YouTube Transcript Generator API & Subtitle Downloader
Pricing
from $7.00 / 1,000 transcript extracteds
YouTube Transcript Generator API & Subtitle Downloader
YouTube transcript generator API for bulk SRT/VTT, Markdown, JSON, and text exports with metadata for AI/RAG, research, subtitles, and content workflows. Guide: https://konabayev.com/tools/youtube-transcript-scraper/?utm_source=apify_info&utm_medium=referral&utm_campaign=youtube-transcript
Pricing
from $7.00 / 1,000 transcript extracteds
Rating
0.0
(0)
Developer
Tugelbay Konabayev
Maintained by CommunityActor stats
0
Bookmarked
35
Total users
3
Monthly active users
12 days ago
Last modified
Categories
Share
YouTube transcript generator and subtitle downloader API: submit public video URLs and export available captions as timestamped JSON, SRT, VTT, Markdown, PDF, or text with video metadata and extractedAt for RAG, research, and accessibility workflows.
Start with a small production sample — process 3-10 YouTube URLs, verify caption availability and output format, then scale the same input pattern. Built for bulk transcript jobs — run a URL list and keep timestamped text, metadata, and subtitle exports in one Apify dataset. Pay per output row — check the Pricing tab for current plan-specific rates before scaling large batches.
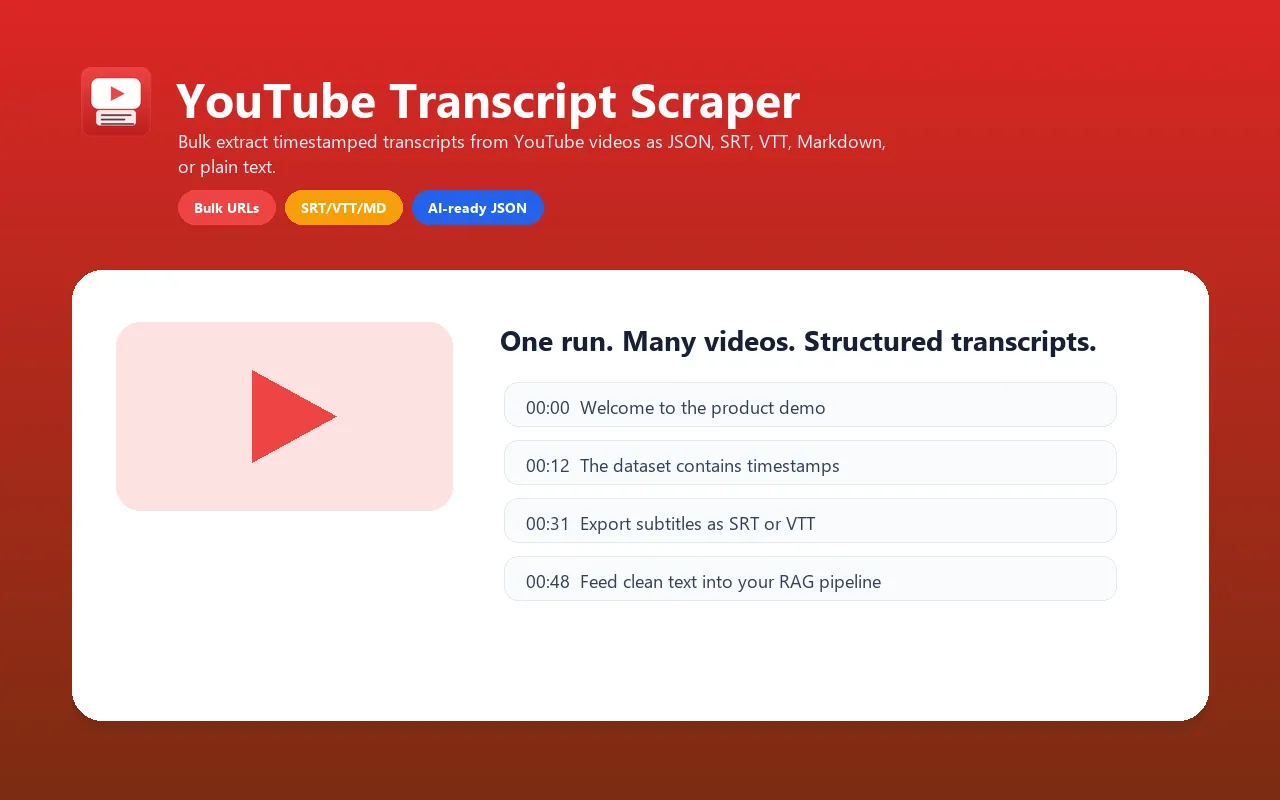

Extract transcripts from YouTube videos with timestamps, metadata, and multi-format output. Use it as a YouTube transcript API and subtitle downloader for AI agents, RAG pipelines, SRT/VTT export, content repurposing, research, SEO workflows, and production bulk video-to-text jobs.
