Google News Scraper
Pricing
$20.00/month + usage
Google News Scraper
Gets featured articles from Google News with title, link, source, publication date and image.
Pricing
$20.00/month + usage
Rating
4.6
(13)
Developer
Kristýna Lhoťanová
Maintained by CommunityActor stats
79
Bookmarked
3.1K
Total users
42
Monthly active users
45 days
Issues response
a year ago
Last modified
Categories
Share
What data does Google News Scraper collect?
Google News Scraper allows you to extract news metadata such as title, link, source, publication datetime and image.
Query-based search
The Actor provides a simple interface where you can define your search query, language, region, and date range. Unlike manually browsing Google News, which limits you to approximately 100 results per search, Google News Scraper allows you to retrieve significantly more results without restrictions.
To bypass the usual result limits, the scraper can automatically filter news articles by date. If you set maxItems to a value greater than 100, the scraper will fetch news articles day by day until it reaches the specified limit.
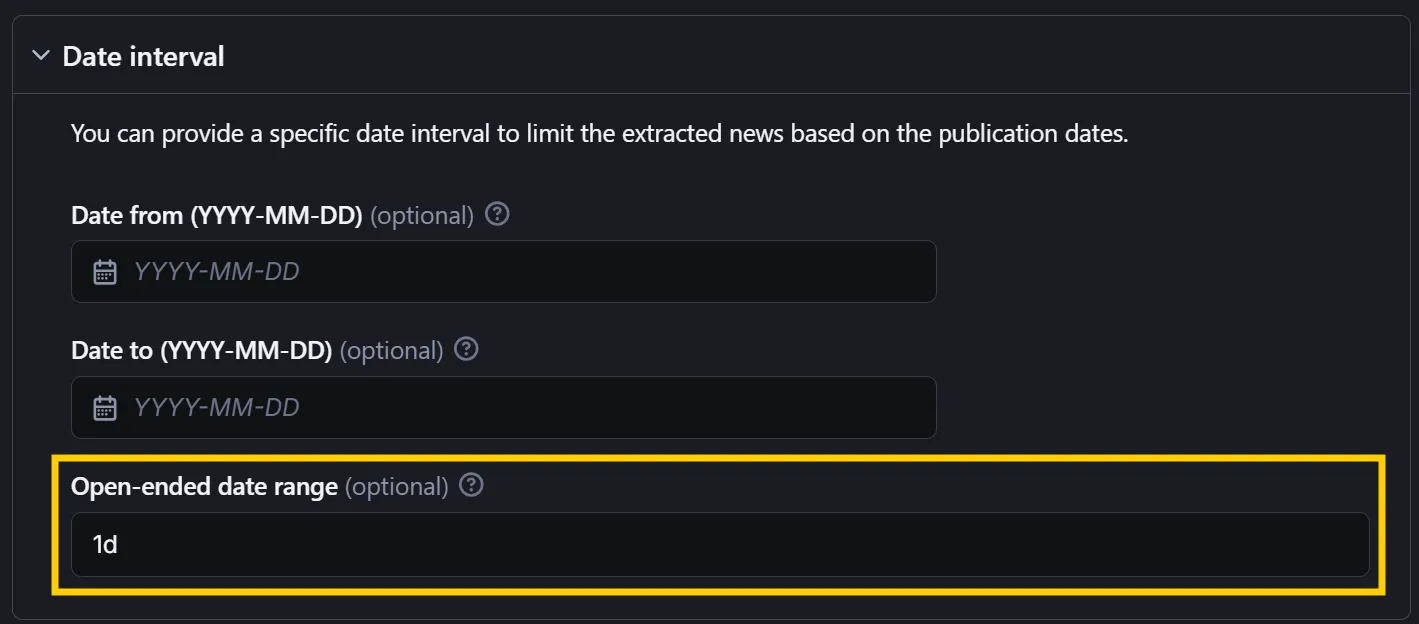
For more precise control over the date range, you can use the dateFrom and dateTo fields in the YYYY-MM-DD format. Alternatively, you can specify an open-ended date range using the openEndedDateRange field with values such as:
1h– retrieves news from the past hour7d– retrieves news from the past week1y– retrieves news from the past year
You can combine numbers with the h, d, or y shortcuts to customize your date range as needed.
