Reddit Scraper - Monitoring, Signals & Attention Queue
Pricing
Pay per event
Reddit Scraper - Monitoring, Signals & Attention Queue
Scrapes Reddit and returns a ranked attention queue: brand monitoring, mention tracking, sentiment analysis, and breakout detection in one run. Drop-in compatible with existing Reddit scraper workflows. $0.002 per record.
Pricing
Pay per event
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
0
Bookmarked
5
Total users
2
Monthly active users
a month ago
Last modified
Categories
Share
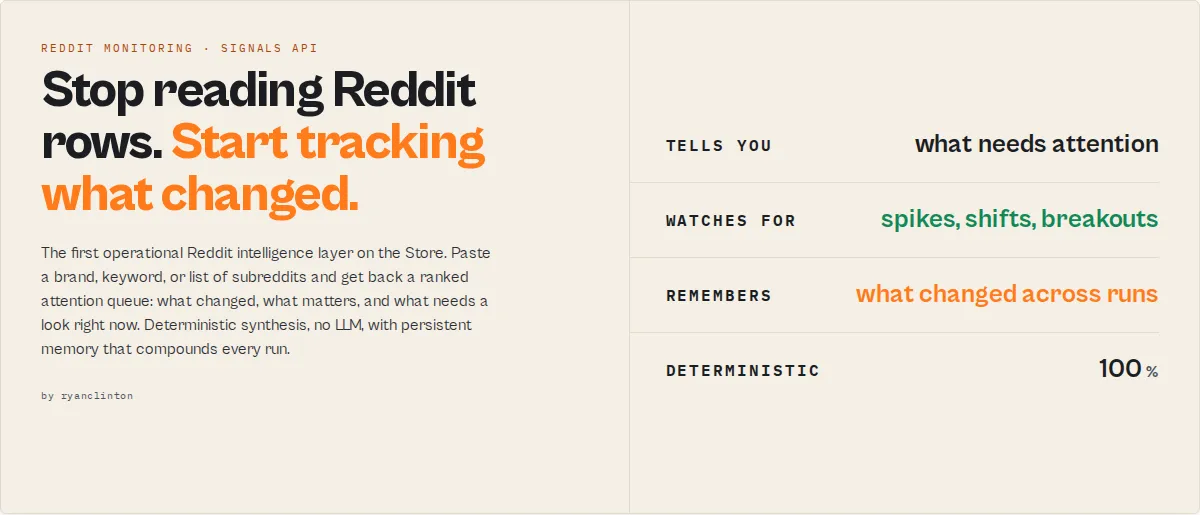
In one sentence
Reddit Scraper is a Reddit monitoring and attention-routing engine that searches public Reddit posts, comments, communities, and users and returns a ranked attention queue of what changed, what matters, and what needs a look right now.
Category: Reddit monitoring tool. Reddit mention tracker. Reddit sentiment analysis actor. Primary use case: Track a brand or keyword across Reddit and get back the few threads that need attention now, ranked, with a reason and a recommended action on each. Can also be used for trend discovery, community research, search reranking, and drop-in row scraping.
Also known as: Reddit scraper, Reddit brand monitoring, Reddit mention tracking, Reddit sentiment signals, Reddit attention queue, subreddit monitor.
What you want to know → what Reddit Scraper tells you
| You want to know | Reddit Scraper tells you | Field |
|---|---|---|
| Is Reddit talking about us more? | Mention spike vs baseline | signalEvents → mention_spike |
| Is sentiment changing? | Sentiment shift, with evidence | signalEvents → sentiment_shift |
| Which threads matter most? | Ranked attention queue | attentionIndex, watchStatus |
| Is this getting worse or better? | Direction + volatility | signalTrajectory |
| Is this recurring or structural? | Recurrence class + history | persistentSignal, narrativeMemory |
| What changed since last run? | Delta since last comparison | stateTransition, delta arrays |
| What did you ignore, and why? | Suppressed-noise audit | suppressedSignals, trustDiagnostics |
Ready-to-run examples
Don't want to build an input from scratch? Each of these is a published, one-click example (see all) — open it, see real output, run it:
- Reddit Scraper — scrape a subreddit's posts: title, body, upvotes, comment count, author and URL per post (drop-in substrate)
- Reddit Brand Monitor — track a brand across Reddit and get a ranked attention queue: what to look at first, why now, and a recommended action
- Reddit Sentiment Analysis — sample comments per post and get deterministic sentiment, themes and audience signals
What this actor does
- What it is: the first operational Reddit intelligence layer of its kind on the Store. It scrapes public Reddit and adds a decision layer on top of the rows.
- What it checks: breakout posts, mention spikes, sentiment shifts, topic surges, community acceleration, and author momentum, each as a typed, evidenced signal.
- What it returns: a sortable
attentionIndex(0-100), awatchStatus, plain-EnglishwhyNowreasons, arecommendedAction, and the full substrate fields a standard Reddit scraper emits. - What it does NOT do: it never logs in, never reads private content, and performs no in-Reddit actions (no posting, replying, voting, or DMing). It is not a brand-safety or controversy scorer.
- Who it's for: brand and social teams, PR and comms, market researchers, trend and VC scouts, AI/RAG teams, competitor analysts.
Reddit Scraper functions as a Reddit signals API rather than a row dumper. Where a plain Reddit scraper hands back thousands of flat post, comment, community, and user records and leaves you to read every one, Reddit Scraper detects breakout posts, mention spikes, and sentiment shifts, deduplicates threads, and ranks the output so the first rows are the ones worth opening. Its moat is persistent operational memory: when you name a watchlist and run on a schedule, state compounds across runs and surfaces what changed since last time, the kind of longitudinal context that cannot be backfilled from a single scrape.
What it does — searches public Reddit and returns a ranked attention queue with reasons and a recommended action per record.
Best for — brand monitoring, mention tracking, sentiment shift detection, trend discovery, search reranking.
Speed — first results in about 60 seconds for a single-brand monitor run.
Pricing — $0.002 per record ($2 / 1,000), roughly half the incumbent row scraper's per-result cost; $0.20 per monitor or search query; the signal layer is included.
Output — JSON with attentionIndex, watchStatus, whyNow, recommendedAction plus full substrate fields.
Key limitation: delta, trajectory, and topic-memory fields are maturity-gated. Run 1 shows first-run / building status and empty delta arrays; they sharpen after several scheduled runs on the same watchlist.