For implementation notes, examples, and SEO/GEO use cases, see the YouTube Transcript API guide.
Extract YouTube Video Transcripts in Bulk
Process one URL or a large batch of YouTube video URLs in a single run. Extract transcripts with timestamps in 6 formats.
YouTube Subtitle Downloader — SRT, VTT, Markdown, PDF
Download video captions as SRT (for video editors), VTT (for web players), Markdown or PDF (for documentation), plain text, or structured JSON.
YouTube Transcript for AI and RAG Datasets
Extract video transcripts at scale for RAG datasets, content analysis, research workflows, and internal video libraries.
YouTube Transcript API for ChatGPT, Claude, RAG, and Agents
Turn YouTube videos into structured text that AI systems can actually use:
- Feed transcripts into ChatGPT, Claude, Gemini, or custom LLM workflows
- Build RAG datasets from webinars, podcasts, tutorials, interviews, and lectures
- Store each video as timestamped JSON for search, citations, and retrieval
- Export Markdown for Notion, docs, blogs, or long-form summaries
- Use SRT/VTT when the final output is subtitles rather than pure text
YouTube Video to Text, Captions, and Subtitles
This actor is optimized for high-intent transcript jobs:
- YouTube transcript API — call from Python, JavaScript, CLI, HTTP, Zapier, Make, n8n, or Apify MCP
- YouTube subtitle downloader — export SRT or VTT with timecodes
- YouTube video to text — return clean plain text for summaries and notes
- YouTube Shorts transcript extractor — supports Shorts URLs when captions are available
- Bulk YouTube transcript scraper — process URL lists and keep one structured Apify dataset
What Does It Do?
This actor downloads transcripts from YouTube videos and converts them into six different formats:
- JSON — segments array with timestamps (start time, duration, text) — ideal for programmatic processing and AI/LLM integration
- SRT — SubRip subtitle format — compatible with all video editors and subtitle tools
- VTT — WebVTT subtitle format — for web players and modern subtitle systems
- Markdown — human-readable with inline timestamps — useful for documentation and blogs
- Plain text — transcript text without timestamps — for simple text-based workflows
- PDF — a readable timestamped report stored in the run key-value store with a direct URL in the dataset
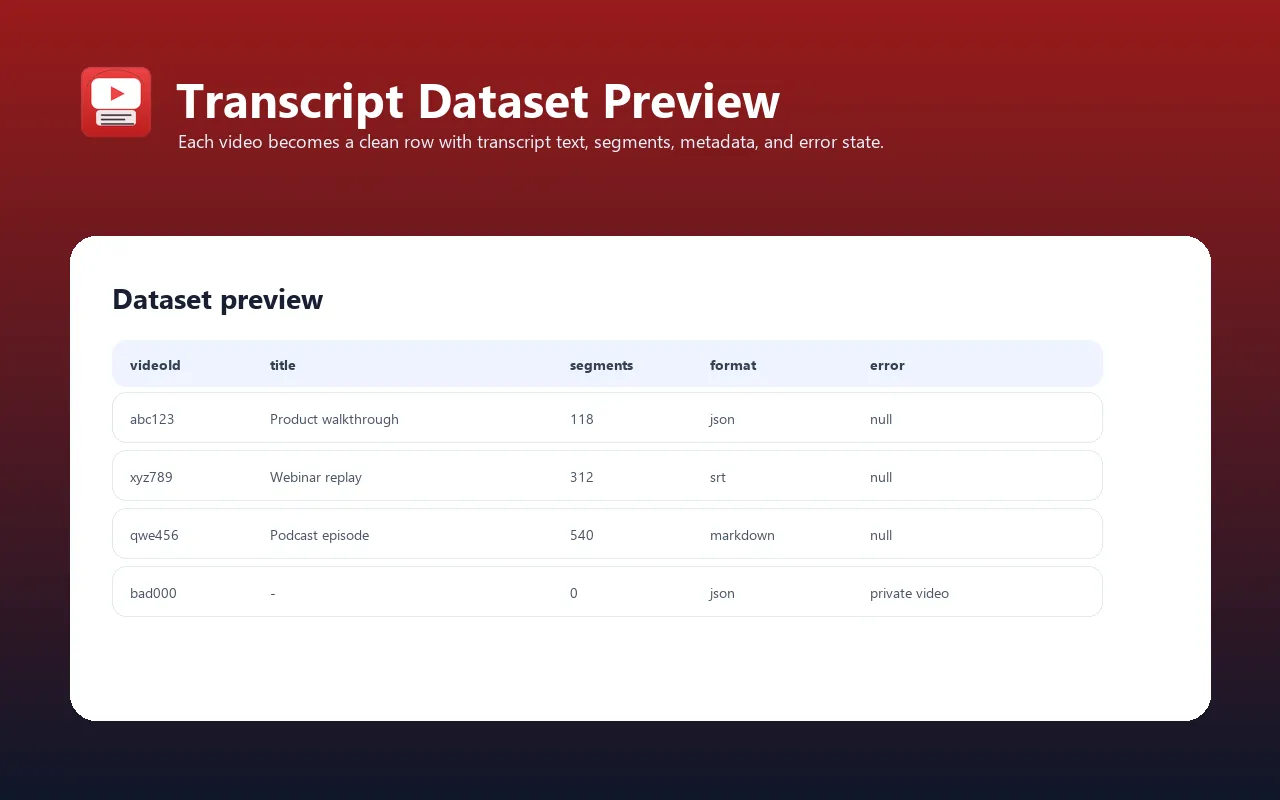
