Instagram Post Scraper
Pricing
from $1.00 / 1,000 posts
Instagram Post Scraper
Scrape Instagram posts. Just add one or more Instagram usernames and get your data in seconds including caption, metrics, images, mentions, coauthors, recent comments, sponsored status, video duration, views. Export scraped data, schedule scraper via API, integrate with other tools or AI workflows.
Pricing
from $1.00 / 1,000 posts
Rating
4.5
(126)
Developer
Apify
Maintained by ApifyActor stats
1.1K
Bookmarked
113K
Total users
10K
Monthly active users
19 hours
Issues response
2 days ago
Last modified
Categories
Share
What can Instagram Post Scraper do?
Our Instagram Post Scraper allows you to scrape data from public Instagram posts beyond what the Instagram API allows. Just add a username, profile URL or post URL, and you're ready to:
📸 Extract Instagram post data at scale from any public profile
📝 Get full post details including captions, mentions, images, tagged users, and engagement metrics (number of likes, comments, replies, video views)
⚡ Scrape posts, carousels, and reels/videos with no limitations on requests
💬 Collect a few latest comments with timestamps and likes
⬇️ Download Instagram posts data in JSON, CSV, Excel, or other formats
🦾 Export posts data via SDKs (Python & Node.js), use API Endpoints & webhooks
🤳 Explore our other social media scrapers
With the Instagram data you’ve scraped, you can monitor the content put out by your favorite creators or your competitors. Other options include seeing what’s trending on the platform through analyzing engagement, posting frequency, or even how well each post type is doing.
What data can I extract with Instagram Post Scraper?
Using this Instagram Post API, you will be able to extract the following data from posts:
| 🔗 Post URL | 👤 Post author | 👥 Post coauthor | 🚸 Child posts | 🗒️ Caption |
| ❤️ Number of likes | 🗨️ First and latest comments | 🔢 Number of comments | #️⃣ Post hashtags if any | 🔖 Tagged users |
| 🎥 Type of post | 📅 Date posted | ➰ Image URLs | ⌨️ Alt text | 🖼️ Image dimensions |
| 🆔 Instagram ID | 🗨️ Post mentions if any | 📽️ Video duration | 🔄 Video play count | 📹 Video URL |
| 📌 Is it a pinned post? | 💰 Is it a sponsored post? | 💬 Are comments disabled? | 💵 Is it a paid partnership? | 🏦 Post owner information |
If you need to scrape all comments and replies from each post, try Instagram Comments Scraper. If you want to scrape both posts and comments in one go, try out our Instagram Comments and Posts Export tool, instead. If you only need profile info (number of of followers, bio, etc.), go for Instagram Profile Scraper.
How to extract posts from Instagram profiles?
Instagram Post Scraper is designed with users in mind, even those who have never extracted data from the web before. Using it takes just a few steps.
- Create a free Apify account using your email.
- Open Instagram Post Scraper.
- Add one or more Instagram usernames, profile URLs, or specific post URLs.
- Click the “Start” button and wait for the data to be extracted.
- Download your data in JSON, XML, CSV, Excel, or HTML.
For more details, check out our tutorial on how to scrape data from Instagram, full of tips and tricks.
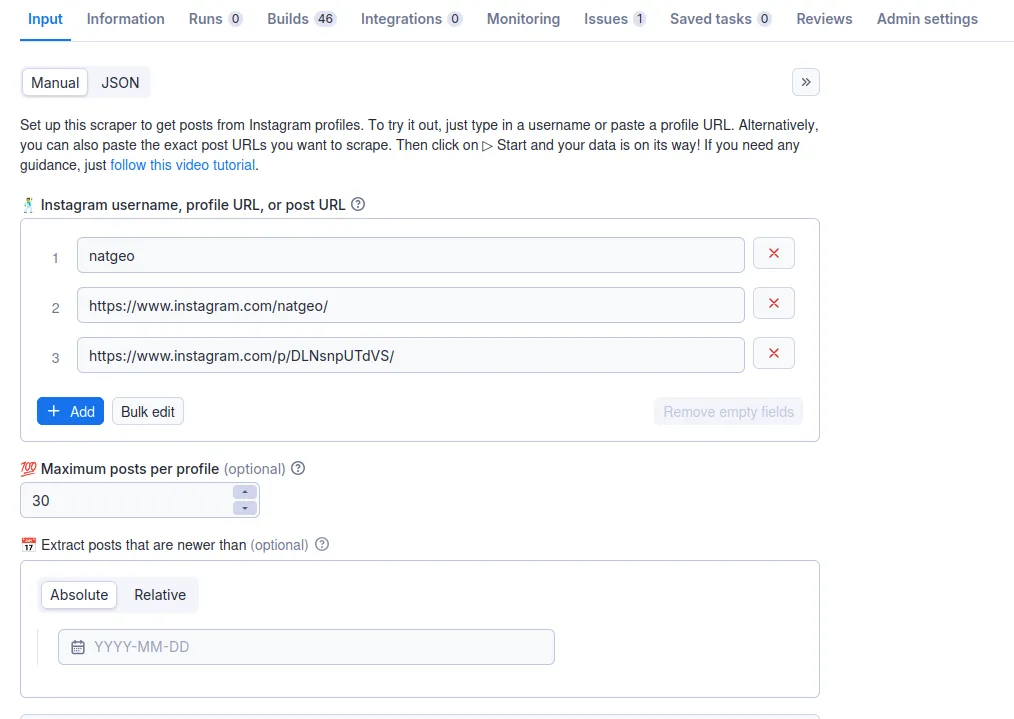
⬇️ Input
Enter the Instagram username or profile URL that you want to get data on, then enter the number of posts you want returned from the profile. URLs can be entered one by one, or you can use the Bulk edit section to add a prepared list. You can also make sure you only get newer posts by setting a cutoff date.
