Google Index Checker API
Pricing
from $3.50 / 1,000 serp results
Google Index Checker API
Check Google indexation for a domain by comparing sitemap URLs against live Google site: search results. Find indexed, missing, and potentially deindexed pages. Guide: https://konabayev.com/tools/google-serp-checker/?utm_source=apify_info&utm_medium=referral&utm_campaign=google-serp-checker
Pricing
from $3.50 / 1,000 serp results
Rating
0.0
(0)
Developer
Tugelbay Konabayev
Maintained by CommunityActor stats
0
Bookmarked
30
Total users
7
Monthly active users
7 days ago
Last modified
Categories
Share
Google index checker for public sitemap diagnostics: compare sitemap URLs with observed Google site: results and export dated indexed/not-indexed candidates, counts, source URLs, and error states for technical SEO monitoring.
Check Google indexation without Search Console access — compare public sitemap URLs against live Google
site:search results. Built for SEO automation — schedule indexation checks, export missing URLs, and feed reports into Sheets, dashboards, webhooks, MCP tools, or your own API. Pay per use — see the live Pricing tab for the current event price and volume tiers.
For implementation notes, examples, and technical SEO workflows, see the Google SERP Checker guide on Konabayev.com.
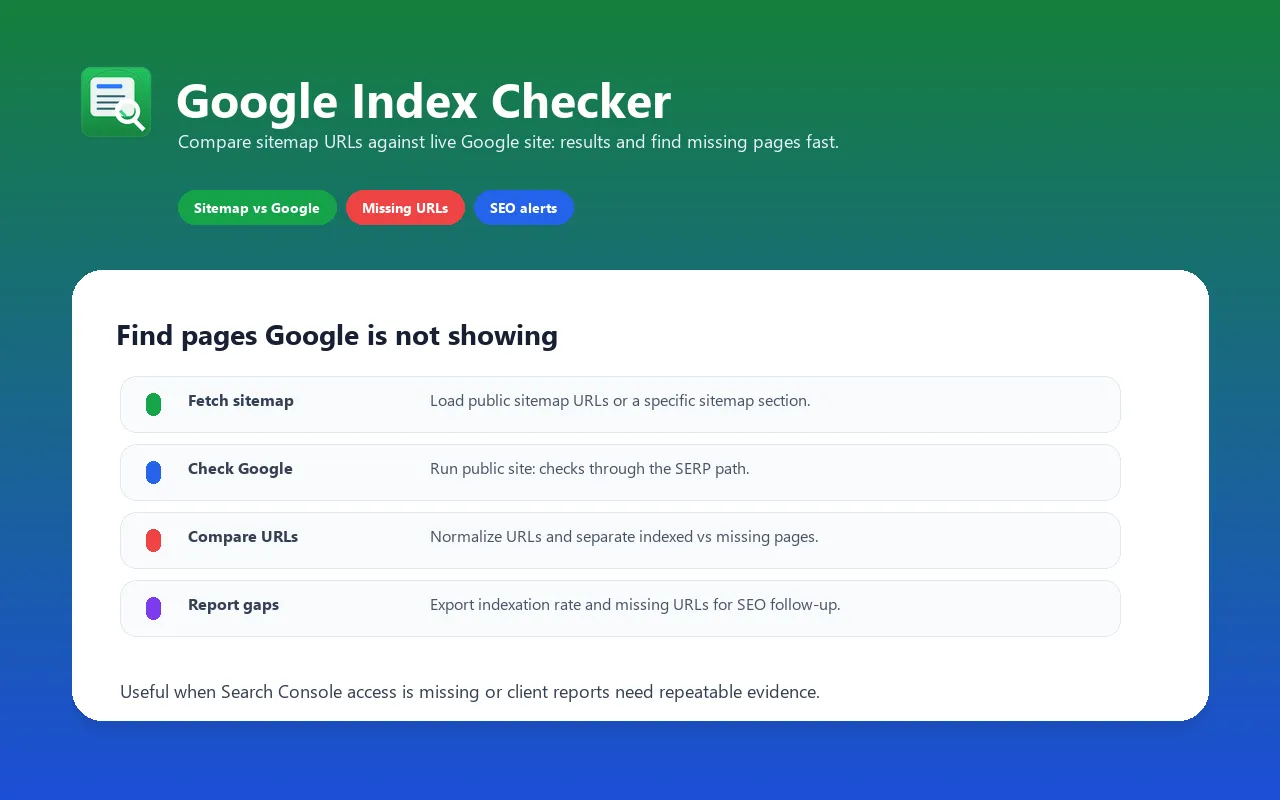

Check how many of your website's pages are visible in Google's public index. Google Index Checker fetches your sitemap, runs a Google site: search, normalizes URLs, and returns indexed pages, missing sitemap URLs, and an indexation rate you can monitor over time.
Perfect for SEO audits, content monitoring, indexation troubleshooting, technical SEO reporting, and automated indexation alerts.
Google Index Checker for Any Domain
Check your own domain, a client site, a competitor site, a blog section, or a subdomain. You do not need Google Search Console ownership because the actor uses publicly available sitemap and site: search data.
Sitemap vs Google Index Comparison Tool
Upload your sitemap URL and get a detailed report: indexed pages, missing pages, and indexation rate. Essential for technical SEO audits.
Bulk Google Index Checker
Use sitemap sections to check content groups such as /blog/, /products/, /docs/, or post sitemaps. Export the result as JSON, CSV, Excel, or Google Sheets for SEO reports.
What does Google Index Checker API do?
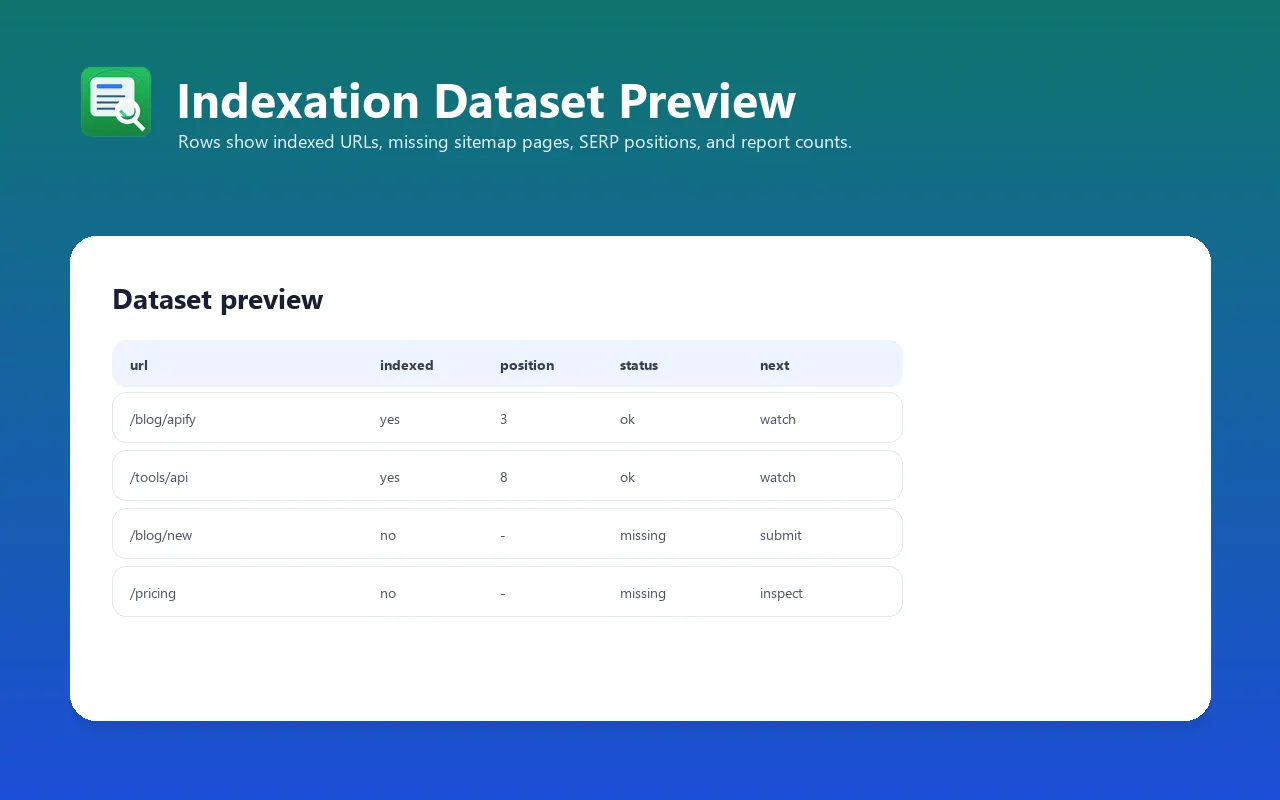
This actor fetches your website's sitemap, runs a site:domain Google search using Apify's SERP proxy, and compares the results to find which pages appear in Google results vs. which sitemap URLs were not found in the sampled results. It returns structured data including:
- Index rate — percentage of sitemap URLs currently indexed in Google
- Indexed pages — full list with SERP position and title metadata
- Not indexed pages — list of sitemap URLs Google hasn't indexed yet
- Counts — total sitemap pages, indexed count, not indexed count, date stamp
You provide a domain — the actor fetches the sitemap, queries Google, normalizes URLs, and produces an exportable indexation report. No manual site: searches, no spreadsheet joins.
Why use this Actor?
| Feature | Google Index Checker API | Google Search Console | Manual site: search | Screaming Frog |
|---|---|---|---|---|
| Automated | Yes — schedule daily/weekly | Manual export | Manual | Manual crawl |
| API/MCP ready | Yes — JSON output, Apify API | Limited API | No | No |
| Cost | Usage-based on Apify | Free | Free (tedious) | Paid desktop license |
| Sitemap comparison | Automatic | Manual cross-reference | No | Separate crawl needed |
| Missing sitemap URLs | Sitemap URLs missing from sampled site: results | Available only for verified properties | No | Requires crawl/API setup |
| Scheduling | Built-in (Apify scheduler) | No | No | No |
| Export formats | JSON, CSV, Excel, Google Sheets | CSV only | None | CSV, Excel |
| AI/LLM integration | MCP Server compatible | No | No | No |
| Setup time | 30 seconds | Verify ownership first | — | Install + configure |
Key advantage: Google Search Console remains the source of truth for properties you own. This actor is best when you need an API-friendly public check, competitor/client checks without property access, scheduled monitoring, or a quick sitemap-vs-site: comparison that exports exact missing sitemap URLs.
Features
- Automatic sitemap crawling — fetches and parses XML sitemaps, extracts all
<loc>URLs - Google
site:search — uses Apify's GOOGLE_SERP proxy group to reduce blocking risk - URL normalization — handles trailing slashes, www/non-www, case differences when comparing
- Indexed pages with metadata — returns SERP position and page title for each indexed URL
- Not-yet-indexed list — sitemap URLs not found in the sampled public
site:results - Index rate calculation — percentage metric for tracking progress over time
- Custom sitemap support — specify any sitemap URL (sitemap index, nested sitemaps, custom paths)
- Schedulable — run daily, weekly, or monthly via Apify scheduler for trend tracking
- Export anywhere — JSON, CSV, Excel, Google Sheets, webhook, or Apify API
- MCP compatible — works with Apify MCP Server for AI agent integration
- Lightweight — runs in ~2-10 seconds, uses minimal compute (256MB memory)
How to run an index check
- Start with one public sitemap and a bounded URL limit.
- Inspect dated rows, observed
site:results, missing candidates, and error/block states. - Validate important URLs in Google Search Console; schedule only the diagnostic comparison you understand.
Input examples
Check index rate for a domain (default sitemap)
Check with a custom sitemap URL
Check deeper Google results
Check a subdomain
Input parameters
| Parameter | Type | Default | Required | Description |
|---|---|---|---|---|
domain | String | — | Yes | Domain to check (without https://). Example: myblog.com |
sitemapUrl | String | https://{domain}/sitemap.xml | No | Full URL to your sitemap. Supports sitemap index files, nested sitemaps, and custom paths. |
maxResults | Integer | 20 | No | Maximum number of results to fetch from Google site: search (10–100). Higher = more indexed pages found, but slower. |
Output data fields and format
| Field | Type | Description |
|---|---|---|
date | String | Run date in ISO 8601 format (e.g., 2026-04-04) |
domain | String | The checked domain |
sitemapTotal | Integer | Total number of URLs found in the sitemap |
googleIndexed | Integer | Number of pages found indexed in Google |
indexRate | String | Percentage of sitemap pages indexed (e.g., 75%) |
indexedPages | Array | List of indexed pages: [{pos, title, url}] |
notYetIndexed | Array | List of sitemap URLs not found in Google index |
notIndexedCount | Integer | Count of not-yet-indexed pages |
Example output
Integrations
Python
JavaScript / Node.js
LangChain / AI Agents
MCP Server (AI Agents)
This actor is compatible with Apify MCP Server, enabling AI agents (Claude, ChatGPT, custom LLM apps) to check Google indexation programmatically.
Export options
- JSON — default, structured output via Apify API
- CSV — export from dataset, compatible with Excel and Google Sheets
- Excel (.xlsx) — direct download from Apify Console
- Google Sheets — use Apify's Google Sheets integration
- Webhook — trigger on run completion for automated workflows
- API — fetch results programmatically from any language
Use cases
-
Weekly indexation audit — schedule the actor weekly to track how your index rate changes over time. Catch deindexing events early.
-
New content monitoring — after publishing new blog posts, run the actor to verify Google has indexed them. Identify posts stuck in the "not indexed" state.
-
Site migration validation — after migrating to a new domain or URL structure, compare old vs. new indexation rates. Ensure redirects are working and new URLs are being picked up.
-
Technical SEO reporting — include indexation data in client SEO reports. Show exact index rates with evidence, not estimates.
-
Competitor indexation analysis — check how many pages a competitor has indexed. Understand their content footprint and publishing velocity.
-
Deindexation alerts — schedule daily runs and set up webhooks. If the index rate drops below a threshold, get notified immediately.
-
Content pruning decisions — identify pages in your sitemap that Google refuses to index. These may be thin content, duplicates, or low-quality pages worth removing or improving.
-
Multi-site monitoring — run the actor for multiple domains (portfolio sites, client sites) and aggregate results in a dashboard.
-
SEO agency workflows — automate indexation checks across all client sites. Export to Google Sheets for client-facing reports.
-
AI-powered SEO pipelines — feed indexation data into LLMs via MCP Server for automated SEO analysis and recommendations.
Cost estimation
This actor uses Pay-Per-Event (PPE) pricing. You pay only for what you use.
| What counts as an event | Store pricing signal |
|---|---|
| One domain indexation check | One primary dataset event, currently tiered from about $0.0035-$0.005 per check plus a tiny actor-start event |
Example costs:
| Scenario | Events | Estimated cost |
|---|---|---|
| Check 1 domain, once | 1 | Less than $0.01 |
| Daily check, 1 domain, 30 days | 30 | ~$0.11-$0.15 |
| Weekly check, 10 domains, 1 month | 40 | ~$0.14-$0.20 |
| Daily check, 50 domains, 1 month | 1,500 | ~$5.25-$7.50 |
Comparison with alternatives:
- Google Search Console: free and authoritative for properties you own, but not built as a public competitor/client index checker.
- Screaming Frog: paid desktop crawler with advanced audit features and Search Console integrations.
- Bulk index checking services: useful for high-volume URL monitoring, but often subscription or credit-pack based.
- This actor: usage-based Apify actor for sitemap-vs-
site:checks, exports, schedules, API calls, webhooks, and MCP workflows.
FAQ
Is this a full Google SERP scraper?
No. This actor is focused on indexation checks with site:domain queries and sitemap comparison. If you need full SERP results for arbitrary keywords, ads, People Also Ask, or localization, use a dedicated Google SERP scraper or Keyword Rank Tracker.
How accurate is this compared with Google Search Console?
Google Search Console is more authoritative for sites you own. This actor uses public Google site: results, so it is better for lightweight monitoring, external domains, trend tracking, and surfacing likely missing URLs. Treat it as an automation-friendly public signal, not a replacement for verified Search Console data.
How does the actor find indexed pages?
It runs a site:yourdomain.com search on Google using Apify's SERP proxy group. This returns the same results you'd see by typing site:yourdomain.com into Google — but automated, structured, and exportable.
Why doesn't the index count match Google Search Console?
Google's site: search is an approximation — it typically returns up to 100 results per query. Google Search Console has access to Google's internal index data, which is more comprehensive. This actor is best for relative tracking (trends over time) and identifying specific non-indexed URLs, rather than exact total counts.
Can I check more than 100 pages?
The maxResults parameter goes up to 100, which is the maximum Google returns for a single site: query. For sites with thousands of pages, focus on specific sitemap segments (e.g., /blog/sitemap.xml or /products/sitemap.xml) for more targeted results.
What sitemap formats are supported?
The actor parses standard XML sitemaps with <loc> tags. It supports sitemap index files, individual sitemaps, and custom sitemap paths. It does not currently support RSS/Atom feeds or HTML sitemaps.
How often should I run the indexation check?
- New sites / active publishing: daily or every 2-3 days
- Established sites: weekly
- Stable sites: monthly
- After migrations: daily for 2-4 weeks
Can I use this for competitor analysis?
Yes. Provide any domain — you don't need to own it. The actor will fetch the public sitemap and check indexation. Note that some sites block sitemap access, in which case you'll get 0 sitemap URLs but still see indexed pages from the site: search.
Does this affect my Google Search Console data?
No. The actor uses Google's public search interface via proxy. It doesn't interact with Search Console, doesn't require site verification, and doesn't affect your site's standing with Google.
Can I track indexation over time?
Yes. Schedule the actor to run on a recurring basis (daily, weekly, monthly) using Apify's built-in scheduler. Each run produces a dated dataset entry. You can export historical data to track trends, build charts, or feed into dashboards.
Is this the same as a rank tracker?
No. This actor checks indexation (is your page in Google's index at all?). For ranking positions (where does your page rank for specific keywords?), use Keyword Rank Tracker.
Troubleshooting
"Could not fetch sitemap" warning
Cause: The sitemap URL is incorrect, the server blocks automated requests, or the sitemap doesn't exist at the default path.
Fix: Provide the exact sitemap URL using the sitemapUrl parameter. Check that the sitemap is accessible by visiting it in a browser. Common paths: /sitemap.xml, /sitemap_index.xml, /sitemap-0.xml, /post-sitemap.xml.
Index rate shows 0% but pages are definitely indexed
Cause: The site: search may return 0 results if the domain has very few indexed pages, or if Google's proxy is temporarily blocked.
Fix: Try running the actor again — transient proxy issues resolve on retry. If the domain is very new (< 1 week), Google may not have indexed any pages yet.
Sitemap has URLs but none match indexed pages
Cause: URL normalization mismatch. The sitemap may list https://www.domain.com/page while Google indexes https://domain.com/page (or vice versa).
Fix: Ensure your sitemap URLs match your canonical URLs. The actor normalizes trailing slashes and case, but www vs non-www mismatches from different schemes can cause false negatives.
Run times out
Cause: Very large sitemaps (1000+ URLs) combined with slow sitemap servers.
Fix: Use a specific sitemap section instead of the sitemap index. For example, use /blog-sitemap.xml instead of /sitemap_index.xml to check a subset.
Results seem incomplete (fewer than expected)
Cause: Google's site: search returns a maximum of ~100 results regardless of how many pages are actually indexed.
Fix: This is a Google limitation, not an actor bug. For comprehensive indexation data, supplement with Google Search Console's Coverage report. This actor excels at identifying specific non-indexed URLs and tracking trends.
Google index checker comparison
| Route | Best for | Trade-off |
|---|---|---|
| This Actor | Repeatable sitemap-vs-site: diagnostics in datasets, schedules, API, and reports | site: results are incomplete estimates |
| Google Search Console | Authoritative property-level indexing reports for verified owners | Requires verified property access |
Manual site: checks | One-off inspection | No reliable bulk comparison or dated dataset |
Use this Actor to find candidates for investigation, not to claim an exact indexed-page count.
Validation evidence and Google guidance (2026-07-14)
Validation on 2026-07-14 preserves the diagnostic boundary:
- Google's official
site:operator documentation states that results do not necessarily include every indexed URL and are relatively unordered. - Google's policy on machine-generated traffic remains authoritative; checks must stay bounded and respect blocks/rate limits.
- Google's current Terms of Service also apply to use of Google surfaces.
- Results retain source sitemap URLs, observed URL/status fields, and a run
datefor repeatable comparisons. - Strict Actor QA validates schemas, metadata, links, Docker configuration, and PPE declarations before release.
This evidence does not replace Search Console or guarantee indexation, rankings, traffic, or AI citations.
Support
Send the run ID, public sitemap/domain, bounded input, expected URL, observed row, and visible error. Do not send Search Console credentials or private sitemaps.
Limitations
- Maximum 100 results per query — Google limits
site:searches to ~100 results. Sites with 1000+ pages won't show all indexed pages. - Approximation, not exact count —
site:results are Google's estimate. Use Google Search Console for authoritative total counts. - Sitemap required for comparison — without a sitemap, the actor only returns indexed pages found via
site:search (no "not indexed" list). - No JavaScript rendering — the actor fetches the sitemap via HTTP. If the sitemap is generated client-side (rare), it won't be parsed.
- English-language SERP — results are fetched with
hl=en&gl=us. Localized results may differ. - Rate limited by Google — running too frequently for the same domain may trigger temporary blocks. Space runs at least 1 hour apart.
Changelog
v4.0 (2026-04-04)
- Fixed
Actor.log→console.logfor Apify platform compatibility - Pinned cheerio to
1.0.0-rc.12for stable HTML parsing - Improved error handling and exit codes
v3.0 (2026-03-30)
- Added URL normalization (trailing slash, case insensitive)
- Improved sitemap parsing with regex extraction
v1.0 (2026-03-29)
- Initial release
- Sitemap fetching with automatic URL extraction
- Google
site:search via SERP proxy - Indexed vs. not-indexed comparison
- JSON/CSV export support
Related Actors
- Keyword Rank Tracker — Track keyword positions in Google daily
- Website Tech Stack Detector — Identify 80+ technologies on any website
- Google Maps Lead Extractor — Extract business leads with emails from Google Maps
- RAG Web Browser — Search Google + extract as Markdown for AI agents
- Article Extractor — Extract clean article text from any URL
See all actors: apify.com/tugelbay