Each output includes video metadata: title, channel name, thumbnail URL, language, segment count, and extraction timestamp.
Key advantage: one Apify actor for bulk transcript extraction, subtitle files, timestamped JSON, Markdown, metadata, API access, and clean per-video error rows.
Why use it: transcript workflow fit
Use this actor when you need an API and dataset workflow for YouTube captions instead of a manual copy-paste transcript tool:
| Need | This actor |
|---|---|
| Bulk URL input | Yes |
| JSON with timestamped segments | Yes |
| SRT subtitle export | Yes |
| VTT subtitle export | Yes |
| Markdown with inline timestamps | Yes |
| Downloadable PDF report | Yes |
| Plain text transcript | Yes |
| Metadata in the same row | Title, channel, thumbnail |
| Manual + auto-generated captions | Yes |
| Apify API / MCP compatibility | Yes |
| Per-video error rows | Yes |
Features
- Bulk processing — Handle one video or a large URL list in a single run. No local scripts, no manual loops, one dataset.
- Six output formats — JSON (programmatic), SRT (video editors), VTT (web players), Markdown (readable docs), PDF (shareable reports), plain text (simplicity).
- Full timestamp precision — Every segment includes start time and duration (in seconds). Perfect for timestamped links and video navigation.
- Smart language fallback — Request English; get auto-generated captions if manual transcripts are unavailable. Or accept any available language.
- Video metadata extraction — Title, channel name, thumbnail URL, and video ID — all in one payload. No separate oEmbed API call needed.
- Transcript detection — Automatically detects whether captions are manual or auto-generated and reports in output.
- Graceful error handling — Video unavailable, transcripts disabled, no transcript in requested language? Detailed error message per video. Run continues.
- Proxy-ready — Uses Apify Residential Proxy by default. YouTube blocks cloud IPs; proxy configuration is pre-integrated.
- Fast enough for batch workflows — No browser rendering or video download. Runtime depends on caption availability, proxy latency, and batch size.
- Pay-per-event pricing — billed per successful transcript extraction. Check the public Pricing tab for current plan-specific rates before scaling large batches.
How to run a transcript job
- Start with 3-10 public video URLs and one output format.