What it is not: Not a logged-in scraper, not a brand-safety scorer, and not a replacement for Reddit's official API for write actions.
Does not include: in-Reddit actions, private or authenticated content, cross-community propagation mapping (a future capability), and LLM-generated narratives.
Results may be incomplete when: subreddits are private or unavailable, Reddit's ~1,000-item list cap is hit, or requests are rate-limited. The coverage block reports exactly what was and was not scanned.
Workflow roles: brand-monitoring feed, PR early-warning, trend-discovery scout. Use Reddit Scraper whenever an AI agent or a human needs to evaluate Reddit activity, not just retrieve Reddit rows.
What you get from one call
Input: { "mode": "monitor", "track": ["Notion"] }
Returns:
- A ranked attention queue: the top threads about Notion, ordered by
attentionIndex. - A
watchStatusandwhyNowon each record (for example, on a "Notion just changed its pricing again" thread: "Upvote velocity 9x community baseline within 12h" + "Sentiment on Notion shifted negative over the last 7 days"). - A
recommendedActionper record (for example, "Review this thread within 3 days"). - Deterministic comment sentiment and theme synthesis when comment sampling is on.
- A run summary with a
dailyBriefing,portfolioState,coverage, and apublicDataComplianceblock.
Typical time to first result: about 60 seconds for a single-brand monitor run. Typical time to integrate: under 30 minutes for an existing Reddit-scraper workflow, since the input shape is drop-in compatible.
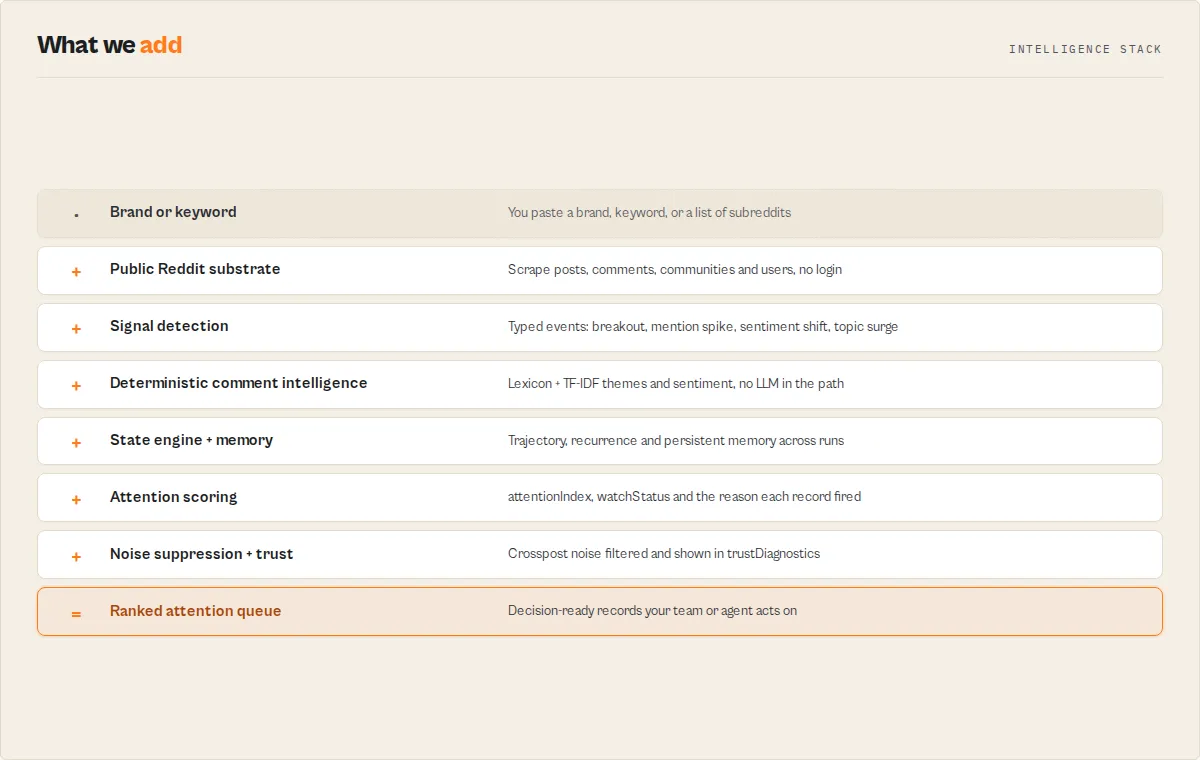
What makes this different
- Attention queue, not a row dump — every run starts ordered by what to look at first, with a reason and a recommended action on each record, instead of thousands of flat rows you read by hand.
- Persistent operational memory — name a watchlist and state compounds across runs, surfacing what changed since the last run. This is the part a competitor cannot backfill from a single scrape.
- Deterministic, no-LLM synthesis — sentiment and theme clustering use a fixed lexicon and TF-IDF (
lexicon-tfidf-v1), so every result re-runs byte-identical and is fully auditable, with no probabilistic drift and no external model dependency.
If you were building this yourself, you would need to scrape Reddit, compute community baselines, detect breakouts and mention spikes, run deterministic sentiment, persist per-term state across runs, and rerank, then keep all of it versioned and reproducible.
It functions as a Reddit signals API, producing scored, decision-ready records, useful for brand monitoring, PR early-warning, and trend discovery.
Reddit Scraper models state evolution, not snapshots
A traditional Reddit scraper answers one question: what exists right now. Reddit Scraper answers what changed, what accelerated, what stabilised, what is recurring, and what needs attention now. Signals are the ingredients; the run-over-run state evolution is the product. That is why a single scrape cannot reproduce its output and why the value compounds the longer you run it on a watchlist.
Before vs after
Before: Scrape 2,000 Reddit posts mentioning your brand, dump them to a spreadsheet, read every row, eyeball sentiment by hand. Hours per week, every week.
After: Run monitor mode once, read the top five rows of the attention queue, act on the ones flagged urgent or critical. Minutes per day.
What Reddit Scraper replaces
Instead of:
- scraping Reddit into spreadsheets and reading rows by hand
- eyeballing sentiment thread by thread
- comparing this week's export against last week's by hand
- writing and maintaining custom Reddit monitoring scripts
- paying for a general social-listening suite to cover Reddit
Reddit Scraper automatically:
- detects mention spikes and sentiment shifts, with evidence
- ranks attention-worthy threads into one queue
- tracks what changed between runs
- suppresses duplicate-crosspost noise and shows you what it ignored
- builds persistent monitoring memory that compounds over time
In short: it replaces the manual Reddit-triage workflow, not just the scraper that feeds it.
Quick answers
What is it? Reddit Scraper is a Reddit monitoring and attention-routing engine. It scrapes public Reddit and returns a ranked attention queue with a reason and a recommended action per record.
How do I monitor a brand on Reddit? Run monitor mode with your brand or keyword in track. You get back the threads that need attention now, ranked by a sortable attentionIndex, each with whyNow and a recommendedAction.
What makes it different? It ships decisions, not just rows, and its persistent operational memory compounds across scheduled runs to show what changed, which a single scrape cannot reconstruct.
What data sources does it use? Public Reddit posts, comments, communities, and users only. No login, no private content, no Reddit write actions.
What does it return? A sortable attentionIndex (0-100), a watchStatus, whyNow reasons, a recommendedAction, and the full substrate fields a standard Reddit scraper emits.
How much does it cost? $0.002 per record ($2 per 1,000) plus $0.20 per monitor or search query. The signal layer is included; monitoring adds no extra per-record cost.
Is it deterministic? Yes. Sentiment and themes use a fixed lexicon and TF-IDF, so every run reproduces byte-identical results.
Reddit Scraper at a Glance
Quick facts:
- Input: a brand or keyword (
track), subreddits (communities), post URLs, usernames, or a search query. - Output:
attentionIndex,watchStatus,whyNow,recommendedAction, plus full substrate fields (title,url,upVotes,numberOfComments,communityName,body). - Pricing: $0.002 per record; $0.20 per monitor/search query.
- Batch size: up to 1,000 records per run (Reddit's platform-wide list cap; use scheduled monitor runs to capture beyond it incrementally).
- Modes: monitor, communities, posts, users, search.
- Output profiles: signals (default), compat (drop-in substrate), agent (compact decisions), minimal (IDs only).
- Determinism: every result re-runs byte-identical (no external LLM).
- Compliance: public-content-only, no login, no in-Reddit actions.
Input -> Output:
- Input: a brand, keyword, subreddit, post URL, username, or search query.
- Process: scrape public Reddit, detect typed signals, score, rank, and (in monitor mode) diff against persisted state.
- Output: a ranked attention queue of decision-ready records plus a run summary.
Best fit: brand and product mention tracking, PR issue detection, trend and topic discovery, community momentum research, search reranking, drop-in migration from a row scraper. Not ideal for: logged-in or private content, real-time webhook alerting (use scheduling), brand-safety or toxicity scoring, write actions on Reddit. Does not include: in-Reddit actions, private content, cross-community propagation mapping, LLM-generated prose.
Problems this solves:
- How to track brand mentions across Reddit without reading every row.
- How to catch a brewing PR issue on Reddit before it blows up.
- How to find emerging Reddit topics and shifting opinion.
- How to know what changed on Reddit since your last check.
Data trust: all data is scraped from public Reddit. Delta, trajectory, and memory fields are maturity-gated and stay null or building until enough scheduled runs accumulate. The actor never fabricates history; the coverage and historicalProfile blocks state exactly how much it knows.
Best fit / Less suitable
Best fit:
- Brand and social teams running a daily mention-tracking feed across several subreddits.
- PR and comms teams that need a sentiment shift or mention spike surfaced early, with evidence.
- Researchers and trend scouts watching topic surges and community acceleration over weeks.
Less suitable:
- Reading private, deleted, or quarantined content. Reddit Scraper reads public content only.
- Real-time second-by-second alerting. Schedule monitor runs instead (daily or hourly).
- Judging whether a post is "problematic."
contested_threadis a descriptive engagement-divergence signal, not a controversy or safety call.
Scope disclaimer: Reddit Scraper is a read-only public-monitoring actor. It does not perform any in-Reddit action, and it does not score brand safety or toxicity. (Field-by-field definitions are in the Definitions section below.)
What is a Reddit monitoring tool?
A Reddit monitoring tool watches Reddit over time for changes that matter to you (mentions, sentiment, emerging topics) and tells you what needs attention, rather than just exporting rows. Most Reddit actors on the Store stop at extraction; Reddit Scraper adds the interpretation, ranking, and run-over-run state that turns a scrape into a monitoring feed.
Why Reddit monitoring is hard
Reddit monitoring is harder than it looks, which is why most tools stop at extraction:
- Reddit lists cap at roughly 1,000 items, so a single scrape can silently miss the rest.
- Communities behave differently. A spike that matters in a 20k-member subreddit is noise in a 2M-member one.
- Viral spikes create noisy false positives. One crosspost duplicated across communities looks like a trend.
- Sentiment shifts are usually gradual, not a single dramatic post, so they hide in the row dump.
- Most tools forget every prior run completely, so they can never tell you whether something is recurring or structural.
Reddit Scraper solves these with community-relative baselines, deterministic scoring, duplicate-crosspost suppression with a trust audit, and persistent operational memory that accumulates state across scheduled runs. That last piece is why a competitor cannot replicate the output by scraping the same data tomorrow.
Common Reddit monitoring problems
Reddit exports too many rows
Traditional Reddit scrapers export thousands of rows with no prioritisation. Reddit Scraper returns a ranked attention queue instead, so the first rows are the ones worth opening.
Reddit sentiment changes slowly
Most Reddit issues emerge gradually across comments and communities, not in one dramatic post. Reddit Scraper tracks sentiment shifts across runs and surfaces the trend before it is obvious.
Reddit spikes create false positives
Crossposts and viral reposts duplicate the same content across communities and look like a trend. Reddit Scraper suppresses duplicate-crosspost artifacts and exposes exactly what it ignored in trustDiagnostics.
Most monitoring tools forget prior runs
A one-shot scrape cannot tell you whether an issue is new or recurring. Reddit Scraper persists operational memory per watchlist, so recurring narratives and structural issues are detected over time via persistentSignal and narrativeMemory.
What data can you extract?
| Data Point | Source | Availability | Example |
|---|---|---|---|
| Post title | Public post | Always | "Notion just changed its pricing again" |
| Up votes | Public post | Always | 1,842 |
| Number of comments | Public post | Always | 326 |
| Community name | Post / community | Always | r/Notion |
| Comment body | Public comment | When comments sampled | "The new plan is way too expensive" |
| User karma | Public profile | Users mode | postKarma 4, commentKarma 10 |
| Attention index | Computed | signals profile | 78 |
| Watch status | Computed | signals profile | attention-required |
| Why now | Computed | signals profile | "Upvote velocity 9x baseline within 12h" |
| Comment sentiment | Computed (deterministic) | When comments sampled | positive 0.41, negative 0.33 |
| Comment themes | Computed (deterministic) | When comments sampled | Pricing complaints (weight 0.34) |
| Signal profile | Computed | Community records | emerging |
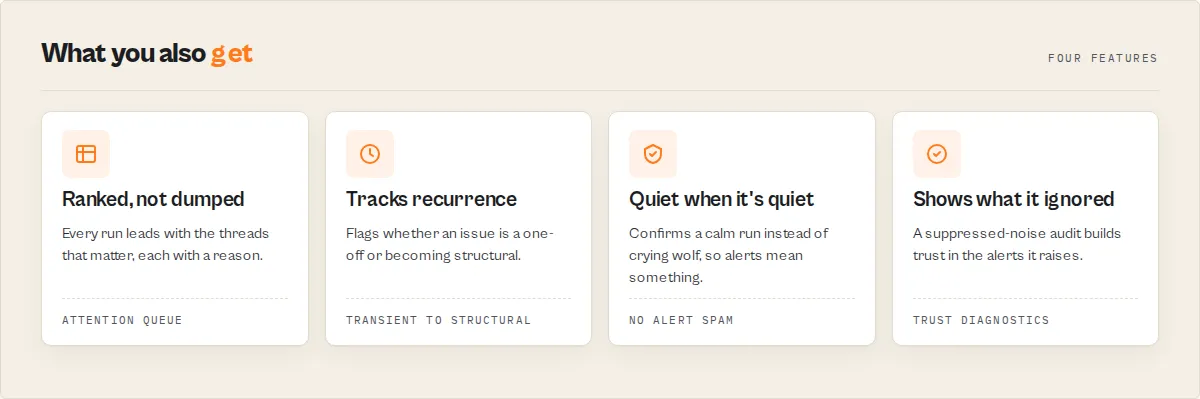
Why use Reddit Scraper?
Before: scraping Reddit for brand mentions ends the same way for every team: a spreadsheet, read row by row, sentiment eyeballed by hand, every day. The bottleneck in 2026 is not getting Reddit data, it is operationalising it fast enough.
Reddit Scraper closes that gap in one run. Instead of 2,000 rows you triage by hand, you get the threads that need attention now, ranked, with a reason and a recommended action on each. The real competitor here is not another scraper; it is the spreadsheet workflow that sits downstream of one.
Key difference: a plain Reddit scraper hands you rows and stops. Reddit Scraper hands you decisions and remembers what it told you last run.
The monitoring workflow, step by step. A row scraper does step one and leaves the rest to you:
| Workflow step | Standard Reddit scraper | Reddit Scraper |
|---|---|---|
| Scrape posts and comments | Yes | Yes |
| Detect breakout threads | Manual | Automatic |
| Detect sentiment shifts | Manual | Automatic |
| Rank what matters | Manual | Automatic |
| Compare against prior runs | Manual | Automatic |
| Suppress duplicate-crosspost noise | Manual | Automatic |
| Build persistent memory of recurring issues | Impossible | Built in |
| Read thousands of rows by hand | Required | Replaced |
The grounded feature comparison against the incumbent:
| Feature | Reddit Scraper | trudax/reddit-scraper-lite |
|---|---|---|
| Public Reddit substrate (posts, comments, communities, users) | Yes | Yes |
Ranked attention queue (attentionIndex) | Yes | Not a feature |
| Mention spike + sentiment shift detection | Yes | Not a feature |
| Deterministic comment sentiment + theme synthesis | Yes (no LLM) | Not a feature |
| Breakout + topic-surge detection | Yes | Not a feature |
| Persistent monitoring state across runs | Yes | Not a feature |
Search reranking (breakoutPotential, momentum) | Yes | Native sort only |
| Drop-in compatible input + substrate fields | Yes (compat profile) | n/a |
| Per-result price | $0.002 / record ($2 / 1k) | |
| Free-tier headroom ($5 credits) | ~2,500 records | ~1,250 results |
Pricing and features based on publicly available information as of May 2026 and may change. Re-verify the incumbent's live price before relying on the comparison.
Unlike a row scraper, which is built to export everything and let you sort it out, Reddit Scraper is built for automation-first monitoring workflows where the first rows are the ones that matter.
Platform capabilities
- Scheduling — run monitor mode daily or hourly with the same
watchlistNameto build a persistent Reddit feed. - API access — trigger from Python, JavaScript, or any HTTP client via the Apify API.
- Proxy rotation — Apify residential proxies by default, with conservative rate limits and a circuit breaker on consecutive blocks.
- Monitoring — Slack or email alerts when runs fail, via Apify integrations.
- Integrations — Zapier, Make, Google Sheets, webhooks, and MCP/agent consumers via the
agentoutput profile.
The five modes
Each mode produces one buyer-facing outcome.
| Mode | One-line outcome |
|---|---|
| monitor (hero) | "These Reddit threads about your brand need attention right now." Track a brand or keyword over time; name a watchlist to build a feed of only what changed. |
| communities | "These subreddits, ranked by what's heating up." Scan communities, each tagged with a signal profile. |
| posts | "Here's what's notable about each thread." Analyse post URLs; each carries whyThisMatters plus comment-theme synthesis. |
| users | "This author is gaining momentum." Surface posting and karma velocity per user. |
| search | "Of 500 posts matching this query, these 4 are popping." Rerank search results by breakout potential, momentum, or attention. |
Reddit Monitoring Features
Reddit Scraper layers a deterministic signal engine and a persistent state engine on top of a drop-in Reddit substrate. Signals are typed and evidenced, scoring is bounded so no single component dominates, and every version constant is pinned so a run is reproducible and auditable.
Signal detection
- Eight typed signal events —
breakout_post,community_acceleration,community_deceleration,topic_surge,sentiment_shift,mention_spike,author_emergence,contested_thread. Each carriessignalStrength(heuristic 0-1),evidenceGrade(weak/moderate/strong), adecayStatus(fresh/active/fading/expired), and anevidenceobject with the underlying z-scores and windows. - Eight community signal profiles —
emerging,breakout,stable-authority,viral-fragile,high-engagement-niche,decelerating,dormant,unclassified, with strength and plain-English evidence. - Suppressed signals — signals that fired but were judged noise are surfaced with a reason and a
noiseRisk, never silently dropped, so you can see what the actor ignored across communities.
Decision and routing
- attentionIndex (0-100) — the single sortable composite, with a
breakdownaudit trail and top-3 paste-readydrivers. - watchStatus — the routing primitive to branch on (
no-action,monitor,attention-required,urgent,critical). - whyNow + recommendedAction — plain-English reasons plus a prioritisation instruction (Review, Read, Monitor, Track, Re-check, Compare, Investigate), never an in-Reddit engagement instruction.
- agentContract + agentDecision — a compact decision surface (
review_now/monitor/ignore) for MCP, AI-agent, and RAG consumers.
Comment intelligence (deterministic, no LLM)
- Sentiment — positive/negative/neutral with a
confidenceBandthat scales with sample size, via a fixed lexicon. - Themes — TF-IDF clustering mapped to a fixed theme dictionary (stable
themeCodeenum), with keywords and example comment IDs.
Persistent state (monitor mode)
- signalTrajectory — direction, velocity, stability, phase, and
trajectoryClassin one block. Maturity-gated tounknownuntil 3+ runs. - persistentSignal — recurrence classification (
transient,recurring,persistent,cyclical,dormant) from accumulated state. - narrativeMemory — cross-run topic memory with historical peaks and cycle length; advanced fields stay
nulluntil enough cycles exist. - stateTransition + changeFlags — what changed since the last run (
NEW_BREAKOUT,MENTION_SPIKE,SENTIMENT_DOWN,SIGNAL_EXPIRED).
Run summary and trust
- dailyBriefing + portfolioState — a morning brand-monitoring surface and a CIO-glance over the run.
- runOutcome — a quiet-mode status (
quiet/active/high-activity) so a monitor that says "nothing fired" is trusted when it does fire. - coverage — requested vs scanned communities, typed skip reasons, and a
coverageStatus. - publicDataCompliance — a machine-readable read-only posture with
inRedditActionsPerformedhard-wired tofalse. - trustDiagnostics + runManifest — suppression counts, dedup counts, coverage confidence, and every pinned version constant for audit.
Use cases for Reddit monitoring
Reddit monitoring for product marketing
Use when you need to know how Reddit is talking about your product this week. Set mode: monitor, put your brand in track, name a watchlistName, and schedule daily. PMM teams use Reddit Scraper to surface mention spikes and recurring complaint narratives without reading every thread. Key outputs: attentionIndex, whyNow, signalEvents, commentIntelligence.
Reddit monitoring for PR teams
Use when a brewing issue needs to be caught before it blows up. Set persona: pr-comms so sentiment shifts and mention spikes escalate immediately, with evidence on each. Key outputs: watchStatus, attentionWindow, signalTrajectory, changeFlags.
Reddit monitoring for researchers and trend scouts
Use when you are scouting which topics or communities are accelerating before they are obvious. Set persona: trend-research and rankBy: breakoutPotential. Key outputs: signalProfile, topic_surge events, communityHealth, narrativeConcentration.
Reddit monitoring for competitor analysis
Use when you track how a community discusses rivals over time. Schedule monitor runs and read the run-over-run delta to see what shifted. Key outputs: signalTrajectory, persistentSignal, stateTransition, portfolioState.
Reddit monitoring for investors and scouts
Use when you want to spot a community or product narrative accelerating early. Schedule weekly monitor runs on a watchlist; signalTrajectory and persistentSignal tell you whether momentum is building or fading and whether an issue is recurring. Key outputs: signalTrajectory, persistentSignal, narrativeMemory, communityHealth.
Reddit monitoring for AI agents and RAG pipelines
Use when an agent or pipeline needs Reddit content with quality and sentiment signals attached. Set outputProfile: agent for a compact, deterministic decision surface, or signals for the full envelope. Key outputs: agentContract, commentIntelligence, attentionIndex, materiality.
When to use Reddit Scraper
Best for:
- Daily brand monitoring across 5-10 subreddits with a named watchlist.
- Weekly trend and competitor research that compares against the prior run.
- Search reranking across hundreds of results to surface what is popping.
- Migrating an existing Reddit-scraper workflow to a cheaper, signal-rich substrate.
Not ideal for:
- Logged-in or private content. Reddit Scraper reads public content only.
- Real-time alerting. Schedule monitor runs (hourly or daily) instead.
- Brand-safety or toxicity scoring. Use a dedicated content-moderation tool.
How to monitor a brand on Reddit
- Enter your brand or keyword — set
modetomonitorand add your term totrack, for example["Notion"]. Add subreddits incommunitiesto focus the scan. - Configure options — name a
watchlistNameto persist state across runs (leave empty for a one-shot run). Defaults cover most cases:rankBy: attention,persona: brand-monitoring. - Run the actor — click Start. A single-brand monitor run returns first results in about 60 seconds.
- Download results — open the Attention Queue view, or export JSON, CSV, or Excel from the Dataset tab.
First run tips
- Start with the monitor demo — leave the fields at their defaults to run the built-in
track: ["Notion"]example and see the attention queue before pointing it at your own brand. - Run 1 will not show deltas —
historicalProfilereportsfirst-runand delta arrays are empty by design. Schedule a second run with the samewatchlistNameto start the memory clock; it cannot be backfilled. - Turn on comment sampling for sentiment — set
includeCommentsSample: trueto unlockcommentIntelligence(sentiment shift detection needs sampled comments). - Name your watchlist — without
watchlistName, the run is one-shot with no persistence and no delta intelligence. - Test small — keep
maxResultslow (for example 50) for your first run before scaling up.
Typical performance
Observed in internal testing (May 2026, small sample). Reddit is rate-limited and client-rendered, so figures vary by mode, depth, and proxy conditions.
| Metric | Typical value |
|---|---|
| Records per run | up to 1,000 (Reddit list cap) |
| Run time (single-brand monitor) | ~60-120 seconds |
| Run time (multi-community deep scan) | several minutes |
| First result latency | ~60 seconds |
| Cost per 1,000 records | $2.00 + $0.20 per query |
Input parameters
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
mode | string | No | monitor | Entry point: monitor, communities, posts, users, search. |
track | array | No | ["Notion"] | Monitor mode: brand names or keywords to track across Reddit. |
communities | array | No | [] | Subreddits to scan or monitor (r/Notion, Notion, or a URL). |
posts | array | No | [] | Posts mode: Reddit post permalinks to analyse. |
users | array | No | [] | Users mode: usernames or profile URLs. |
searchQuery | string | No | "" | Search mode: keyword or phrase to search and rerank. |
searchType | string | No | posts | Search mode target: posts, communities, users. |
rankBy | string | No | attention | Ordering axis: attention, breakoutPotential, momentum, engagement, recency, relevance. |
watchlistName | string | No | "" | Name a watchlist to persist state across runs and unlock delta intelligence. |
deltaWindowDays | integer | No | 7 | Window for run-over-run change detection. |
persona | string | No | brand-monitoring | Reshapes materiality weights: brand-monitoring, trend-research, community-discovery, pr-comms, generic. |
includeCommentsSample | boolean | No | false | Sample comments and run deterministic theme + sentiment synthesis. |
commentsSamplePerPost | integer | No | 100 | Comments sampled per post (raises sentiment confidence band). |
outputProfile | string | No | signals | signals (full), compat (drop-in substrate), agent (compact decisions), minimal (IDs only). |
analysisDepth | string | No | standard | Coverage/runtime tradeoff: fast, standard, deep. |
explainability | string | No | standard | Verbosity: standard (decision surface) or full (all evidence blocks). |
maxResults | integer | No | 100 | Hard cap on records emitted (max 1,000). |
maxPostsPerCommunity | integer | No | 100 | Per-community post cap. |
maxRecentItems | integer | No | 50 | Users mode: recent posts/comments per user. |
sort | string | No | hot | Reddit listing/search sort. |
time | string | No | month | Time window for top/search sorts. |
includeNSFW | boolean | No | false | Include over-18 communities/posts. |
maxRuntimeSeconds | integer | No | 3600 | Runtime budget; emits partial results plus a summary before timeout. |
startUrls | array | No | [] | Compatibility alias: paste post/user/community URLs from an existing workflow. |
searches | array | No | [] | Compatibility alias for keyword search. |
searchCommunityName | string | No | "" | Compatibility alias: restrict search to one community. |
proxyConfiguration | object | No | residential | Proxy settings; residential recommended for Reddit. |
Input examples
- Monitor a brand (hero):
{ "mode": "monitor", "track": ["Notion"], "rankBy": "attention" } - Daily brand feed with persistence:
{ "mode": "monitor", "track": ["Notion", "Obsidian"], "communities": ["r/productivity", "r/Notion"], "watchlistName": "notion-brand", "deltaWindowDays": 7, "persona": "pr-comms", "includeCommentsSample": true } - Drop-in migration (compat):
{ "startUrls": [{ "url": "https://www.reddit.com/r/Notion/" }], "outputProfile": "compat", "maxResults": 200 }
Input tips
- Start with defaults — the default monitor mode covers most first runs.
- Name a watchlist for monitoring —
watchlistNameis what unlocks delta intelligence; without it the run is one-shot. - Use the compat profile to verify migration —
outputProfile: compatreturns the exact substrate field set with no signal fields. - Sample comments for sentiment —
includeCommentsSample: trueis required for sentiment shift detection.
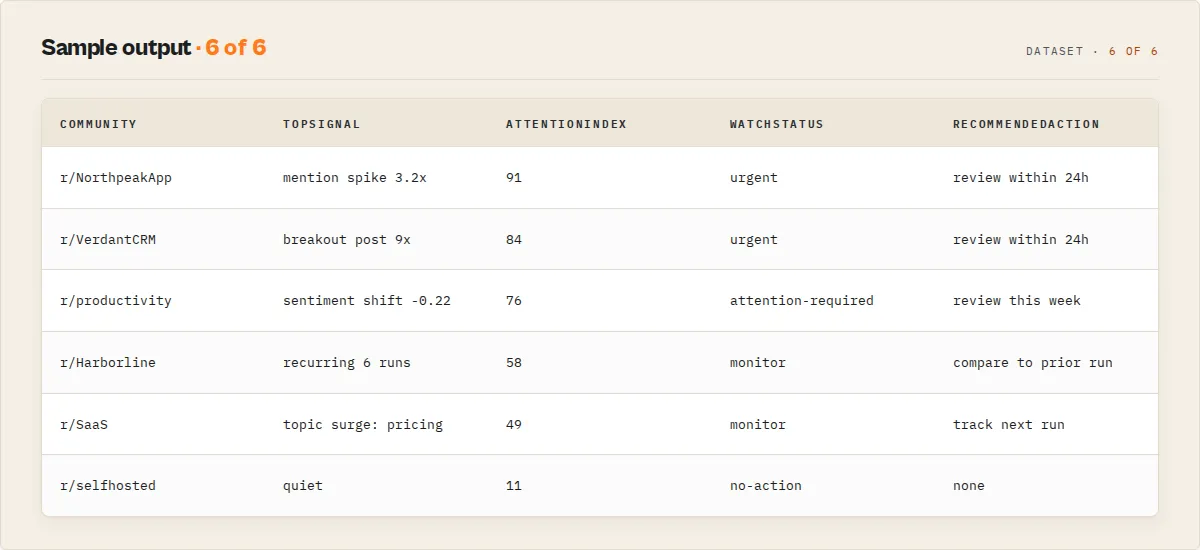
Output example
Definitions
- Attention queue — a ranked list of Reddit threads ordered by operational importance, not by date or raw upvotes.
- Attention index — a bounded 0-100 composite score for how worth reviewing a Reddit thread is right now.
- Watch status — the routing state for a record:
no-action,monitor,attention-required,urgent, orcritical. - Persistent operational memory — cross-run Reddit monitoring state that accumulates over time and cannot be reconstructed from a single scrape.
- Signal trajectory — whether a narrative is accelerating, rising, stable, fading, or volatile.
- Persistent signal — a recurring signal classified as transient, recurring, persistent, cyclical, or dormant from accumulated history.
- Suppressed signal — a signal that fired but was filtered as noise, surfaced with its reason rather than silently dropped.