Advanced search filters
You can also use advanced search operators in your queries, such as intitle, inurl, site, exclude operator -, exact match with double-quotes "", AND, OR and more. Example queries with advanced operators:
| Query | Explained |
|---|---|
intitle:"AI" AND site:bbc.com | Finds articles with "AI" in the title from BBC. |
site:reuters.com "stock market" -crypto | Finds stock market articles on Reuters, excluding crypto-related ones. |
"Samsung Galaxy S25" AND (review OR comparison) | Searches for reviews or comparisons of Samsung Galaxy S25. |
site:nytimes.com intitle:"election" after:2025-01-01 | Retrieves recent NY Times articles with "election" keyword in the title. |
inurl:blog OR inurl:news "climate change" | Searches for climate change mentions in blog or news URLs. |
You may already know some of the operators from Google search or Apify's Google Search Scraper. For more information, see Google Guide on Search Operators.
Topic-based search
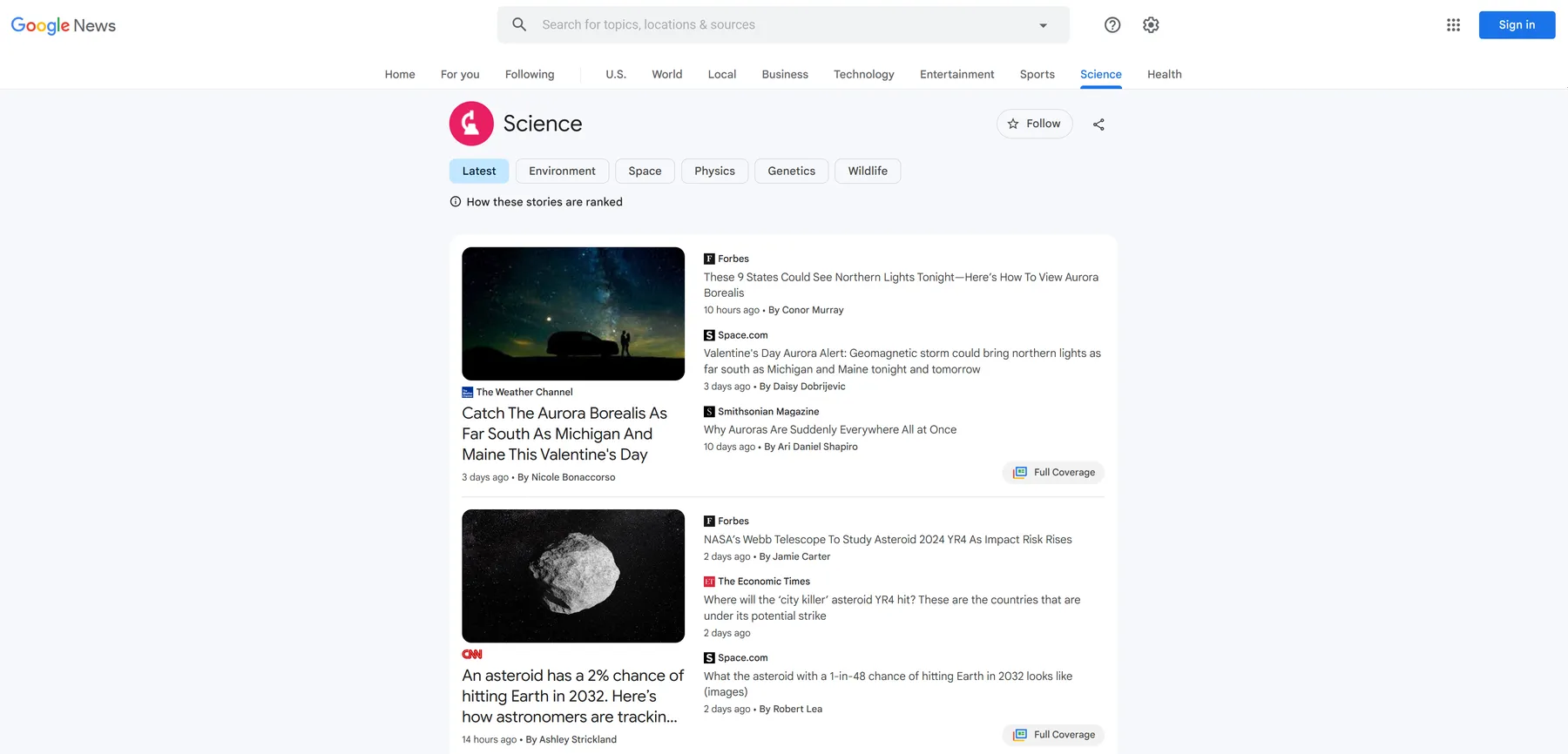