- Inspect caption availability, language, segment timestamps, metadata, per-video errors, and
extractedAt. - Scale the same validated input pattern and retain video/source URLs for citation and rights checks.
Input Parameters
Required
| Parameter | Type | Description |
|---|---|---|
urls | Array of strings | YouTube video URLs or IDs. Accepts standard URLs (https://www.youtube.com/watch?v=pKgup8tsPv8), short URLs (https://youtu.be/iFWRZ3U_P5k), Shorts URLs, embed URLs, and raw video IDs (fYo22FnrPhg). |
Optional
| Parameter | Type | Default | Description |
|---|---|---|---|
outputFormat | string | json | Output format. Options: json (segments with timestamps), text, srt, vtt, markdown, or pdf (downloadable timestamped report). |
language | string | en | Language code for transcript (e.g., en, es, fr, ja, zh, de). If not available, falls back to auto-generated or any available language. |
includeAutoGenerated | boolean | true | If manual transcript not available, also try auto-generated captions. |
includeMetadata | boolean | true | Extract and include video metadata (title, channel, thumbnail, duration). Disabling may speed up processing slightly. |
maxItems | integer | 10 (max 10,000) | Maximum number of videos to process in this run. Useful for controlling costs on large URL lists. |
proxyConfiguration | object | { "useApifyProxy": true, "apifyProxyGroups": ["RESIDENTIAL"] } | Proxy settings. YouTube blocks cloud IPs. Default uses Apify Residential Proxy. Can override with custom proxy URL. |
Output Fields
Per-Video Result
| Field | Type | Description |
|---|---|---|
videoId | string | 11-character YouTube video ID (extracted from URL). |
videoUrl | string | Full YouTube video URL (https://www.youtube.com/watch?v={videoId}). |
title | string | null | Video title (from oEmbed API). null if metadata extraction failed. |
channel | string | null | Channel/author name (from oEmbed API). null if metadata extraction failed. |
thumbnailUrl | string | null | High-resolution thumbnail URL. null if metadata extraction failed. |
language | string | null | Language code of the transcript found (e.g., en, es). null if no transcript available. |
isAutoGenerated | boolean | null | true if transcript is auto-generated captions; false if manual captions. null if no transcript available. |
segmentCount | integer | Number of segments/lines in transcript. 0 if error. |
segments | array | null | JSON format only. Array of segment objects: [{ "text": "...", "start": 12.5, "duration": 3.2 }, ...]. Start time in seconds. Duration in seconds. null for other formats. |
transcriptText | string | Plain text transcript (segments joined with spaces). Always populated when transcript is available. |
transcriptSrt | string | null | SRT format only. Complete SRT subtitle file (numbered segments with HH:MM:SS,mmm timecodes). null for other formats. |
transcriptVtt | string | null | VTT format only. Complete WebVTT subtitle file (HH:MM:SS.mmm format). null for other formats. |
transcriptMarkdown | string | null | Markdown format only. Markdown text with inline timestamps **[MM:SS]** segment text. null for other formats. |
transcriptPdfKey | string | null | PDF format only. Record key in the run's default key-value store. |
transcriptPdfUrl | string | null | PDF format only. Direct Apify API URL for the generated PDF record. Private stores require a scoped read token. |
error | string | null | Error message if transcript extraction failed. Examples: "No transcript available for video {id}", "Transcripts are disabled for this video", "Video is unavailable or private". null on success. |
extractedAt | string | ISO 8601 timestamp (UTC) when transcript was extracted. |
Input Examples
Example 1: Single Video → JSON with Metadata (Simplest)
Output: JSON segments with title, channel, thumbnail.
Example 2: Bulk URLs → SRT Subtitles (Multiple Videos)
Output: SRT subtitle files for up to 10 videos. Ready to import into DaVinci Resolve, Premiere, or any video editor.
Example 3: Preferred Language with Auto-Generated Fallback
Output: Markdown transcripts in the requested language when available. If Spanish manual captions are not available, the actor tries auto-generated Spanish, then falls back to any available transcript language.
Example 4: Bulk Transcripts → JSON, No Metadata (Fast Mode)
Output: Pure JSON segments (no oEmbed calls). Faster processing, lower latency.