If you want to scrape specific post URLs, you can do so one by one or bulk edit entries. In that case, you can’t set maximum posts or a date filter.
⬆️ Output
The results will be wrapped into a dataset which you can find in the Storage tab. Here's an excerpt from the dataset you'd get if you apply the input parameters above:
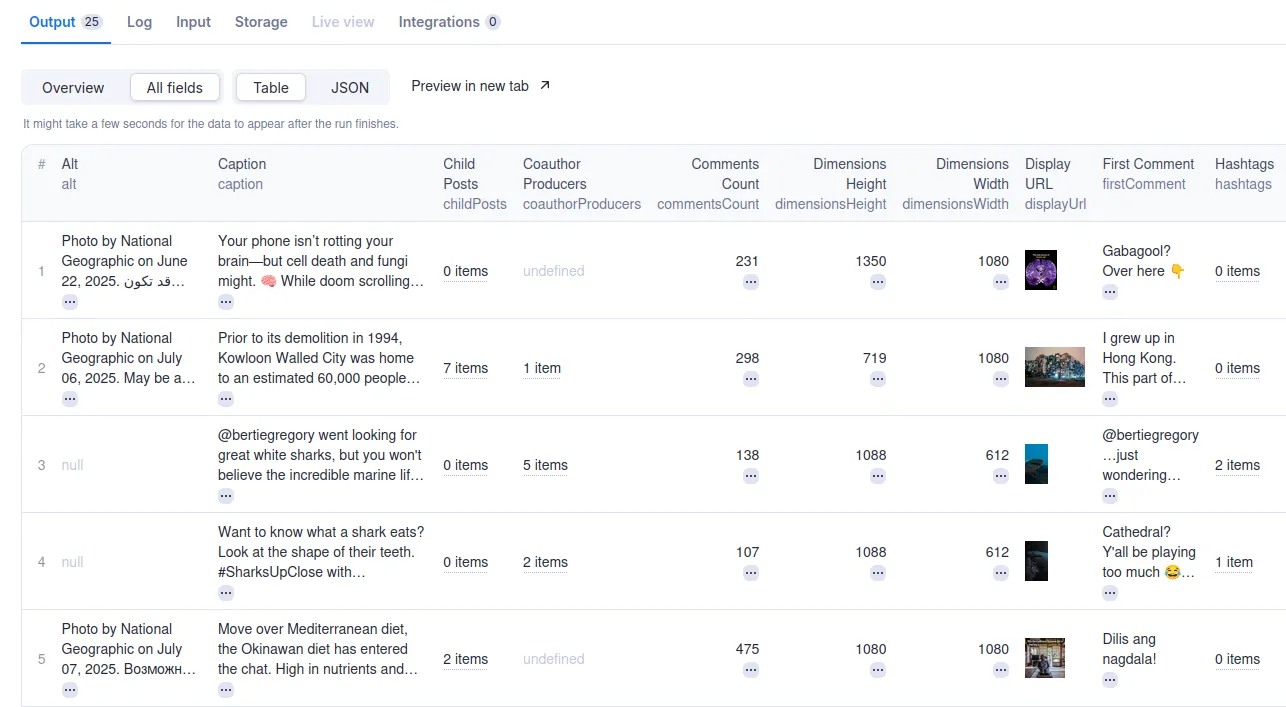
You can also export this data in most common formats, such as JSON, XML, CSV, and Excel. Here’s a sample of that output in JSON:
📝 Extracted Instagram Post data sample
How much will scraping Instagram posts cost you?