Google News Scraper also supports topic-based search. You can search for news from one of the topics predefined in topics input field:
WORLD🌎NATION🚩BUSINESS🪙TECHNOLOGY💻ENTERTAINMENT🎸SPORTS🏒SCIENCE🧪HEALTH🧑⚕️
Hashed Topics
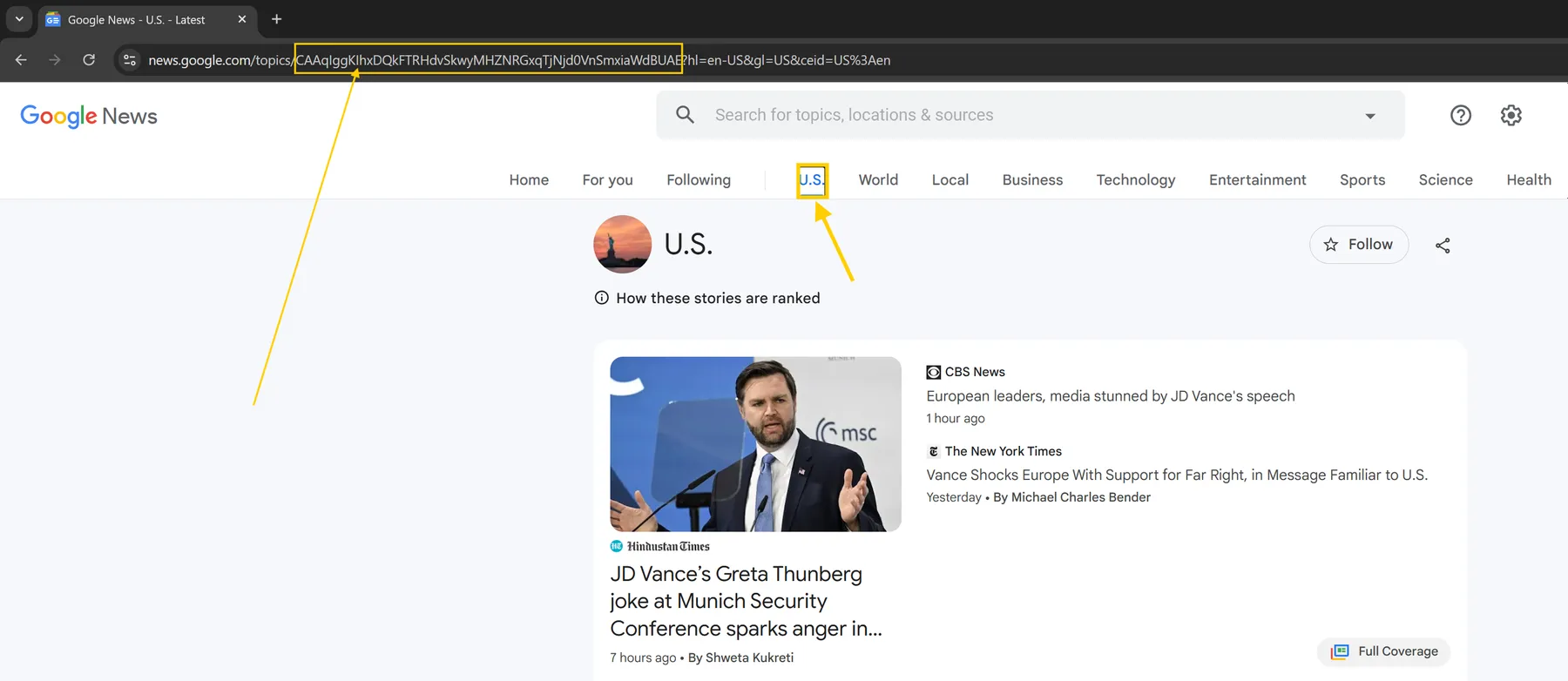
The scraper also supports hashed topics, allowing you to extract news based on specific topic IDs from Google News. Simply copy the topic ID from the Google News URL and paste it into the topicsHashed input field.
For example, if you want to find news about your home country but published by foreign sources or in different languages, you can:
- Click on your country in Google News.
- Copy the topic ID from the URL.
- Paste it into the
topicsHashedarray. - Set the
languagefield to your preferred language and region (e.g.,DE:de).
This way, you can for example retrieve the latest news from the US but published by German sources like zdf.de or spiegel.de. Similarly, you can search for news about a non-English-speaking country and get results from international sources such as reuters.com, bbc.co.uk, independent.co.uk, or variety.com.