Example 5: Custom Proxy Configuration
Output: Uses custom proxy instead of Apify Residential Proxy. Useful for on-premise or private proxy setups.
Example Output
JSON Format (with segments)
SRT Format (subtitles)
Markdown Format (with timestamps)
Error Case
Integrations
Python SDK
JavaScript/Node.js SDK
LangChain Integration (LLM + Transcripts)
MCP (Model Context Protocol) for Claude / LLM Agents
Export to File
Export as JSONL (one video per line):
Export as CSV:
Export as ZIP (all formats):
Use Cases
-
Content Creator Archiving — Extract transcripts from your own YouTube videos for documentation, blog posts, and searchable archives. Bulk process URL lists from a channel in one run.
-
Research & Literature Review — Transcribe educational videos, conference talks, and webinars. Convert to plain text for NLP analysis, topic modeling, or citation tracking.
-
SEO & Content Repurposing — Convert your own video transcripts to blog drafts, article briefs, and social media snippets. Bulk processing helps refresh a content library without manual copying.
-
Subtitle Creation — Generate SRT/VTT subtitle files for videos that have manual or auto-generated captions available.
-
Video Search & Indexing — Index YouTube transcripts full-text for internal video search. Extract metadata (title, channel, thumbnail) and segment timestamps for clickable search results.
-
AI and RAG Dataset Preparation — Use transcripts as structured text context for search, retrieval, summarization, and internal analysis workflows.
-
Podcast & Audio Content Analysis — Transcribe YouTube uploads of podcasts, interviews, and audio documentaries. Markdown format with timestamps works as a readable episode guide.
-
Educational Curriculum Building — Compile transcripts from course videos. Organize by topic, language, or creator. Convert to Markdown for e-books or learning materials.
-
Market Research & Topic Analysis — Extract public video transcripts for topic tracking, sentiment review, and messaging analysis where your use complies with platform and content rights.
-
Multilingual Transcript Workflows — Request Spanish, French, German, or any supported language and inspect the
languagefield to confirm what was returned.
Cost Estimation
YouTube Transcript API & Subtitle Downloader uses Pay-Per-Event (PPE) pricing. On 2026-07-14 the FREE-plan rate is $0.01 per stored video result plus a $0.005 Actor start event. The public Pricing tab is authoritative for current tiers.
YouTube transcript API comparison
| Route | Best for | Trade-off |
|---|---|---|
| This Actor | Bulk caption export into Apify datasets, schedules, API, and integrations | Only captions available to the retrieval route can be returned |
| Manual YouTube transcript view | One-off reading | No repeatable bulk dataset or multi-format export |
| Speech-to-text transcription | Videos without usable captions, with proper rights | Higher compute/cost and a different accuracy/consent model |
Use this Actor for available captions and structured exports. It does not create missing speech recognition, bypass private videos, or grant rights to reuse transcript content.
Pricing Examples
| Scenario | Videos | Cost | Notes |
|---|---|---|---|
| Single video | 1 | See Pricing tab | Minimal cost for testing |
| Small batch | 10 | See Pricing tab | Daily content review |
| Medium batch | 100 | See Pricing tab | Weekly channel archive |
| Large batch | 1,000 | See Pricing tab | Monthly bulk project |
| Bulk processing | 10,000 | See Pricing tab | Entire channel or research dataset |
| Failed videos | Any | See run output | Error rows explain unavailable videos, disabled transcripts, or language misses |
Cost Breakdown
- Transcript extraction: billed per successful transcript extraction
- Metadata (oEmbed): Returned in the same dataset row when
includeMetadatais enabled - Proxy usage: Uses the proxy settings from the actor input; check Apify account usage for platform-level proxy costs
- Format conversion: JSON, SRT, VTT, Markdown, and plain text are output-format options for the same transcript extraction
- Failed videos: Returned as error rows so you can inspect unavailable videos or disabled transcripts
When this is the right fit
Use this actor when you need transcript extraction as an API or dataset workflow rather than a manual web app:
- Bulk URL lists
- Repeatable Apify tasks and schedules
- JSON/CSV/JSONL export
- SRT/VTT subtitle files
- Markdown for summaries and documentation
- Downstream automation through Apify API, MCP, Make, Zapier, n8n, Google Sheets, or your own backend
FAQ
Q: Do I need a proxy?
