Douyin 抖音 Transcripts Scraper - 50+ Languages, .srt + MP4
Pricing
from $0.039 / chinese transcript per minute
Douyin 抖音 Transcripts Scraper - 50+ Languages, .srt + MP4
Extract timestamped transcripts and .srt 字幕 from any Douyin (抖音) video. Mandarin speech-to-text plus translation into 50 languages. Optionally save the source MP4 and cover image to your key-value store at no extra cost. 60+ metadata fields. Per-minute pricing, free tier.
Pricing
from $0.039 / chinese transcript per minute
Rating
0.0
(0)
Developer
Zen Studio
Maintained by CommunityActor stats
4
Bookmarked
63
Total users
15
Monthly active users
2 days ago
Last modified
Categories
Share
Douyin Transcripts Scraper | 抖音 Subtitles & Translations in 50+ Languages (2026)
Timestamped transcripts & .srt subtitles for any 抖音 video, any length. Mandarin → 50 languages · creator + post metadata · no duration caps · frontier AI quality.
| Zen Studio · Chinese-platform suite • RedNote (小红书), Douyin (抖音), Xigua (西瓜视频) | |||
|
➤ You are here |
Keyword + filters, 60+ fields |
Followers, posts & hashtags |
Metadata + MP4 downloads |
Copy to your AI assistant
Key Features
- Frontier-model transcription quality: best-in-class Mandarin speech-to-text paired with state-of-the-art LLM translation. Two-tier translation pipeline self-escalates to a stronger model when needed for line-aligned accuracy.
- 51 languages: 中文 (zh, no translation) plus 50 translation targets covering ~95% of global speakers. Top picks first (English, Spanish, Hindi, Arabic, Portuguese, Russian, Japanese, German, French, Korean, …) then the long tail (Bulgarian, Catalan, Czech, Hebrew, Swedish, Tamil, …). Full table below.
- Timestamped per-cue segments: every line of the transcript carries
start/endfloats so you can sync to player timelines, build interactive transcripts, or edit clips around specific phrases. - Optional .srt subtitle export: flip one switch and get a SubRip (
.srt) subtitle file ready to upload to YouTube, Instagram, TikTok, Premiere, CapCut, Final Cut, DaVinci Resolve. Pay only when you ask for it. - Bonus: keep the MP4 + cover, free: flip
shouldDownloadVideosand the original MP4 lands in your key-value store alongside the transcript. The actor already streams the video to extract audio, so saving a copy costs nothing extra. Same toggle for cover images. No need to also run the Douyin Video Scraper. - Full creator + post metadata: 60+ fields per video: author profile, statistics, hashtags, music, chapters, video tags, share URL, cover image, and more. Same shape as the Douyin Video Scraper, with the transcript layered on top.
- Free tier: 5 minutes of audio lifetime, no credit card. Long videos get a partial transcript so you can preview the output before committing.
- Robust URL parsing: paste a desktop URL, a
v.douyin.com/...short link, a?modal_id=...web-feed URL, the entire mobile share blob (复制此链接 ...), or just a numeric aweme ID. All work.
How to Get 抖音 Video Transcripts
Basic: original Chinese transcript
English subtitles for a Douyin video
Bulk translation: German subtitles for a batch
Archive .srt files across many runs
The default key-value store is wiped 7 days after a run. Use srtKvStoreName to drop your subtitle files into a named store that lives forever and accumulates across runs.
Input Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
videoUrls | array of strings | required | One or more 抖音 video URLs. Most URL formats accepted (see below). Max 5 per run. |
targetLanguage | string (enum) | "zh" | Output language. zh returns the original Chinese transcript with no translation cost. Any other code triggers an LLM translation pass. |
outputSrt | boolean | false | When true, also generates a SubRip (.srt) subtitle file and includes srtUrl on the row. |
srtKvStoreName | string | "" | Optional named key-value store for .srt files. Lowercase letters, digits, and dashes only. Empty = the run's default store. |
Supported URL formats
All of these resolve to the same video:
https://www.douyin.com/video/7534679152504376595: desktop URLhttps://www.iesdouyin.com/share/video/7534679152504376595/: share URLhttps://v.douyin.com/<short>/: mobile app share linkhttps://www.douyin.com/jingxuan/sports?modal_id=7534679152504376595: web-feed modalhttps://www.douyin.com/note/7534679152504376595: image-post URL7534679152504376595: bare numeric aweme ID8.79 0bH:/ # 看看这个 https://v.douyin.com/abc/ 复制此链接 ...: full mobile share blob (URL extracted)
Supported languages (targetLanguage)
zh returns the original Mandarin transcript with no translation pass (lowest cost). Any other code triggers an LLM translation. The list is curated to languages where the model produces natural, conversational output: top demand first, then alphabetical.