Topic Sections
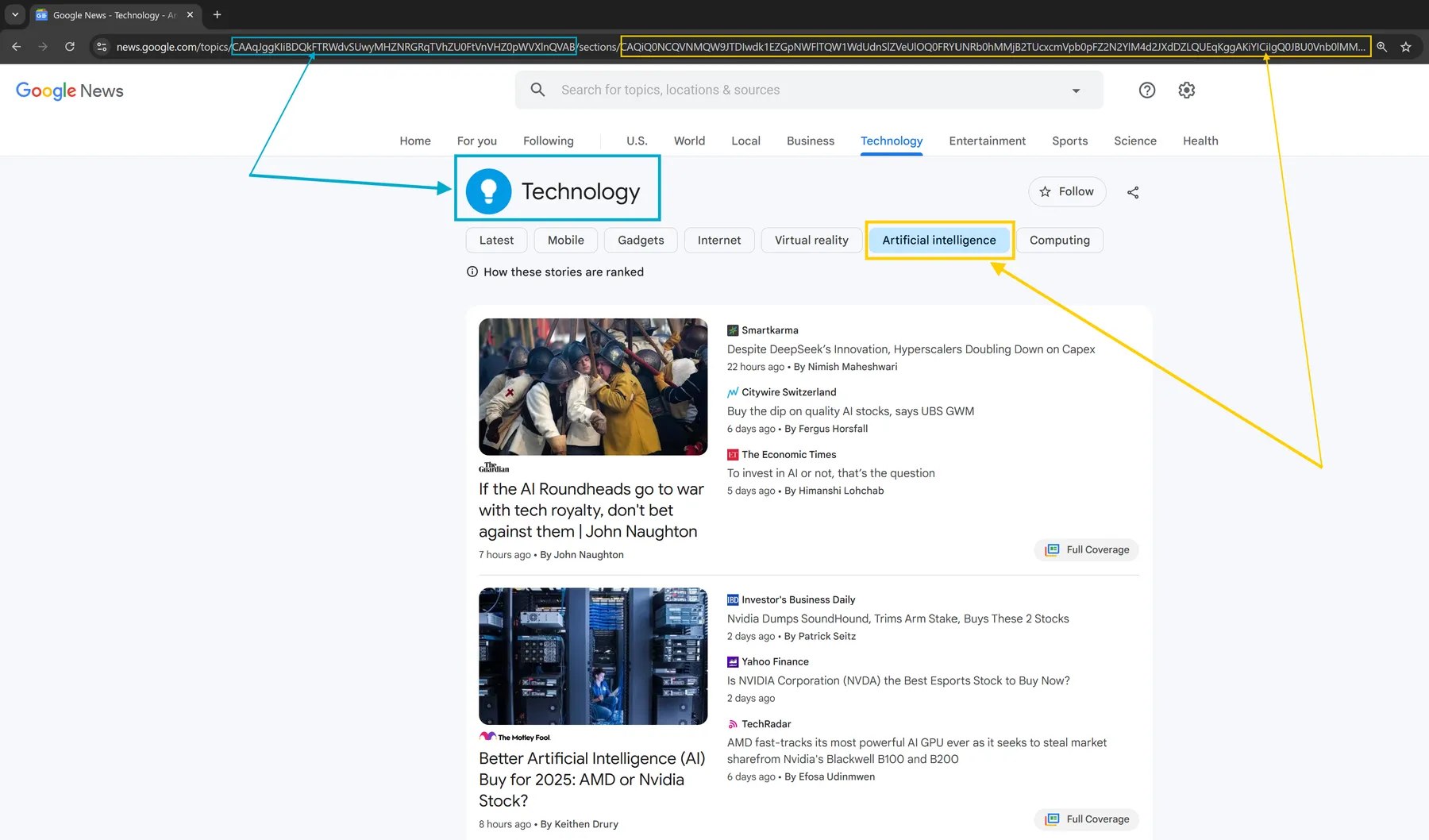
The scraper also allows you to refine your search by targeting specific sections within broader topics. For example, you can extract news from the NHL section under Sports or Artificial Intelligence within the Technology category.
Imagine you need to scrape AI-related news from the section Technology > Artificial Intelligence, which is available at the following URL:
Simply copy the {TOPIC_ID}/section/{SECTION_ID} part of the URL and paste it into the topicsHashed array to target that specific section:
Example output
To obtain a detailed output with decoded article links and image URLs, set the fetchArticleDetails input field to true. Extracted news are then stored in a following format:
NOTE: Image URLs are retrieved directly from target article websites and may differ from those displayed on the Google News website. The scraper relies on the Google News RSS API, which does not include image links. However, using the RSS API instead of web browsing allows the scraper to efficiently gather all data through simple HTTP requests, making the process faster and more cost-effective.
If you set fetchArticleDetails to false, the scraper will run significantly faster and at a lower cost, but the output will only include URLs in the RSS feed format, such as:
The output will be simplified to include RSS links only and exclude preview images: