Glassdoor Scraper
Pricing
$19.99/month + usage
Glassdoor Scraper
Extract Glassdoor job posts including salary, skills, experience, direct apply url, company socials and ratings. Search with custom keywords or predefined job titles and locations. Bulk URL support for scaling your Job Automation. Export as JSON, CSV, Excel, XML, HTML Table, RSS
Pricing
$19.99/month + usage
Rating
4.7
(6)
Developer
Radeance
Maintained by CommunityActor stats
15
Bookmarked
264
Total users
4
Monthly active users
4 months ago
Last modified
Categories
Share
💎 Glassdoor Jobs & Company Scraper
| Discover more ➤ | Wellfound Jobs & Company Scraper | Kununu Company Reviews Scraper | Semrush Scraper | Similarweb Scraper |
|---|
The Glassdoor Jobs & Company Scraper on Apify extracts structured job and company data from Glassdoor, one of the world’s largest career platforms.
It captures full job details including descriptions, salaries, skills, direct apply links, and locations, while also providing rich company insights like ratings, headquarters, size, industry, and leadership scores.
Designed for recruiters, analysts, and job seekers, this Actor delivers thousands of listings in minutes with clean, structured outputs (JSON, CSV, XLSX, and more). Whether you’re tracking compensation trends, analyzing employer reputation, or sourcing talent, it gives you complete access to Glassdoor’s job and company intelligence at scale.
🗝️ Key Features
- ✅ 50+ Predefined Job Titles:
Software Engineer, Data Scientist, Product Manager, Marketing Operations, DevOps Engineer, and many more - ✅ 40+ Predefined Locations:
Remote, major cities worldwide (New York, San Francisco, London, Berlin, Tokyo, etc.) - ✅ Advanced Filters:
Salary ranges, company ratings (0-5 stars), remote-only jobs, easy-apply positions - ✅ Industry & Sector Filtering:
Target specific industries like Software Development, Healthcare, Financial Services - ✅ Custom Search:
Use custom keywords and locations for maximum flexibility - ✅ Bulk URLs:
Use multiple of your own listing or job page links - ✅ Date Filters:
Jobs posted in the last day, week, month, or year
📌 Output
JSON Output
Table View Output
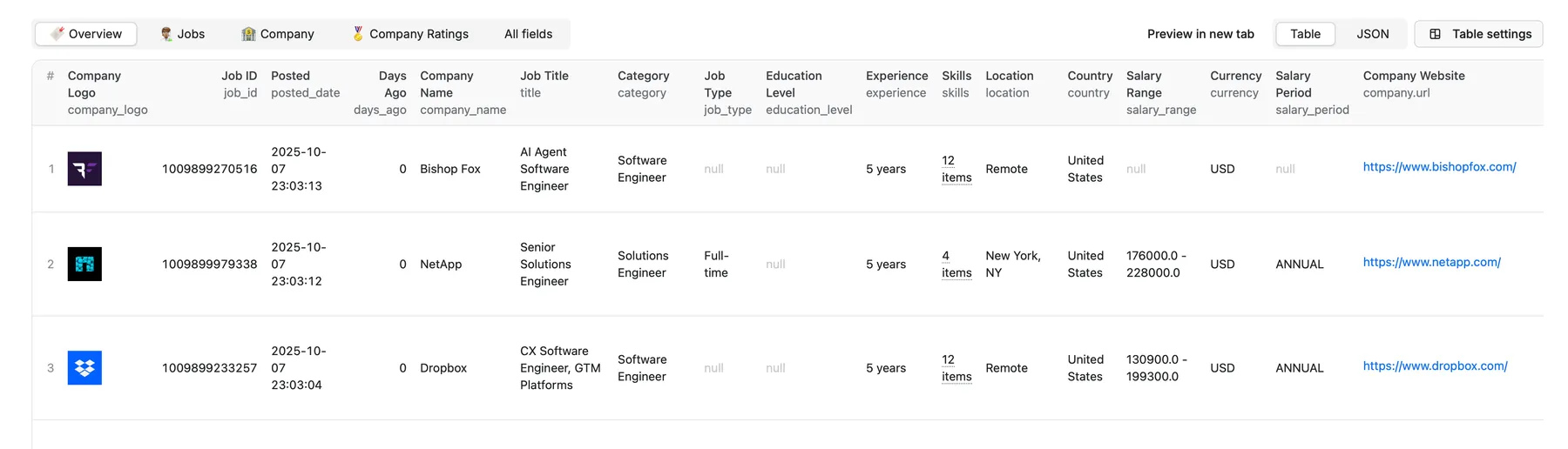
Overview Table 🔎
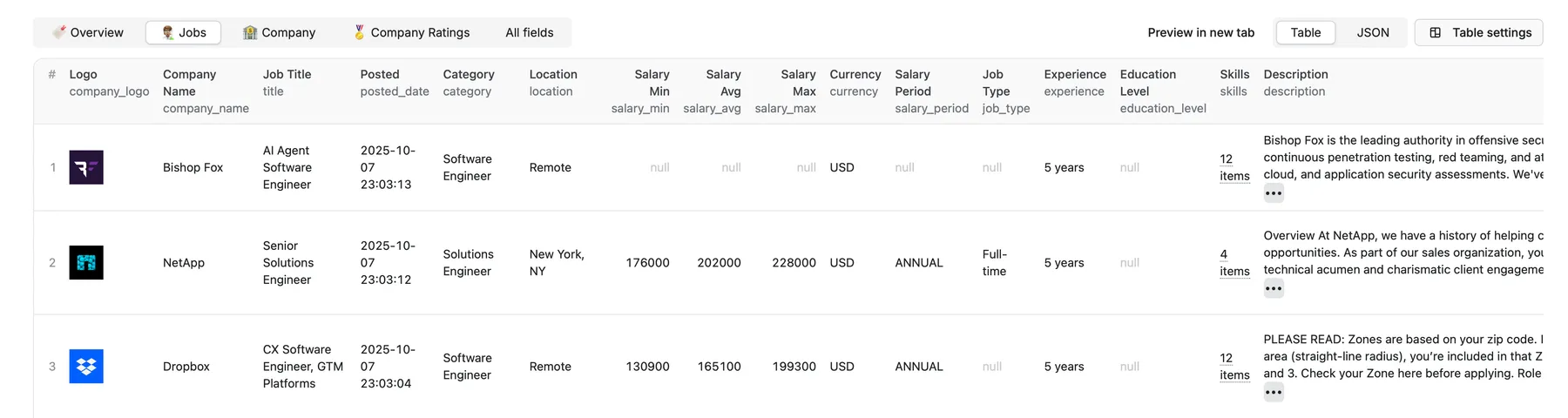
Jobs Table 🧑🏽🔬
Company Table 🏦
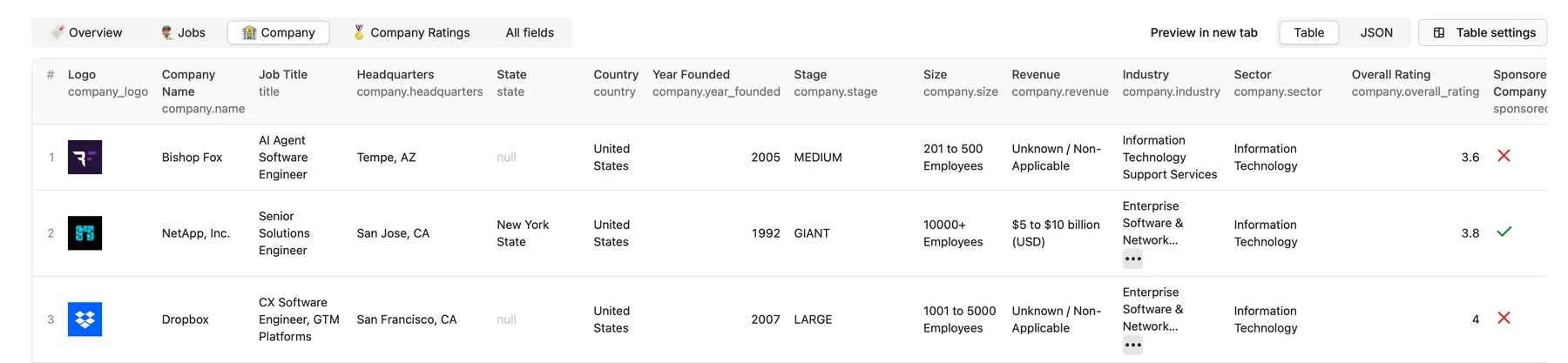
Ratings Table 🏅
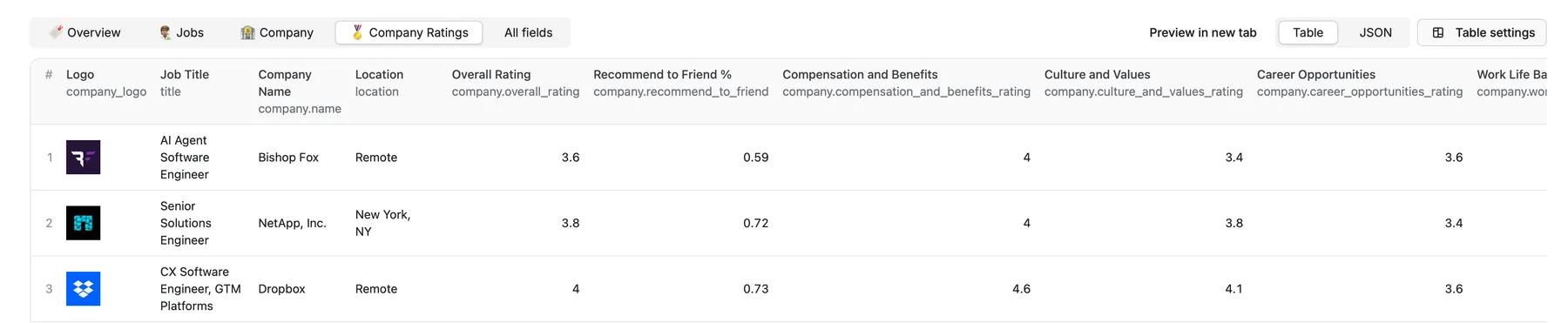
📍 Input
If you use this actor on the apify platform, the UI Input interface is quite self explaining but here are some guidelines to help you use it:
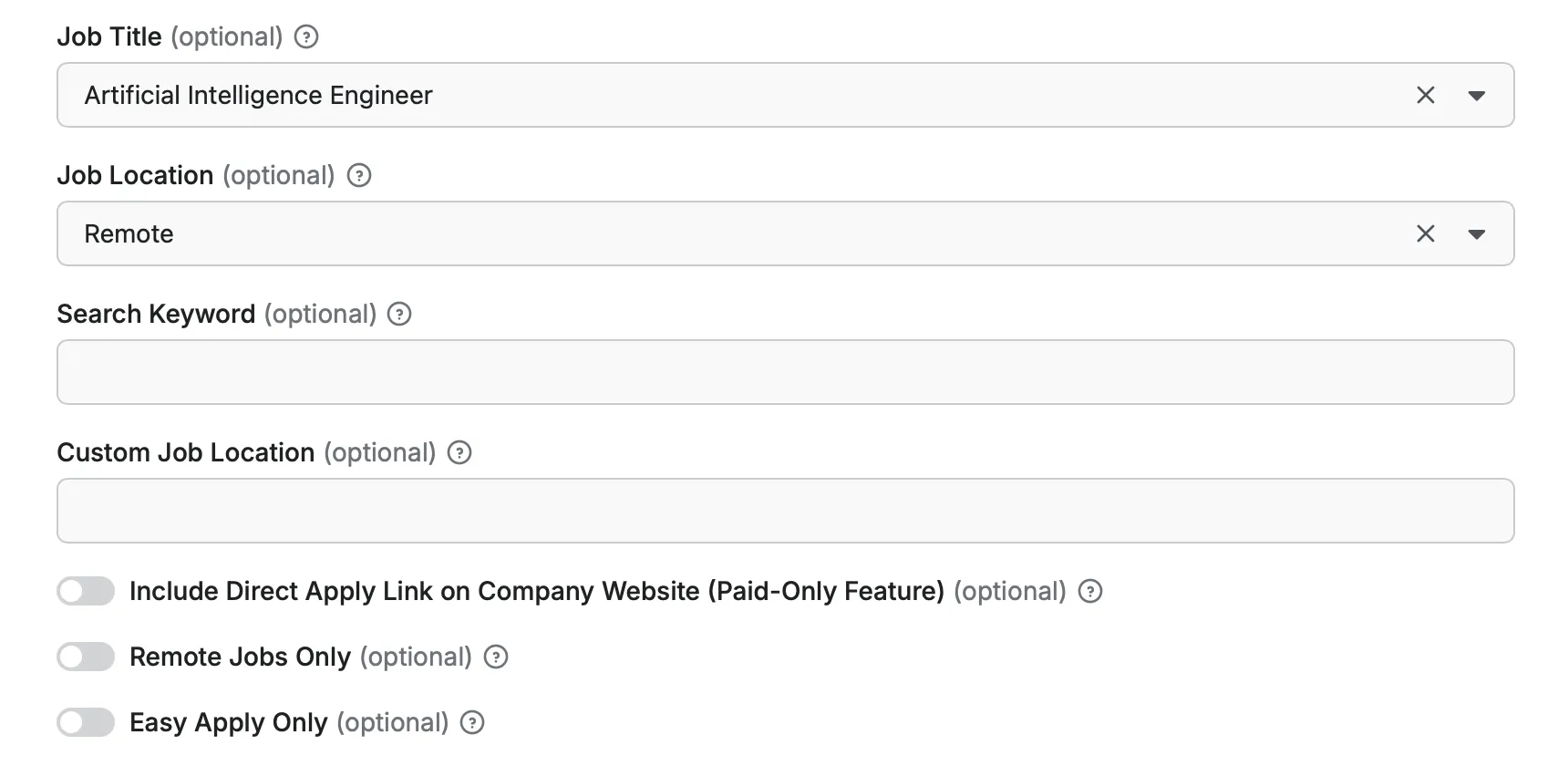
- job_title: (Optional) (String) (Default: software-engineer)
Select your desired job title from 50+ predefined options including Software Engineer, Data Scientist, Product Manager, DevOps Engineer, and many more specialized roles.
- job_location: (Optional) (String) (Default: new-york)
Choose your target job location from 40+ global options including Remote, major cities worldwide (New York, San Francisco, London, Berlin, Tokyo), and specific countries.
- keyword: (Optional) (String) (Default: empty)
Enter a custom keyword or job title to search for. If you leave this field empty, the scraper will use the job title selected above.
- location: (Optional) (String) (Default: empty)
Enter a custom job location to search for. If you leave this field empty, the scraper will use the job location selected above.
- direct_apply: (Optional) (Boolean) (Default: false)
If enabled, the scraper will include a direct apply link to the company website in the output if available. This feature will make the run a bit slower (Paid-Only Feature).
- remote_only: (Optional) (Boolean) (Default: false)
Filters job listings to show only remote positions. When enabled, only jobs that offer remote work will be included in results.
- easy_apply: (Optional) (Boolean) (Default: false)
Filters job listings to show only positions with easy apply option available. Helps find jobs with streamlined application processes.
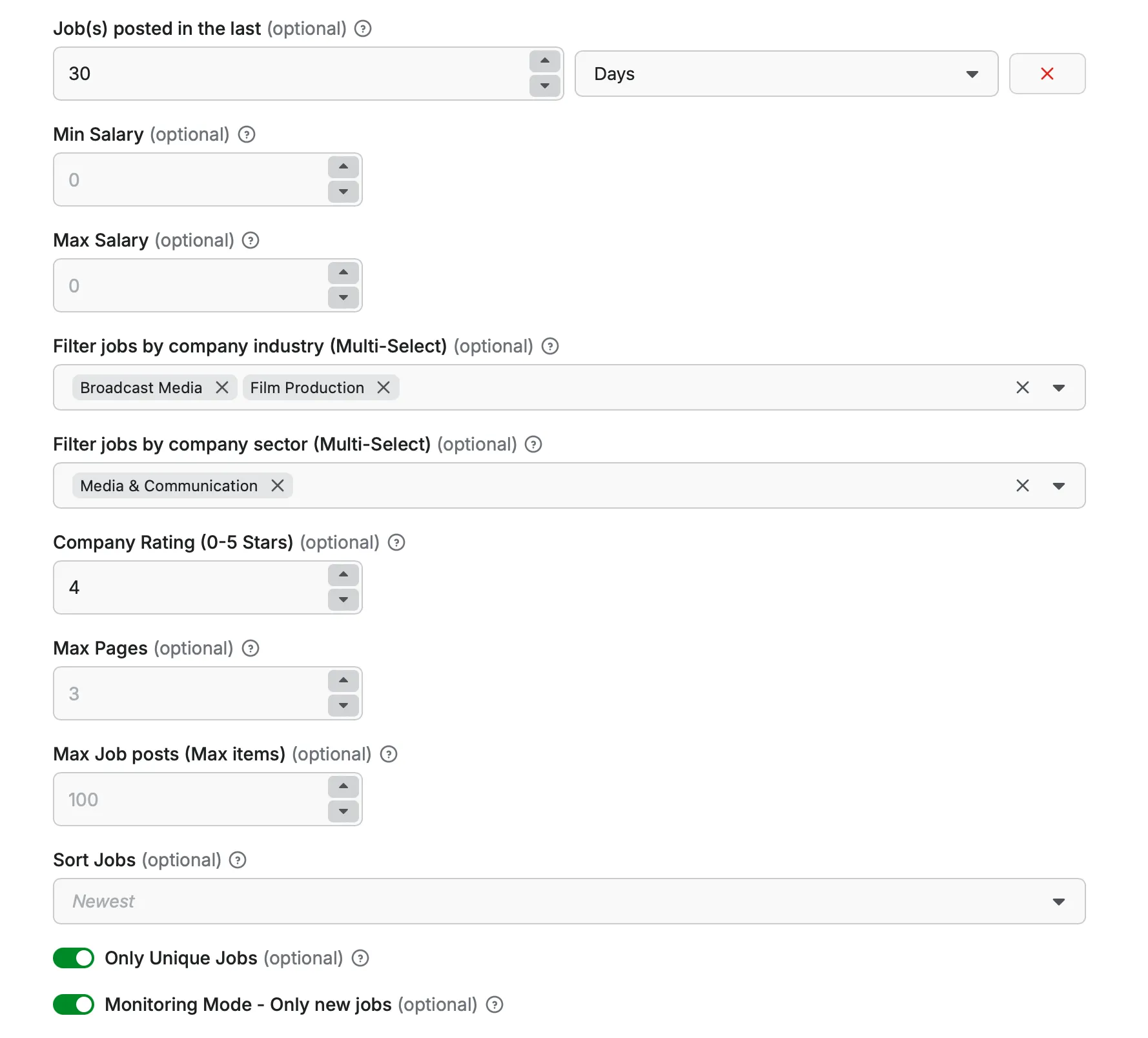
- job_posted: (Optional) (String) (Default: empty)
Filter jobs by posting date in relative format (e.g., "7 days", "2 weeks", "1 month"). Only jobs posted within the specified timeframe will be scraped.
- min_salary: (Optional) (Number) (Default: 0)
Set minimum salary threshold to filter job listings. Only jobs with salaries at or above this amount will be included (0 means no filter).
- max_salary: (Optional) (Number) (Default: 0)
Set maximum salary threshold to filter job listings. Only jobs with salaries at or below this amount will be included (0 means no filter).
- company_industry: (Optional) (Array) (Default: empty)
Filter jobs by specific company industries using multi-select options. Choose from 40+ industries like Software Development, Healthcare, Financial Services, Biotech & Pharmaceuticals, etc.
- company_sector: (Optional) (Array) (Default: empty)
Filter jobs by company sectors using multi-select options. Choose from sectors like Information Technology, Healthcare, Financial Services, Education, Manufacturing, etc.
- company_rating: (Optional) (Number) (Default: 0)
Filter jobs by minimum company rating (0-5 stars). Only companies with ratings at or above this threshold will be included (0 means no filter).
- max_pages: (Optional) (Number) (Default: 3)
Enter the number of pages you want the scraper to go through. Maximum allowed is 30 pages per search query.
- max_items: (Optional) (Number) (Default: 100)
Set the maximum number of job posts to scrape. Helps control the scope of your scraping session (maximum 10,000 jobs).
- sorting: (Optional) (String) (Default: newest)
Choose how to sort job listings. Options are "newest" (most recently posted first) or "oldest" (oldest posts first).
- only_unique_jobs: (Optional) (Boolean)
If enabled, it will only keep unique job posts adding a deduplication step.
Default: True
- monitoring_mode: (Optional) (Boolean)
If enabled, it will only scrape new job posts that have not been previously scraped.
Default: True
Allowed URL formats
| Job Listings | Job Pages |
|---|---|
https://www.glassdoor.com/Job/data-scientist-jobs-SRCH_KO0,14.htm | https://www.glassdoor.com/job-listing/data-engineer-ipsos-zrt-JV_KO0,13_KE14,23.htm?jl=1009262165891 |
- urls: (Optional) (Array) (Default: empty)
Provide specific Glassdoor job listing or job page URLs to scrape directly. Maximum of 5 URLs allowed at a time. When using this field, job & location parameters will be ignored.
- page_offset: (Optional) (Number) (Default: 1)
Set the starting page number for scraping. Useful for continuing from a specific page or skipping initial pages (Paid-Only Feature).
Supported Glassdoor Regions
We currently support the following Glassdoor regions.
| Country | Link | Supported |
|---|---|---|
| Argentina | https://www.glassdoor.com.ar | ✅ |
| Australia | https://www.glassdoor.com.au | ✅ |
| België (Nederlands) | https://nl.glassdoor.be | ✅ |
| Belgique (Français) | https://fr.glassdoor.be | ✅ |
| Brasil | https://www.glassdoor.com.br | ✅ |
| Canada (English) | https://www.glassdoor.ca | ✅ |
| Canada (Français) | https://fr.glassdoor.ca | ✅ |
| Germany | https://www.glassdoor.de | ✅ |
| España | https://www.glassdoor.es | ✅ |
| France | https://www.glassdoor.fr | ✅ |
| Hong Kong | https://www.glassdoor.com.hk | ✅ |
| India | https://www.glassdoor.co.in | ✅ |
| Ireland | https://www.glassdoor.ie | ✅ |
| Italia | https://www.glassdoor.it | ✅ |
| México | https://www.glassdoor.com.mx | ✅ |
| Nederland | https://www.glassdoor.nl | ✅ |
| New Zealand | https://www.glassdoor.co.nz | ✅ |
| Austria | https://www.glassdoor.at | ✅ |
| Suisse (German) | https://de.glassdoor.ch | ✅ |
| Singapore | https://www.glassdoor.sg | ✅ |
| Suisse (Français) | https://fr.glassdoor.ch | ✅ |
| United Kingdom | https://www.glassdoor.co.uk | ✅ |
| United States | https://www.glassdoor.com | ✅ |
JSON Input Example
If you decide to use this actor from your favourite programming language. This would be a sample JSON input if you use the apify api via CURL, Python, JS etc.
🖇️ Detailed Output Fields
-
Job Details:
- Job ID: Unique identifier for the job.
- Posted Date: The date and time when the job was posted.
- Days Ago: Number of days since the job was posted.
- Title: Title of the job position.
- Category: Job category or field.
- Job Type: Type of employment (e.g., Full-time, Part-time).
- Education Level: Required education level for the job.
- Experience: Required years of experience for the job.
- Short Description: Brief summary of the job.
- Description: Detailed description of the job responsibilities and requirements.
- Direct Apply URL: Link to apply directly on the company's website
- Apply URL: Link to apply on the Glassdoor platform
-
Company Details:
- Company ID: Unique identifier for the company.
- Company Name: Name of the company.
- Company Rating: Overall rating of the company.
- Location: Location of the job.
- State: State where the job is located.
- Country: Country where the job is located.
- Latitude: Latitude coordinate of the job location.
- Longitude: Longitude coordinate of the job location.
-
Salary Information:
- Salary Range: Salary range offered for the job.
- Salary Min: Minimum salary offered.
- Salary Avg: Average salary offered.
- Salary Max: Maximum salary offered.
- Currency: Currency in which the salary is listed.
- Salary Period: Salary period (e.g., Annual).
- Salary Source: Source of the salary information.
-
Skills and Keywords:
- Skills: List of skills required for the job.
- Keywords: Relevant keywords associated with the job.
-
Job Attributes:
- Organic: Indicates if the job is an organic listing.
- Sponsored Job: Indicates if the job is a sponsored listing.