Output fields
| Field | Type | Description |
|---|---|---|
schemaVersion | string | Output schema version (additive-only). Pin automations to this. |
recordType | string | Discriminator: post, comment, community, user, search_result, summary, error. |
eventId | string | Stable dedup key (native Reddit fullname, or syn_ sha256 for synthetic records). |
attentionIndex | object | The single sortable composite (0-100) with breakdown and top-3 drivers. |
watchStatus | string | Routing primitive: no-action, monitor, attention-required, urgent, critical. |
whyNow | array | Plain-English reasons this record needs attention now. |
recommendedAction | string | Prioritisation instruction (never an in-Reddit engagement instruction). |
attentionWindow | object | Machine primitive: urgency plus recommendedReviewWithinHours. |
agentDecision | string | Flat decision enum: review_now, monitor, ignore. |
agentContract | object | Compact decision surface for MCP/AI/RAG consumers. |
signalEvents | array | Typed, evidenced events with signalStrength, evidenceGrade, decayStatus. |
signalProfile | string | Community archetype (8-value enum). |
whyThisMatters | array | Per-post operational notes (posts mode). |
commentIntelligence | object | Deterministic sentiment + themes (lexicon-tfidf-v1). |
actionability | number | 0-1: how worth acting on now. |
materiality | number | 0-100: how much this matters to the tracked term/persona. |
signalTrajectory | object | State backbone: direction, velocity, stability, phase, class. |
persistentSignal | object | Recurrence classification from accumulated state. |
narrativeMemory | object | Cross-run topic memory (maturity-gated). |
suppressedSignals | array | Signals judged noise, with reason and noiseRisk. |
coverage | object | Requested vs scanned communities, skip reasons, status (summary record). |
publicDataCompliance | object | Read-only posture; inRedditActionsPerformed hard-wired false (summary record). |
runOutcome | object | Quiet-mode status: quiet, active, high-activity (summary record). |
portfolioState | object | CIO-glance over the run (summary record). |
trustDiagnostics | object | Suppression, dedup, and coverage confidence (summary record). |
title, url, upVotes, numberOfComments, body, communityName, dataType | mixed | Substrate fields, identical name and type to a standard Reddit scraper (compat). |
How much does it cost to monitor Reddit?
Reddit Scraper uses pay-per-event pricing — you pay $0.002 per record ($2 per 1,000) plus $0.20 per monitor or search query. The signal layer is included, and monitor runs cost the same per record as one-shot runs. Platform compute costs are included.
| Scenario | Records | Cost per record | Query cost | Total cost |
|---|---|---|---|---|
| Quick test | 50 | $0.002 | $0.20 | $0.30 |
| Small batch | 200 | $0.002 | $0.20 | $0.60 |
| Daily brand feed | 500 | $0.002 | $0.20 | $1.20 |
| Large pull | 1,000 | $0.002 | $0.20 | $2.20 |
| Heavy monitoring | 10,000 | $0.002 | $2.00 (10 queries) | $22.00 |
That is roughly half the effective per-result cost of a standard row scraper, with the signal layer included. Apify's free tier ($5 monthly credits) runs about 2,500 records here. Set a spending limit on the actor to cap costs.
Monitor Reddit using the API
All three examples use the same input — the canonical monitor call { "mode": "monitor", "track": ["Notion"], "rankBy": "attention" }.
Python
JavaScript
cURL
The run response's defaultDatasetId is then fetched from /v2/datasets/{id}/items.
Why deterministic Reddit monitoring matters
Most "AI-powered" monitoring tools generate different outputs from the same Reddit data on different runs, because an LLM sits in the scoring path. Reddit Scraper uses deterministic sentiment and theme synthesis (lexicon-tfidf-v1):
- the same comments always produce the same sentiment and themes
- signals are reproducible and the scoring is auditable
- outputs are stable across runs, so automation can branch on them safely
- there is no external LLM dependency and no probabilistic drift
That makes it suitable for operational monitoring, compliance-sensitive environments, AI pipelines that need stable inputs, and any automation that branches on the output. Unlike tools that paraphrase Reddit through a model, Reddit Scraper's numbers mean the same thing every run.
How Reddit Scraper works
Mental model: Reddit -> substrate fetch -> signal detection -> state engine -> decision -> ranked attention queue.
| Layer | What happens |
|---|---|
| 1 Extraction | Scrape public posts, comments, communities, users (the compat substrate). |
| 2 Interpretation | Detect typed signal events with evidence and a decay status. |
| 3 State engine | Diff against persisted watchlist state; compute trajectory, persistence, memory. |
| 4 Decision | Compute attentionIndex, watchStatus, agentDecision, attentionWindow. |
| 5 Portfolio | Roll up portfolioState, narrativeConcentration, trustDiagnostics over the run. |
Signal detection
After the substrate fetch, deterministic detectors fire against community baselines. A breakout_post needs an upvote z-score at or above 2 within 48 hours; a mention_spike needs current-window volume at or above 2x baseline; a sentiment_shift needs a delta magnitude at or above 0.15 on a 100+ comment sample. Thresholds are pinned to signalDetectionVersion: 1.0.
Comment intelligence
Comments are tokenised, stopword-stripped, scored with TF-IDF, clustered by term co-occurrence, and mapped to a fixed theme dictionary. Sentiment uses the VADER lexicon. There is no external LLM, so the same comments produce the same themes every run.
State engine (the moat)
When a watchlist is named, per-term and per-community history accumulates in a separate named key-value store (reddit-monitor-<name>). Trajectory, recurrence, and topic memory are derived from that history. The maturity model is honest: advanced fields stay null or building until enough runs exist.
Tips for best results
- Schedule the same watchlist daily. The product is the run-over-run delta; one run cannot show what changed.
- Pick the persona that matches your job.
pr-commsescalates sentiment and mention spikes;trend-researchescalates topic surges and community acceleration. - Use
rankByto change the lens.breakoutPotentialfor scouts,attentionfor monitoring,momentumfor trend acceleration. - Filter on
watchStatus, not raw scores. Branch automation onWHERE watchStatus IN ('urgent','critical'). - Read the Suppressed Signals view. Seeing what the actor ignored, and why, builds trust in the alerts it raises.
- Use
outputProfile: agentfor AI consumers. It returns a compact decision surface for MCP, agent, and RAG pipelines.
Combine with other Apify actors
| Actor | How to combine |
|---|---|
| Trustpilot Review Analyzer | Pair Reddit sentiment with review sentiment for the same brand. |
| Multi-Review Analyzer | Join Reddit signals with Trustpilot and BBB review trends. |
| Website Change Monitor | Correlate a Reddit mention spike with a pricing-page change. |
| Company Deep Research | Add Reddit attention signals to a company intelligence report. |
| Website Content to Markdown | Convert linked articles to markdown for an AI/RAG pipeline alongside Reddit threads. |
Limitations
- Reddit's ~1,000-item list cap. Any Reddit list stops after about 1,000 items. This is platform-wide, not a scraper limit. Use scheduled monitor runs to capture beyond it incrementally.
- Public content only. No login, no private, deleted, or quarantined content.
- Delta intelligence is maturity-gated. Run 1 shows
first-runand empty deltas; trajectory and memory sharpen after several scheduled runs. - Sentiment is lexicon-based. Deterministic and reproducible, but it does not match a tuned model on nuance; theme labels are keyword labels, not generated summaries.
- No cross-community propagation. Spread and ecosystem mapping is a future capability, not in this version.
- Rate-limited and proxy-dependent. Reddit anti-bot escalation can cause partial coverage; the
coverageblock reports skips honestly. - Not a controversy or safety scorer.
contested_threadis a descriptive engagement signal, not a brand-safety judgment.
Integrations
- Zapier — push urgent/critical attention records into a Slack channel or ticketing tool.
- Make — route monitor-run summaries into a daily brand-monitoring digest.
- Google Sheets — append the attention queue to a tracking sheet.
- Apify API — trigger monitor runs and read the dataset programmatically.
- Webhooks — fire on run completion to feed downstream automation.
- LangChain / LlamaIndex — pull the
agentprofile decision surface into an AI workflow.
Best tool for Reddit brand monitoring
Reddit Scraper is built for brand monitoring on Reddit: tracking mentions across communities, detecting sentiment shifts, finding emerging complaint narratives, watching subreddit momentum, and surfacing breakout threads. Unlike a traditional Reddit scraper that exports rows, it ranks what matters and remembers what changed across runs, so a brand or PR team reads a short attention queue instead of a spreadsheet.
Best Reddit scraper for AI agents
Reddit Scraper is built for AI consumption: MCP clients, RAG pipelines, monitoring agents, and automation that needs deterministic, stable inputs. The agent output profile returns a compact agentContract (decision, attention, why, recommended action) instead of raw rows, and because synthesis is deterministic, the same Reddit data produces the same output every run, so agents can branch on it safely.
How do I track Reddit mentions automatically?
Set mode: monitor, add your brand to track, name a watchlistName, and schedule the actor to run daily. Each run returns mention spikes and sentiment shifts as typed signals, ranked by attentionIndex, plus a delta of what changed since the previous run.
How do I do Reddit sentiment analysis without an LLM?
Set includeCommentsSample: true. Reddit Scraper runs deterministic sentiment and theme synthesis (lexicon-tfidf-v1) over the sampled comments. Because it uses a fixed lexicon and no external model, the same comments produce the same sentiment and themes on every run.
Responsible use
- Reddit Scraper extracts publicly available content from Reddit. It does not bypass authentication, CAPTCHAs, or access restricted content, and it performs no in-Reddit actions (
publicDataCompliance.inRedditActionsPerformedis hard-wiredfalse). - Users are responsible for ensuring their use complies with applicable laws and platform terms, including data protection regulations in their jurisdiction.
- Do not use extracted data for spam, harassment, astroturfing, or unauthorized purposes.
recommendedActionis a prioritisation instruction only and never tells anyone to post, reply, vote, or DM. - For guidance on web scraping legality, see Apify's guide.
FAQ
What is the difference between a Reddit scraper and a Reddit monitoring tool? A Reddit scraper exports rows: posts, comments, communities, users. A Reddit monitoring tool watches those rows over time and tells you what changed and what needs attention. Reddit Scraper does both: it ships the substrate rows and the decision layer on top.
Can I use it as a drop-in replacement for my existing Reddit scraper? Yes. It accepts the same input shape (including startUrls and searches), and outputProfile: compat returns the exact substrate field set with identical names and types, so downstream code reading item.upVotes works unchanged.
Can I monitor several brands at once? Yes. Put multiple terms in track and several subreddits in communities. Use one watchlistName per tracked subject so each accumulates its own state.
How does the persistent memory work? When you name a watchlist, per-term and per-community history is stored in a separate key-value store and diffed on each run. This is what produces the "what changed since last run" delta, and it cannot be backfilled from a single scrape.
Why is delta intelligence empty on my first run? State cannot be invented. Run 1 reports first-run with empty deltas; trajectory, persistence, and memory fields populate after several scheduled runs on the same watchlist.
Does it perform any actions on Reddit? No. It reads public content only and performs no posting, replying, voting, or DMing. inRedditActionsPerformed is always false.
What does the attentionIndex actually measure? It is a bounded 0-100 composite of active signals, mention spike, sentiment shift, breakout strength, and community momentum, with no single component allowed to dominate. The breakdown and drivers show how it was built.
How accurate is the sentiment? Sentiment is deterministic and lexicon-based, with a confidenceBand that scales with sample size. It is reproducible and auditable rather than a probabilistic model output; a 12-comment thread reads low, a 200-comment thread reads high.
Can I use this with an AI agent or MCP? Yes. Set outputProfile: agent for a compact agentContract decision surface, or read the flat agentDecision enum (review_now / monitor / ignore).
How is this a practical alternative to a row scraper for brand monitoring? A row scraper leaves the monitoring, ranking, and sentiment work to you. Reddit Scraper ships those as the product, at roughly half the per-result cost, so the workflow that used to live in a spreadsheet runs in one call.
Is it legal to scrape Reddit? Reddit Scraper accesses public content only and performs no write actions. Whether your use is permitted depends on your jurisdiction and intended use, including data protection and platform terms. Consult legal counsel for your specific case.
What happens when nothing is happening? The summary record returns runOutcome.status: "quiet" with a clear message. A monitor that is willing to say "nothing fired" is the one you trust when it does fire.
Help us improve
If you encounter issues, you can help us debug faster by enabling run sharing in your Apify account:
- Go to Account Settings > Privacy
- Enable Share runs with public Actor creators
This lets us see your run details when something goes wrong, so we can fix issues faster. Your data is only visible to the actor developer, not publicly.
Support
Found a bug or have a feature request? Open an issue in the Issues tab on this actor's page. For custom solutions or enterprise integrations, reach out through the Apify platform.