| Code | Language | Code | Language |
|---|---|---|---|
zh | 中文 / Chinese (no translation) | en | English |
es | Español / Spanish | hi | हिन्दी / Hindi |
ar | العربية / Arabic | pt | Português / Portuguese |
ru | Русский / Russian | ja | 日本語 / Japanese |
de | Deutsch / German | fr | Français / French |
ko | 한국어 / Korean | id | Bahasa Indonesia / Indonesian |
tr | Türkçe / Turkish | it | Italiano / Italian |
vi | Tiếng Việt / Vietnamese | th | ภาษาไทย / Thai |
pl | Polski / Polish | nl | Nederlands / Dutch |
bn | বাংলা / Bengali | ur | اردو / Urdu |
fa | فارسی / Persian | uk | Українська / Ukrainian |
ms | Bahasa Melayu / Malay | tl | Filipino / Filipino (Tagalog) |
bg | Български / Bulgarian | ca | Català / Catalan |
cs | Čeština / Czech | da | Dansk / Danish |
el | Ελληνικά / Greek | et | Eesti / Estonian |
fi | Suomi / Finnish | gu | ગુજરાતી / Gujarati |
he | עברית / Hebrew | hr | Hrvatski / Croatian |
hu | Magyar / Hungarian | is | Íslenska / Icelandic |
kn | ಕನ್ನಡ / Kannada | lt | Lietuvių / Lithuanian |
lv | Latviešu / Latvian | ml | മലയാളം / Malayalam |
mr | मराठी / Marathi | nb | Norsk bokmål / Norwegian (Bokmål) |
pa | ਪੰਜਾਬੀ / Punjabi | ro | Română / Romanian |
sk | Slovenčina / Slovak | sl | Slovenščina / Slovenian |
sr | Српски / Serbian | sv | Svenska / Swedish |
sw | Kiswahili / Swahili | ta | தமிழ் / Tamil |
te | తెలుగు / Telugu |
What Data Can You Extract from 抖音 Videos?
Every dataset row pairs the transcript and subtitle data with the same rich metadata shape used by the Douyin Video Scraper. 60+ top-level fields per video.
Transcript-specific fields
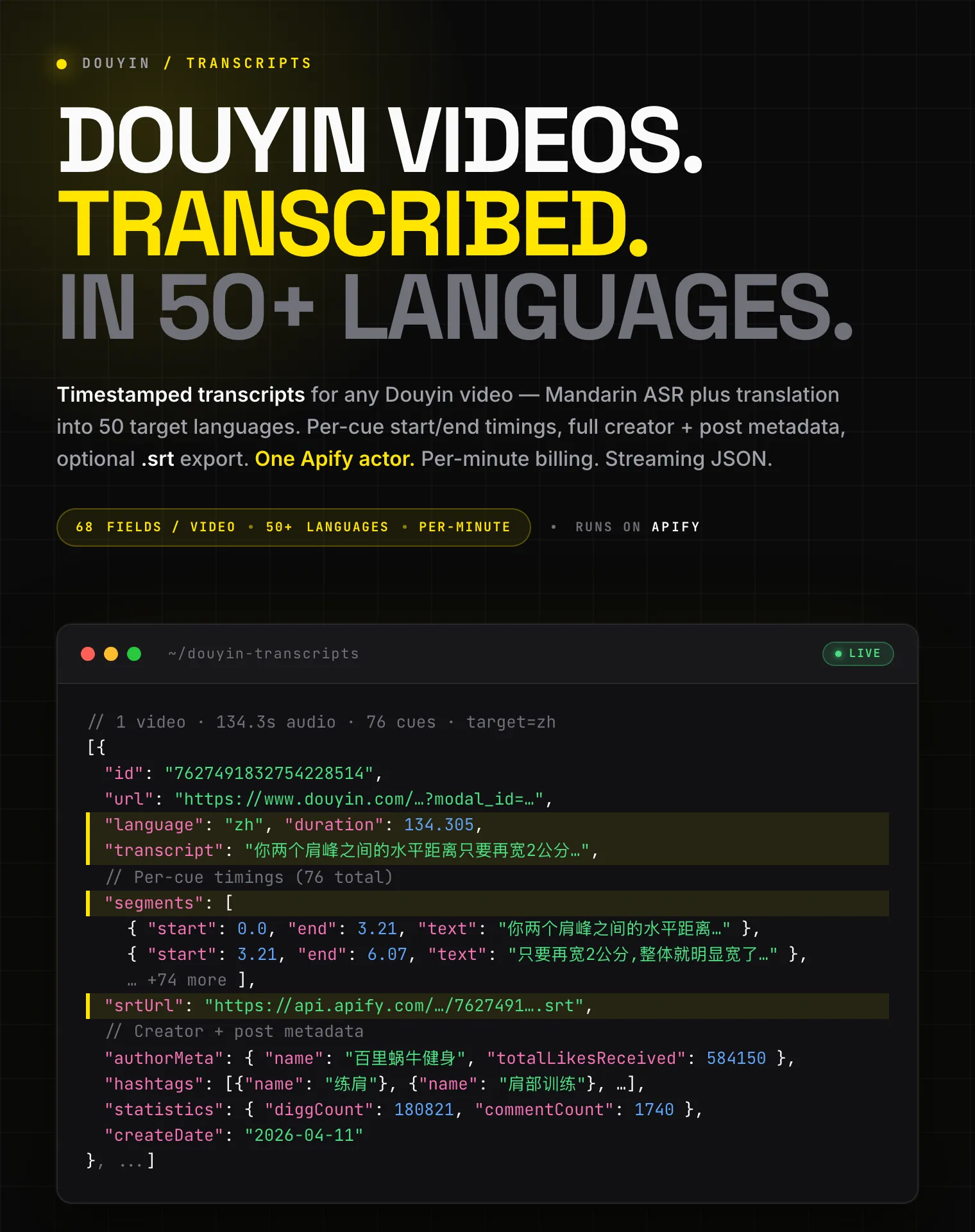
transcript: full plain-text transcript in the chosen languagesegments: array of{start, end, text}cues with float second timinglanguage: output language code (zh,en,de, ...)srtUrl: public link to the.srtfile in your key-value store (only whenoutputSrt: true)duration: total video duration in seconds (float)truncatedFromSeconds: set on free-tier rows where the audio was truncated to fit the quotamp4Url: direct link to the saved MP4 in your key-value store. Populated whenshouldDownloadVideos: true,nullotherwise. Same URL asvideoFile.kvUrl, lifted to the top level so it's clickable in the Apify Console and easy to pipe into a download script.coverImageUrl: direct link to the saved cover JPEG. Populated whenshouldDownloadCovers: true,nullotherwise. Lifted fromcoverFile.kvUrl.videoFile: full metadata block for the saved MP4 (kvUrl,kvStoreKey,kvStoreId,sizeBytes,mimeType,sourceUrl) whenshouldDownloadVideos: true, elsenull. Use this when you need the file size or the original source CDN URL alongside the saved location.coverFile: same shape asvideoFilefor the cover JPEG.nullwhen the toggle is off.
Metadata fields
- Identity & URLs:
id,groupId,url,shareUrl,videoUrl,audioUrl,inputUrl - Type & flags:
type,awemeType,mediaType,horizontalType, plus 14 boolean flags (isPinned,isAd,isPgc,isStory,isVr, ...) - Caption variants:
text(full description),caption,itemTitle,previewTitle,descLanguage - Time & locality:
createTime,createDate,region,city,cityCode - Nested rich blocks:
authorMeta: name, sec_uid, verified status, total likes received, avatars (5 sizes), signature, region, demographics (gender/language/userAge/birthday/constellation), commerce flags, school, cross-platform IDs (42 fields)videoMeta: cover image, dimensions, ratio, bit-rate variants, watermark flag, CDN expirymusicMeta: track title, author, original-sound flag, play URL, cover artstatistics: diggCount, commentCount, shareCount, collectCount, downloadCount, ...permissions: duet / stitch / share / comment / download flagscommerce,share,interaction,xiguaCrossPost,aiMetadata,risk
- Repeated sections:
hashtags,mentions,videoTags,chapters,images,series,location
Output Example
Advanced Usage
Custom subtitle archive across multiple runs
The default key-value store on every run gets garbage-collected after 7 days. Drop your .srt files into a named persistent store instead:
Browse and re-download files at any time at console.apify.com/storage/key-value.
Translating one video into multiple languages
Run the actor once per target language; each run charges only for that language. The transcript stage is the expensive part: translation alone is the smaller share of the per-minute price.
Bulk transcription from a profile or hashtag scrape
Pipe video IDs from a sibling actor straight into videoUrls. Two-step pattern:
- Run Douyin Profile Scraper to pull a creator's recent posts.
- Feed the
idfield from each post into this actor'svideoUrls.
This gives you a creator's complete searchable transcript library in any language.
Want the MP4 video file too?
Just flip the toggle: this actor already downloads the video to extract audio, so saving a permanent copy is free.
The MP4 lands in your key-value store at <aweme_id>.mp4 and the cover at <aweme_id>.jpg. The dataset row carries flat top-level mp4Url and coverImageUrl strings so you can grab the file URL directly: no nested object lookup. The full videoFile / coverFile blocks are also there if you need the byte size or the original source CDN URL.
Pricing is unchanged: only the per-minute transcription rate applies. The MP4 and cover come along for free because the bandwidth is already paid for by the transcription work.
If you only want MP4s (no transcripts) the Douyin Video Scraper is the right tool: it skips the transcription step entirely and bills $4.99 / 1,000 MP4 downloads with no per-minute charge. Use it for bulk archiving; use this actor when you want transcripts and would also like a copy of the video.
Failed videos still emit a row
Every input video produces exactly one dataset row. If a video can't be loaded or transcribed (private, deleted, no audio track, etc.), the row carries a clear errMsg field:
Pricing: Pay Per Event (PPE)
Per audio-minute billing. Round-up to whole minutes: a 0:50 clip is billed as 1 minute, a 19:20 clip as 20 minutes.
| Event | Per call |
|---|---|
Original Chinese transcript per minute (zh) | $0.04 |
Translated transcript per minute (any non-zh language) | $0.06 |
.srt subtitle file export (when outputSrt: true) | $0.02 |
The translated rate replaces the Chinese rate; it does not stack on top of it.
Cost Examples
| Video | Language | SRT? | Cost |
|---|---|---|---|
| 30-second clip | Chinese | No | $0.04 |
| 90-second clip | English | No | $0.12 |
| 2-minute clip | German | Yes | $0.14 |
| 10-minute video | Japanese | Yes | $0.62 |
Free Tier
5 audio-minutes lifetime per non-paying user, no credit card required.
For videos longer than your remaining quota, the actor processes the first N minutes that fit, ships a partial transcript, and stamps the row with an upgrade message + a truncatedFromSeconds field. Quota is only debited on successful processing: failed videos don't burn your free minutes.
Cost Optimization Tips
- Stick with
targetLanguage: "zh"if your downstream pipeline already translates. The original Mandarin transcript is the cheapest and most accurate output. - Skip
outputSrtfor use cases that only need the JSON segments.srtUrlis for direct video-editor / player ingestion. - Batch 50–100 video URLs into a single run to amortize the actor-start fee.
FAQ
What is Douyin (抖音)? Douyin is ByteDance's Chinese short-video platform, the domestic counterpart of TikTok: same company and format, separate app and catalogue. Its videos are spoken in Mandarin, which is what this actor transcribes and translates.
How accurate is the Chinese speech recognition? We use a frontier-model Mandarin ASR engine tuned for short-form social video. Quality is comparable to professional human transcripts on clean audio; degrades gracefully on heavy background music or thick regional accents.
How accurate are the translations? Two-tier LLM translation pipeline: a fast model handles the bulk, with automatic escalation to a stronger model when line-count alignment fails. Each transcript line maps 1:1 to a translated line so timestamps stay accurate.
Can I get word-level timestamps?
Not currently: segments are sentence- or clause-level. Each segment carries float-second start / end precision, which is enough for subtitle display and timeline navigation.
What's the difference between this and Douyin Video Scraper?
Video Scraper is for bulk MP4 / cover / slideshow archiving without transcription, billed at $4.99 / 1,000 MP4 downloads with no per-minute charge. This actor adds the spoken-content transcript, segment-level timing, optional .srt subtitle file, and translation into 50 target languages, and now also lets you save the original MP4 + cover to your key-value store as a free bonus (the bytes are already on disk for audio extraction). Pick this one when you want transcripts and would also like the video; pick Video Scraper when you only want the video.
Can I scrape transcripts at scale? Yes. Pass up to 5 URLs per run; the actor processes them concurrently. For larger batches, run multiple jobs in parallel: each is fully isolated.
Does it work with private or age-gated videos?
No. The actor extracts publicly available data only. Private videos return an errMsg: "Video not available" row.
What happens with videos that have no audio?
The actor detects "no audio track" cleanly and returns an empty transcript with errMsg: "Video has no audio track". You're not charged the transcription fee in this case.
Can the .srt subtitle file be uploaded to YouTube / Instagram / CapCut?
Yes. The output is standard SubRip format: directly compatible with YouTube subtitle uploads, Instagram closed captions, CapCut auto-import, Premiere Pro, Final Cut Pro, DaVinci Resolve, and any other video editor that supports .srt.
How do I keep .srt files across runs?
Set srtKvStoreName to any name you want (e.g. "douyin-subtitles"). Files land in a named, persistent key-value store you can browse at console.apify.com/storage/key-value. The default per-run store is wiped after 7 days; named stores live forever.
What's the free tier? 5 audio-minutes lifetime per user. For longer videos, the actor returns a partial transcript covering the first minutes that fit your quota, plus an upgrade prompt. Quota debits only on successful runs.
Does the per-minute rate include translation? Yes. The translated per-minute rate ($0.06) covers both the original transcription and the translation step; it replaces the Chinese rate and does not stack on top of it.
Do I need a Douyin account or cookies? No. Paste video URLs or IDs and run; no account, cookie export, or QR login is involved.
How do I export the transcripts?
The dataset downloads as JSON, CSV, Excel, XML, or HTML from the run's Storage tab, or via the Apify API. .srt subtitle files and any saved MP4s sit in your key-value store with direct URLs.
How do I find videos to transcribe at scale?
Chain the suite: Douyin Search Scraper finds videos by keyword and Douyin Profile Scraper lists a creator's full catalogue; feed the resulting url or id values straight into videoUrls here.
Is it legal to transcribe Douyin videos? The actor transcribes publicly available videos only, nothing behind a login. You are responsible for complying with Douyin's terms of service, the creator's copyright, and applicable data protection law (GDPR, CCPA, PIPL); attribution is recommended when republishing transcripts or subtitles.
More Zen Studio scrapers for Chinese platforms
🎬 Short-video & social
 Douyin 抖音
Douyin 抖音
 RedNote 小红书
RedNote 小红书
 Xigua 西瓜视频
Xigua 西瓜视频
 Bilibili 哔哩哔哩
Bilibili 哔哩哔哩
🛒 E-commerce
 Shopee
Shopee
 Taobao 淘宝
Taobao 淘宝
 JD.com 京东
JD.com 京东
 1688 阿里巴巴
1688 阿里巴巴
 Goofish 闲鱼
Goofish 闲鱼
 Coupang 쿠팡
Coupang 쿠팡
🏠 Real estate & autos
 Anjuke 安居客
Anjuke 安居客
 58.com 58同城
58.com 58同城
 Autohome 汽车之家
Autohome 汽车之家
Support
- Bugs: Issues tab
- Features: Issues tab
Legal Compliance
Extracts publicly available data from public 抖音 video pages. Users are responsible for complying with Douyin's terms of service, copyright law, and applicable data-protection regulations (GDPR, CCPA, PIPL). Downstream use of transcripts and subtitles must respect the original creator's rights; attribution is recommended when republishing.
Timestamped Mandarin transcripts and translated subtitles for any 抖音 (Douyin) video. 50+ languages, .srt export, full creator metadata. Frontier-model AI quality, per-minute pricing.