A: Yes. YouTube detects and blocks cloud hosting IPs (where Apify runs). The actor uses Apify Residential Proxy by default. If you disable it, you'll get 403 errors. Custom proxies are supported via the proxyConfiguration parameter.
Q: What if a video doesn't have a transcript?
A: The result includes an error field explaining why: "Video is unavailable or private", "Transcripts are disabled for this video", or "No transcript in requested language". The run continues and keeps detailed error info per video.
Q: How many videos can I process in one run?
A: Up to 10,000 videos per run (configurable via maxItems). For operational reliability, recommended batches are 500–1,000 videos when processing very large lists.
Q: Can I get transcripts in multiple languages?
A: Not in a single run. Run the actor once per language. For example, to get both English and Spanish transcripts, run with language: "en" once, then language: "es" on the same URLs. Both results will be in your dataset (use filters to separate them).
Q: What timestamp format does it use?
A: JSON/Markdown: Seconds as decimal (e.g., 12.5 = 12.5 seconds). SRT: HH:MM:SS,mmm (e.g., 00:00:12,500). VTT: HH:MM:SS.mmm (e.g., 00:00:12.500). These formats preserve timestamp precision for subtitle and retrieval workflows.
Q: Does it handle YouTube Shorts?
A: Yes. Shorts with captions/transcripts are supported. Just pass the Shorts URL (for example, https://www.youtube.com/shorts/{videoId}). Note: Most Shorts don't have manual captions, so includeAutoGenerated: true is recommended.
Q: Can I use this with LangChain or other AI frameworks?
A: Yes. Use the Apify SDK or REST API to fetch transcripts, convert them to LangChain Document objects, and feed into vector stores, LLMs, or RAG pipelines. See the Integrations section for example code.
Q: What's the difference between "auto-generated" and "manual" captions?
A: Manual: Creator or translator wrote captions, usually more accurate. Auto-generated: YouTube's speech-to-text output, which may contain errors but is useful when manual captions are unavailable. The isAutoGenerated field tells you which you got. Set includeAutoGenerated: false if you want manual captions only (may result in "no transcript" errors).
Q: Can I filter or transform the output?
A: The actor outputs raw results to the dataset. Use Apify's Data Extraction or post-process with a downstream actor. Or download the dataset (JSON/CSV/JSONL) and transform locally. Example: filter for videos >1,000 segments, extract only transcriptText, convert to Markdown.
Q: How long does it take to process a batch?
A: Runtime depends on caption availability, proxy latency, metadata fetching, and batch size. For faster runs, keep includeMetadata enabled only when you need title/channel/thumbnail and split very large lists into 500–1,000 video batches.
Troubleshooting
Issue: "403 Forbidden" or "Video unavailable"
Cause: YouTube is blocking your request. Usually a cloud IP issue.
Solution:
- Ensure
proxyConfigurationis enabled (default: Apify Residential Proxy). - Check your Apify account has available proxy credits.
- Verify the video URL is public (not private/unlisted).
- Try a different proxy or contact Apify support.
Issue: "No transcript available for video {id}"
Cause: Video has no captions (manual or auto-generated) in the requested language.
Solution:
- Check the video on YouTube manually — does it have captions?
- If yes but in a different language, set
languageto that language code. - If no captions exist, this actor cannot create a transcript for that video.
- Ensure
includeAutoGenerated: true(default) to use auto-generated as fallback.
Issue: "Transcripts are disabled for this video"
Cause: Video creator explicitly disabled comments and transcripts.
Solution: None. Creator must enable transcripts in YouTube Studio. You cannot transcribe disabled videos.
Issue: "Request timeout" or "Connection reset"
Cause: Proxy or network latency. Rare but possible with very large batches or slow proxies.
Solution:
- Reduce
maxItemsand rerun (e.g., 500 instead of 5,000). - Try again; transient network errors usually resolve on retry.
- Check Apify's proxy status page.
- Use custom proxy if available.
Issue: Language fallback gave me wrong language
Cause: Requested language not found; actor fell back to available language.
Explanation: If you request language: "fr" but video only has English and Spanish, you'll get Spanish (first available). Set language: "en" and includeAutoGenerated: false to fail cleanly instead of falling back.
