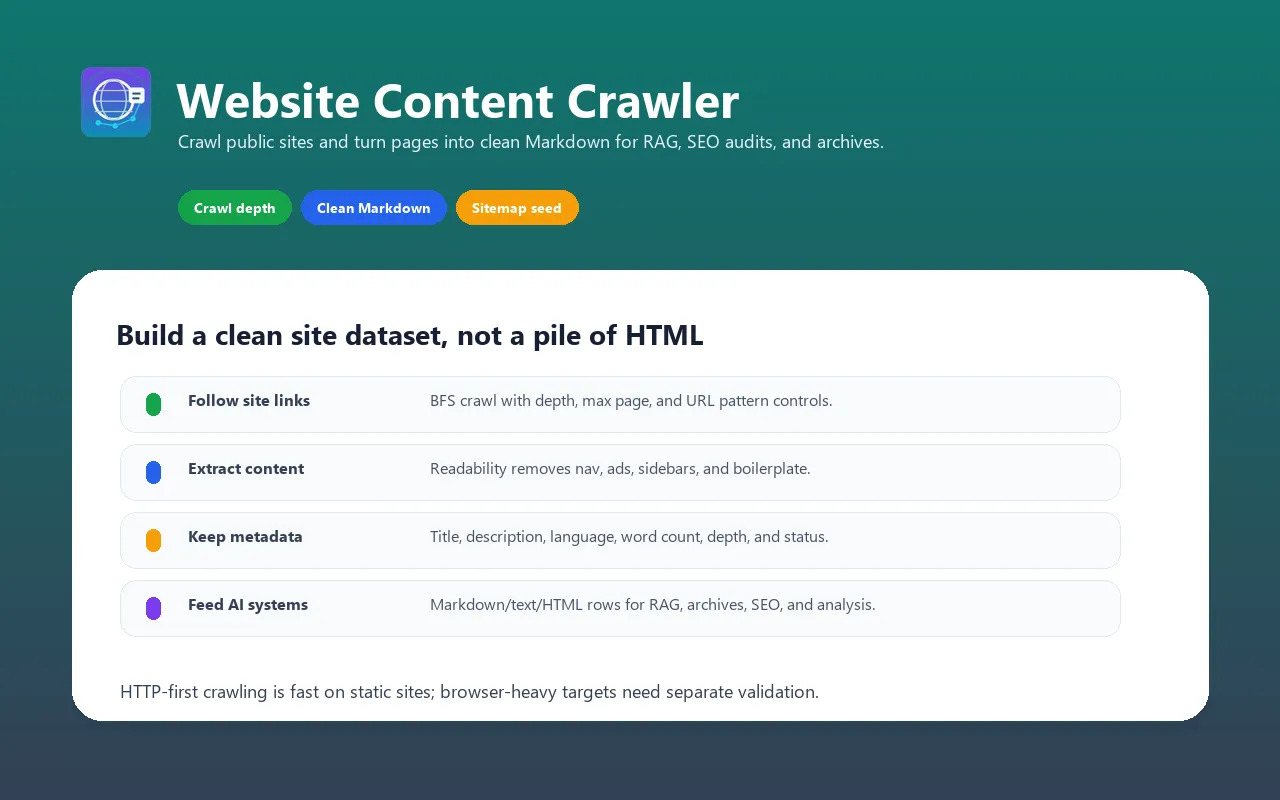

Crawl public websites following links with configurable depth and breadth-first search (BFS). Extract clean Markdown/text/HTML content from pages using Mozilla Readability. The HTTP-first architecture is best for static or mostly static sites and public documentation.
Perfect for: Building knowledge bases, RAG pipelines, AI training datasets, competitive intelligence, SEO analysis, and content archiving at scale.
For implementation recipes and production examples, see the Website Content Crawler guide on Konabayev.com.
Crawl Websites and Extract Clean Markdown
Recursively crawl public websites and extract page content as clean Markdown. HTTP-first crawling is fastest on static or mostly static pages.