Instagram Posts Scraper works on our pay-per-event (PPE) model, meaning you’re charged for each result that you receive. On our Free plan, the price is $2.70 per 1,000 results, meaning each result is $0.0027, and you can get nearly 2,000 results for free.
On our paid plans, you will have a discount added depending on your Tier. For example, on the Starter plan, it costs just $2.30 per 1,000 results. Check out the pricing tab for the specifics for this Actor.
Want to scrape more Instagram data?
If you want Instagram data that this Actor can’t provide, or only need one specific type of data, take a look at our other Instagram Actors.
❓FAQ
Can Instagram Post Scraper extract the number of reposts?
Reposts metric has been added to the Instagram app only recently, in summer 2025. It is not a part of Instagram Posts Scraper's datasets yet; our team is working to make that happen.
Can Instagram Post Scraper extract reels?
Yes, Instagram Post Scraper can extract reels. If you only want to extract reels, we recommend using Instagram Reel Scraper instead for efficiency. That Actor also extracts the number of shares of each reel.
Can this API scrape posts from private Instagram accounts?
No, it cannot. Only public accounts can be scraped. If you try, your dataset will only contain “undefined” entries.
Why is the likesCount value showing as -1 for some posts?
When a user has hidden the like count on their post, Instagram doesn’t display this data publicly. In those cases, the scraper returns -1 for likesCount which indicates that the information isn’t available.
What is a “sidecar” media type in Instagram posts data?
Sidecar is another word for an image carousel — when multiple images are posted as a single post.
Is there a way to extract only new posts from an Instagram profile?
Yes. You can use the Date filter parameter (onlyPostsNewerThan) to set the timeframe for the posts you wish to scrape. The date can be specified in two ways:
- Relative format: 1 day, 2 months, 3 years (ago)
- Absolute format: YYYY-MM-DD or full ISO format
All time values will be interpreted in UTC timezone.
Can I skip pinned posts when scraping Instagram posts?
Yes. You can choose whether to include or exclude pinned posts when scraping. Since pinned posts can sometimes be very old (and not relevant to your scrape), skipping them just makes sense sometimes. However, this option is only available in the JSON input, not in the user-facing UI. You can control it by setting it to trueor false. For more details, check the Input tab of the Actor.
Can I exclude pinned posts even if they are within the date range?
That’s not possible to filter out before scraping. The scraper will always include pinned posts if they match your Date filter settings. If you want to exclude them, you’ll need to filter the output data after the run by checking for isPinned: true and removing those items.
Is there any way to scrape only new posts (including pinned ones) while filtering out older pinned posts?
Yes, there is. You can combine the Date filter with Pinned posts parameter in JSON input. If you want to see posts newer than a certain date (using the Date filter onlyPostsNewerThan) and also include Pinned posts only if they meet that condition, set:
With this setup:
- Pinned posts that are newer than the time restriction will still be included.
- Older pinned posts will be skipped.
This way you’ll get the result you want: “Scrape pinned posts only if they fit the date restriction”.
Can I use integrations with Instagram Post Scraper?
You can integrate post data scraped from Instagram with almost any cloud service or web app. We offer integrations with Zapier, n8n, Slack, Make, Airbyte, Gumloop, CrewAI, Lindy, GitHub, Google Sheets, Google Drive, and plenty more.
Alternatively, you could use webhooks to carry out an action whenever an event occurs, such as getting a notification whenever Instagram Post Scraper successfully finishes a run.
Can I use Instagram Post Scraper as its an API?
Yes. The Apify API gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify Actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Click on the API tab for code examples, or check out the Apify API reference docs for all the details.
Can I scrape Instagram posts through an MCP Server?
With Apify API, you can use almost any Actor in conjunction with an MCP server. You can connect to the MCP server using clients like ClaudeDesktop and LibreChat, or even build your own. Read all about how you can set up Apify Actors with MCP.
For Instagram Post Scraper, go to the MCP tab and then go through the following steps:
- Start a Server-Sent Events (SSE) session to receive a
sessionId - Send API messages using that
sessionIdto trigger the scraper - The message starts the Instagram Post Scraper with the provided input
- The response should be:
Accepted
Is it legal to scrape Instagram posts?
Our scrapers do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly.
However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping.
Instagram Post Scraper not working
We’re always working on improving the performance of our Actors. If you have any technical feedback for Instagram Post Scraper or found a bug, please create an issue in the Issues tab.