- Sponsored Company: Indicates if the company is a sponsored employer.
- Easy Apply: Indicates if the job has an easy apply option.
- Expired: Indicates if the job listing has expired.
- Job URL: Direct link to the job listing.
-
Company Information:
- Company ID: Unique identifier for the company.
- Name: Name of the company.
- Headquarters: Headquarters location of the company.
- Year Founded: Year the company was founded.
- Size: Size of the company.
- Stage: Development stage of the company.
- Industry: Industry in which the company operates.
- Sector: Sector of the company.
- Overall Rating: Overall rating of the company.
- CEO Rating: Rating of the company's CEO.
- CEO Ratings Count: Number of ratings for the company's CEO.
- Recommend to Friend: Percentage of employees who would recommend the company to a friend.
- Compensation and Benefits Rating: Rating of the company's compensation and benefits.
- Culture and Values Rating: Rating of the company's culture and values.
- Career Opportunities Rating: Rating of the company's career opportunities.
- Senior Management Rating: Rating of the company's senior management.
- Work Life Balance Rating: Rating of the company's work-life balance.
- Logo URL: Direct link to the company's logo image.
- URL: Direct link to the company's website.
- Benefits: Information about the company's benefits.
- Revenue: Company's revenue.
- Company Logo: Direct link to the company's logo image.
🍪 Usage Limits
This service has different usage limits depending on your subscription status:
| User Type | Daily Runs | Direct Apply Link Option | Max Pages per Run | Reset Period |
|---|---|---|---|---|
| Free | 5 runs | Trial for 3 run(s) | 3 pages | 24-hours |
| Paid | Unlimited | Unlimited | Unlimited | N/A |
How Limits Work
- Free users: Limited to 5 runs with up to 3 pages per run in a 24-hour period from your first usage. Direct Apply Link Option is limited to 3 runs total per day.
- Paid users: No limits on the number of runs or the number of pages per run or direct apply link option.
💭 FAQ
How do i make a quick search for a specific job title and location?
Just select your desired job title and location from the dropdown menus of predefined job titles and locations or use the custom fields instead. You can also add additional filters like salary range, company rating, and job posting date to refine your search. Then click "Start" to run the scraper.
Can i use custom Glassdoor URLs from my own searches?
Yes, you can provide up to 5 specific Glassdoor job listing or job page URLs in the "urls" input field. When using this option, the scraper will ignore the job title and location parameters and scrape data directly from the provided URLs and their associated job pages.
How many jobs can i scrape in one run?
You can scrape up to 10,000 job listings in a single run. You can control the number of jobs scraped by setting the "max_items" input parameter. Additionally, you can limit the number of pages the scraper goes through using the "max_pages" parameter (up to 30 pages per search query). But be aware that scraping a large number of jobs may take longer to complete and is throttled by Glassdoor.
How do i get direct apply links to the company website?
To get direct apply links to the company's website, enable the "direct_apply" input option. When this option is set to true, the scraper will include a direct apply link in the output if available. Note that enabling this feature is only available for paying users. It may slow down the scraping process slightly.
⚙️ While the scraper is running
During the run, the actor will output log messages letting you know what is going on at any point. Each message always contains specific information about the process including which url / page the actor is working on.
If you provide invalid inputs to the actor, it will immediately stop with a failure state and output log messages explaining what is wrong. If you are unsure what went wrong feel free to open up an issue in the issue tab.
🔗 Legality of web scraping
The Glassdoor Jobs & Company Scraper is designed to ethically extract only publicly available job data and company information, and it does not scrape private user data such as personal email addresses or personal identifiers.
Our services are ethical and do not extract any private user data. They only extract what individuals or companies chose to share publicly. We therefore believe that our services, when used for ethical purposes by our users, are safe to use. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. For more information you can read this blog post on the legality of web scraping from Apify.
💬 Feedback and Support
Your satisfaction is important to us! Therefore we are constantly striving to enhance the performance of our services.
If you have any technical feedback or encounter any bugs within the Glassdoor Jobs & Company Scraper, please create an issue in the Actor’s Issues tab on the Apify Console to let us know about it. We will look into it as soon as possible.
You can also contact us directly for help on integrations, customized projects or new use cases at business@radeance.com.