Website Scraper for RAG and LLM Knowledge Bases
Ingest entire documentation sites, blogs, or knowledge bases into your AI pipeline. Clean Markdown output ready for vector embeddings.
Fast Website Content Extractor
HTTP-first crawling with depth control, link filtering, and incremental output.
What does Website Content Crawler do?
This actor starts from one or more seed URLs, crawls the website following same-domain links, and extracts clean content from every page discovered. It:
- Follows links intelligently — BFS crawling with configurable depth, max pages, and URL pattern matching (include/exclude globs)
- Extracts clean content — Uses Mozilla Readability algorithm (same tech as Firefox Reader View) to extract just the main content, removing navigation, ads, sidebars, and boilerplate
- Produces structured output — Markdown (optimized for LLMs), plain text, or clean HTML with auto-extracted metadata
- Crawls fast — HTTP-first (no browser) with up to 50 concurrent requests; throughput depends on the target site
- Extracts metadata — Title, description, author, language, Open Graph image, word count, depth, and HTTP status
- Handles sitemaps — Optionally load URLs from XML sitemaps to seed crawling faster
- Supports proxies — Datacenter, residential, or ISP proxies for geo-restricted or IP-blocked sites
- PPE pricing — Pay per extracted dataset row
No custom CSS selectors, no per-site configuration, no browser headaches. Just add URLs and let it crawl.
Why use this instead of alternatives?
| Feature | Generic scraper | Browser-heavy crawler | Website Content Crawler |
|---|---|---|---|
| Architecture | Varies | Browser sessions | HTTP + concurrent requests |
| Content extraction | Raw HTML / CSS selectors | Whole-page extraction | Clean article text via Readability |
| Output quality | Often needs cleanup | May include page boilerplate | Clean, LLM-ready Markdown |
| Concurrent requests | Usually conservative | Limited by browser overhead | Up to 50 parallel (configurable) |
| Link following | Manual or custom logic | Varies | BFS with depth, max, glob patterns |
| Sitemap support | Usually custom | Varies | Yes |
| AI/MCP compatible | Usually custom | Varies | Yes |
| Proxy support | Varies | Varies | Apify proxy support |
When to use each:
- Use Website Content Crawler when you need clean content for LLMs, RAG, or knowledge bases
- Use a browser-heavy crawler when the target site requires JavaScript rendering
- Use a generic scraper if you need custom selectors or non-article content
Features
- Breadth-First Search (BFS) crawling with configurable depth and maximum page limits
- Same-domain link following with automatic URL normalization and deduplication
- URL pattern filtering — include/exclude URLs via glob patterns (e.g.,
**/blog/**,!**/admin/**) - Sitemap support — optional XML sitemap loading to seed crawling faster
- Clean content extraction using Mozilla Readability algorithm (no custom selectors needed)
- Multiple output formats — Markdown (optimized for LLMs), plain text, or clean HTML
- Automatic metadata extraction — title, description, author, language, Open Graph image, word count
- Concurrent crawling — up to 50 parallel HTTP requests for speed
- Proxy support — Apify proxy, datacenter, residential, or ISP proxies with smart escalation
- Graceful error handling — retries failed requests, logs errors, returns partial results
- HTTP/2 and connection pooling for maximum efficiency
- PPE pricing — pay only for successfully extracted pages
How to run a bounded website crawl
- Start with one public URL, a shallow depth, and a 15-page limit.
- Inspect status, source URLs, extracted content, metadata, and
crawledAt; tighten include/exclude patterns before scaling. - Export the validated pages to the RAG or monitoring pipeline and recrawl only at a justified interval.
Input examples
Crawl a website and extract all content as Markdown
Crawl a blog with depth limit, exclude admin pages
Crawl with sitemap and proxy for geo-restricted content
Crawl documentation site as plain text with high concurrency
Crawl multiple domains with depth limits
Input parameters
| Parameter | Type | Default | Required | Description |
|---|---|---|---|---|
startUrls | Array | — | Yes | List of seed URLs to start crawling from (requestListSources format) |
maxCrawlDepth | Integer | 10 | No | Maximum link depth to follow (0 = seed URLs only, 1 = seed + direct links, etc.) |
maxCrawlPages | Integer | 50 | No | Maximum pages to crawl per domain (1–10,000). Crawling stops when this limit is reached |
outputFormat | String | markdown | No | Output format: "markdown", "text", or "html" |
includeUrlGlobs | Array | ["**"] | No | Glob patterns to INCLUDE (e.g., ["**/blog/**", "**/docs/**"]). Default: all URLs included |
excludeUrlGlobs | Array | [] | No | Glob patterns to EXCLUDE (e.g., ["**/admin/**", "**/?utm_*"]). Overrides include patterns |
useSitemap | Boolean | false | No | Load URLs from XML sitemap (sitemap.xml) at domain root. Speeds up discovery. |
maxConcurrency | Integer | 20 | No | Number of pages to process simultaneously (1–50). Higher = faster but more resource-intensive |
pageTimeout | Integer | 30 | No | Timeout per page request in seconds (5–120). Increase for slow servers. |
proxyConfiguration | Object | None | No | Proxy settings for accessing IP-blocked or geo-restricted content |
Output format
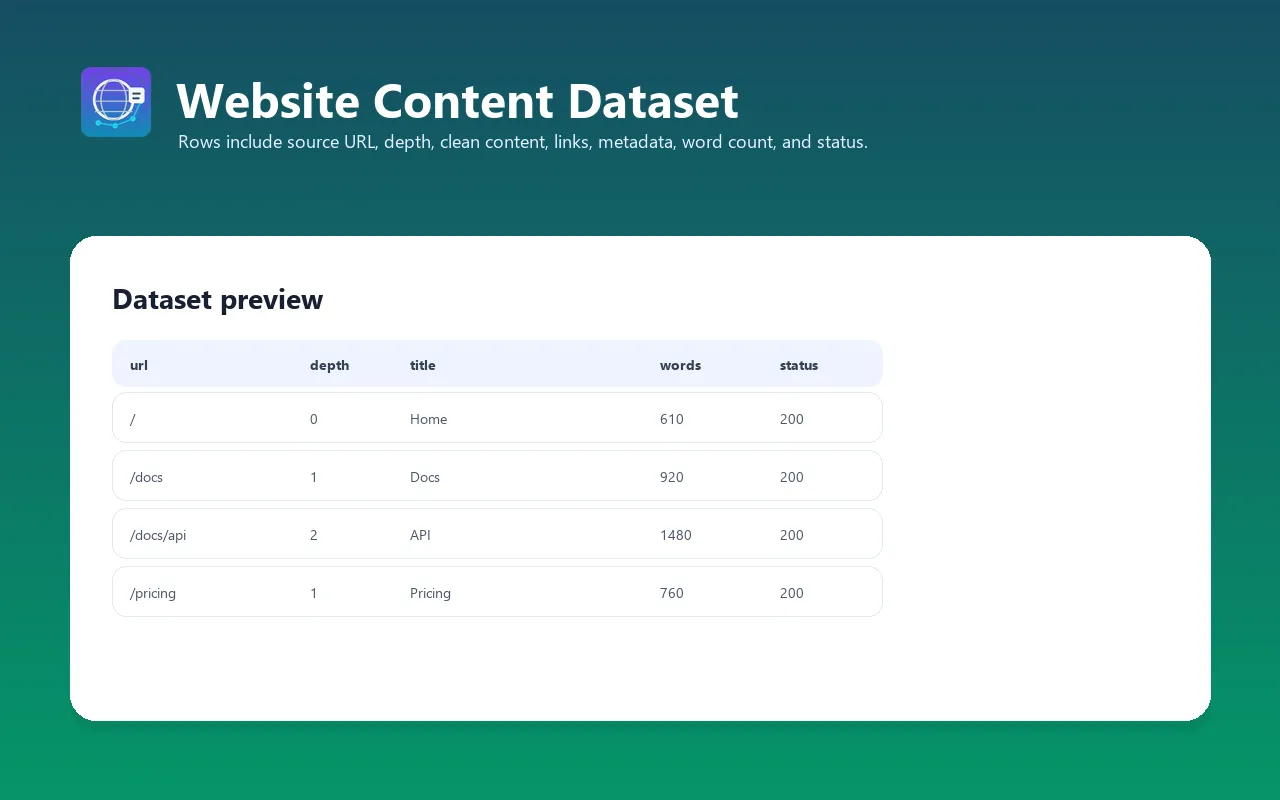
Each item in the dataset contains extracted content from one crawled page:
| Field | Type | Description |
|---|---|---|
url | String | Final page URL (after redirects) |
title | String | Page title (from <title> tag or h1) |
description | String | Meta description or auto-generated summary |
author | String | Author (from meta tags or JSON-LD, if available) |
language | String | Detected content language code (e.g., "en", "de", "fr") |
content | String | Extracted page content in requested format (Markdown/text/HTML) |
wordCount | Integer | Number of words in extracted content |
depth | Integer | Link depth from seed URL (0 = seed, 1 = one link away, etc.) |
statusCode | Integer | HTTP response status code (200, 404, 403, etc.) |
crawledAt | String | Crawling timestamp (ISO 8601) |
error | String | Error message if crawling failed (null on success) |
Example output
Integrations
Apify MCP Server (Claude, AI agents)
Use as a tool in Claude Desktop, Claude Code, or any MCP-compatible AI agent. PPE pricing makes it native to AI workflows.
Python integration
JavaScript/TypeScript integration
LangChain integration (RAG pipeline)
Webhooks and integrations
The actor integrates with Apify's ecosystem:
- Google Sheets — export crawled content directly to a spreadsheet
- Zapier / Make — trigger workflows when crawling completes
- Slack — notify your team with crawl summary (pages found, errors, etc.)
- Email — receive dataset as CSV/JSON attachment
- REST API — call programmatically from any application
- Apify Schedules — run crawls on a schedule (hourly, daily, weekly, custom cron)
Use cases
- Knowledge base building — crawl documentation sites, internal wikis, or company knowledge bases and feed content into a vector database for semantic search
- LLM training data — extract clean text from websites for fine-tuning datasets or pre-training
- RAG pipelines — crawl public documentation (API docs, guides, tutorials) and make it searchable via retrieval-augmented generation
- Competitive intelligence — crawl competitor websites to monitor features, pricing, and messaging changes
- SEO analysis — extract all page titles, meta descriptions, and h1/h2 headers for gap analysis and content strategy
- Content archiving — automatically archive entire website snapshots for compliance, legal holds, or historical records
- Content migration — extract content from legacy sites during CMS migrations to new platforms
- AI agent enhancement — give your AI agent the ability to read and understand entire websites, not just single pages
- News and blog aggregation — crawl news sites or blog networks to collect articles at scale
- Price monitoring — crawl e-commerce sites to extract product pages, prices, and availability (per ToS)
Cost estimation (PPE pricing)
Event: one primary dataset event for each successfully crawled and stored page. As of 2026-07-14, the price is $0.003 on FREE, $0.0027 on BRONZE, $0.0024 on SILVER, and $0.002 on GOLD+, plus a $0.005 Actor start event. The Store Pricing tab is authoritative.
Example costs:
| Scenario | Pages | Cost |
|---|---|---|
| 10-page documentation site | 10 | ~$0.03-$0.04 |
| 50-page company website | 50 | ~$0.11-$0.16 |
| 100-page blog with archives | 100 | ~$0.21-$0.31 |
| 500-page documentation + tutorials | 500 | ~$1.01-$1.51 |
| 1,000-page knowledge base | 1,000 | ~$2.01-$3.01 |
| Daily crawls (50 pages/day, 30 days) | 1,500 | ~$3.15-$4.65/month |
| Weekly competitor monitoring (10 sites, 20 pages each) | 200/week | ~$0.41-$0.61/week |
| Large-scale extraction (10,000 pages) | 10,000 | ~$20.01-$30.01 |
The weekly competitor-monitoring estimate assumes all 10 sites are crawled in one Actor run. Running one site per task would add 10 start events, for roughly $0.45-$0.65 per week at the same 200-page total.
Start with the default small sample to evaluate output quality before larger crawls.
💡 Pro tip: Exclude large file downloads (PDFs, images) and non-content pages (admin panels, login forms) via excludeUrlGlobs to reduce extraction costs and improve data quality.
FAQ
How fast is the crawling?
Very fast. HTTP-only architecture with up to 50 concurrent requests means you can crawl 50 pages in 30–60 seconds with default settings. Increase maxConcurrency to 50 for even faster crawling on small/medium sites. Compare: the free Playwright-based actor takes 14 minutes for the same 50 pages.
What's the difference between this and apify/website-content-crawler?
- Speed: HTTP-first crawling is fastest on static or mostly static sites
- Content quality: Ours uses Readability to extract clean article text; the free one returns full page HTML
- Pricing: Ours uses PPE (pay per extracted page); free one is unpaid but supports no AI/MCP workflows
- Features: Both support BFS crawling, but ours adds sitemap support and better URL filtering
- Users: Free has 5,743 users; ours is new but PPE-native for AI agents
Choose ours if you need speed, clean content, and LLM optimization. Choose the free one if you need full page HTML and can tolerate slow speeds.
Does it handle JavaScript-rendered content?
No. Website Content Crawler uses HTTP requests (no browser). If a site relies on JavaScript to render content (React SPAs, Angular apps, dynamic comments), you'll get incomplete or empty content. For JS-heavy sites, use RAG Web Browser, which has Playwright fallback.
Can I crawl password-protected or paywalled sites?
No. Website Content Crawler only works with publicly accessible content. It cannot bypass login walls, paywalls, HTTP Basic Auth, or CAPTCHA-protected pages. Use a different tool for authenticated access.
What happens if a page fails to load?
The actor logs the error and continues crawling other pages. Failed pages are included in the dataset with an error field explaining the failure (timeout, 404, blocked, etc.) and null content. Partial results are always returned.
Can I crawl multiple domains?
Yes. Add multiple startUrls and the crawler will crawl each domain independently, following links within each domain only (not cross-domain).
How do URL glob patterns work?
includeUrlGlobs: Whitelist — only crawl URLs matching these patterns (default:["**"]= all)excludeUrlGlobs: Blacklist — skip URLs matching these patterns
Examples:
"**/blog/**"— include only blog URLs"!**/admin/**"— exclude admin pages"**/docs/**"— include only documentation"!**/?utm_*"— exclude UTM tracking parameters
Both can be used together. Excludes override includes.
What output formats are available?
- Markdown (default) — clean, semantic, optimized for LLMs with preserved headers, lists, links, emphasis
- Plain text — raw text with minimal formatting, good for NLP/text analysis
- HTML — clean semantic HTML (not raw page HTML), good for rendering or further processing
Can I run this on a schedule?
Yes. Create a Schedule in Apify Console to run the crawler at any interval — hourly, daily, weekly, or custom cron. Perfect for monitoring website changes, tracking competitor updates, or archiving content regularly.
What's the maximum crawl size?
Soft limit: 10,000 pages per run (configurable via maxCrawlPages). No hard technical limit, but very large crawls (100K+ pages) will take a long time and incur higher costs. For massive crawls, split into multiple runs targeting specific sections of the site.
How does it handle redirects and canonicals?
The actor follows HTTP redirects and respects canonical tags (rel="canonical"). The final url field shows the final URL after any redirects.
Troubleshooting
Empty or very short content extraction
- Cause: The page is a SPA (Single Page Application) that requires JavaScript to render
- Fix: Use RAG Web Browser instead, which falls back to browser rendering
- Workaround: Very short pages (<100 words) may not have enough content for Readability to identify. This is expected.
Crawling stops prematurely
- Cause: Hit
maxCrawlPageslimit before exploring all links - Fix: Increase
maxCrawlPagesin the run input - Alternative: Reduce
maxCrawlDepthto focus on top-level pages only
Missing links or pages not being followed
- Cause: URL glob patterns are excluding them, or links are outside the start domain
- Fix: Check
includeUrlGlobsandexcludeUrlGlobs— verify they match intended URLs - Note: Cross-domain links are never followed (same-domain only for security)
Timeout errors on slow servers
- Cause: Server is slow to respond and
pageTimeout(default 30s) is exceeded - Fix: Increase
pageTimeoutto 60–120 seconds for very slow servers - Alternative: Reduce
maxConcurrencyto avoid overwhelming the target server
Proxy-related errors (IP blocks, CAPTCHAs)
- Cause: Target site is blocking requests from datacenter IPs
- Fix: Enable Apify residential proxy in
proxyConfiguration:{"proxyConfiguration": {"useApifyProxy": true,"apifyProxyGroups": ["RESIDENTIAL"]}} - Note: Residential proxies cost more but bypass IP blocks. Start with datacenter, escalate only if needed.
Validation evidence and web standards (2026-07-14)
Validation on 2026-07-14 establishes a bounded crawler contract:
- RFC 9309 defines the Robots Exclusion Protocol.
- MDN's HTTP status reference documents response statuses that downstream users should retain and interpret.
- Results preserve source URL, status, content fields, and
crawledAt; point-in-time snapshots require recrawling when freshness matters. - Strict Actor QA validates schemas, links, metadata, Docker configuration, crawl defaults, and PPE declarations before release.
Users must follow target-site terms, robots rules, copyright, privacy, rate limits, and access controls. This evidence does not grant republication rights or guarantee complete rendering, indexation, rankings, traffic, or AI citations.
Support
Send the run ID, public start URL, depth/limit, expected page, observed status, and visible error. Do not send cookies, credentials, paywalled pages, or private documents.
Limitations
- JavaScript-rendered content: Only extracts server-side rendered HTML. JS-heavy SPAs will return empty/incomplete content.
- Authentication: Cannot access login-protected or paywalled content
- Maximum page size: 5MB per page (larger pages are truncated to prevent memory issues)
- Cross-domain crawling: Only follows links within the same domain (security & performance)
- Rate limiting: Respects robots.txt and Crawl-Delay headers; may slow down on strictly rate-limited sites
- Real-time data: Extracted content is a point-in-time snapshot; dynamic or frequently updated content requires re-crawling
- Maximum concurrent requests: Limited to 50 for stability; higher concurrency may trigger IP blocks on some sites
- Storage: Dataset size depends on site size; very large crawls (10K+ pages with lots of content) may hit storage limits
Changelog
v1.0 (2026-03-29)
- Initial release
- Breadth-First Search (BFS) crawling with configurable depth and max pages
- Same-domain link following with URL normalization
- URL glob pattern filtering (include/exclude)
- XML sitemap support for faster discovery
- Mozilla Readability-based content extraction
- Multiple output formats: Markdown, plain text, clean HTML
- Metadata extraction: title, description, author, language, word count
- Concurrent crawling (up to 50 parallel requests)
- Proxy support (Apify, datacenter, residential)
- PPE pricing
- Full Apify SDK integration
Related Actors
- RAG Web Browser — Search Google + extract as Markdown for AI agents
- Article Extractor — Extract clean article text from any URL
- YouTube Transcript Extractor — Bulk extract video transcripts as SRT/VTT/Markdown
- Website Tech Stack Detector — Identify 80+ technologies on any website
- Google Maps Lead Extractor — Extract business leads with emails from Google Maps
See all actors: apify.com/tugelbay