Solution: Check the language field in the result. If it doesn't match your request, manually re-request with explicit language or skip that video.
Validation evidence and YouTube terms (2026-07-14)
Validation on 2026-07-14 records the rights and source boundary:
- YouTube's current Terms of Service remain authoritative for platform use.
- Google's YouTube API Services Terms provide the official policy context for API-based YouTube services; this Actor is independent and not endorsed by YouTube.
- Output retains the video URL/ID, caption language, timestamped segments, errors, and
extractedAtfor verification. - Strict Actor QA validates schemas, metadata, links, Docker configuration, and PPE declarations before release.
Users are responsible for copyright, privacy, accessibility, and downstream-use compliance. This evidence does not guarantee caption availability, transcript accuracy, rankings, views, or AI citations.
Limitations
-
Requires Proxy — YouTube often blocks cloud IPs. Use Apify Residential Proxy or a custom proxy and monitor platform usage for your account.
-
Manual Captions Only (Optional) — If you disable
includeAutoGenerated: true, videos without manual captions will return an error row. -
No Multilingual Output — Can't extract English and Spanish in one run. Must run twice (once per language). Results go to the same dataset; use filters to separate.
-
oEmbed Metadata Limitations — Title, channel, and thumbnail come from YouTube's oEmbed API, not direct video pages. Occasionally missing or outdated. Disable with
includeMetadata: falseto speed up. -
Rate Limiting — YouTube and Apify Proxy both rate-limit. Very large batches (>10k) may hit limits. Recommended: split into 1k–2k batches if processing 100k+ videos.
-
No Video Download — This actor extracts transcripts only, not video audio or metadata like resolution, frame rate, or duration. Use YouTube-DL actors for that.
-
No Translation — Transcripts are in the video's original language. Can't translate on the fly. Use Google Translate API as a downstream step if needed.
-
Segment Duration Estimates — Segment duration is calculated from the next segment's start time. Last segment duration may be imprecise.
Changelog
v1.3.0 (Latest)
- Added: PDF transcript reports with timestamps, video metadata, and dataset download URLs
- Added: Unicode-capable embedded font for Latin, Cyrillic, and other DejaVu-supported scripts
- Improved: Output schema now exposes the PDF key-value store
v1.2.0
- Added: Support for YouTube Shorts URLs
- Improved: Metadata extraction now handles edge cases (private videos, deleted channels)
- Fixed: SRT timestamp formatting for videos >1 hour
- Positioning: README now focuses on API, AI/RAG, SRT/VTT, Markdown, and bulk dataset workflows
v1.1.5
- Added: Markdown output format with inline timestamps
- Added:
includeMetadatatoggle to skip oEmbed API calls for faster processing - Fixed: Language fallback now respects
includeAutoGeneratedflag - Fixed: Error handling for videos with no segments
v1.1.0
- Added: VTT subtitle format output
- Added: Automatic fallback to auto-generated captions
- Improved: Error messages now include video ID and language
- Changed: Default
maxItemsreduced to 10 for safer first runs
v1.0.5
- Fixed: Proxy configuration parsing for custom proxies
- Fixed: Timestamp precision for segments <1 second
- Improved: Logging now shows segment count per video
v1.0.0 (Initial Release)
- Bulk YouTube transcript extraction
- JSON and SRT output formats
- Language selection with fallback
- Video metadata (title, channel, thumbnail)
- Apify Residential Proxy integration
- PPE pricing per successful transcript extraction
Support & Documentation
- Apify Docs: https://docs.apify.com/
- YouTube Transcript API: https://github.com/jdepoix/youtube-transcript-api
- Report Issues: Use the Apify console "Issues" tab or contact support
- Feature Requests: Comment on the actor's discussion page or send feedback
Questions? Issues? Feedback? Post on the Apify actor discussion page or contact the developer directly.
Related Actors
- Article Extractor — Extract clean article text from any URL
- Website Content Crawler — Crawl websites and extract Markdown for RAG/LLMs
- RAG Web Browser — Search Google + extract as Markdown for AI agents
- Google SERP & Indexation Checker — Compare sitemap vs Google index
- Keyword Rank Tracker — Track keyword positions in Google daily
See all actors: apify.com/tugelbay