B2B Growth Signal Finder
Pricing
from $2.40 / 1,000 growth-signal-results
B2B Growth Signal Finder
Enrich company domains with public hiring, website, and growth signals - careers pages, open-role counts, demo/pricing/contact CTAs, expansion indicators, and a transparent 0-100 growth score. No login or cookies.
Pricing
from $2.40 / 1,000 growth-signal-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share

Enrich a list of company domains or website URLs with public hiring, website, and growth signals — careers pages, open-role counts, demo/pricing/contact CTAs, partner/case-study/location pages, and expansion keywords — then score each company with a transparent, non-AI 0–100 growth signal score. Built for B2B sales teams, lead-gen agencies, recruiters, and market researchers who want to prioritise outreach by visible buying-intent and growth.
No login, no cookies, no sessions. The actor fetches each company's public homepage and a few shallow-discovered key pages over HTTP. You pay one flat event per unique company row that passes your filters.
✨ Why this scraper
- Company-level, signal-first — one flat row per company, focused on actionable growth indicators, not raw contact scraping.
- Two input modes — paste full company URLs or bare domains; both are normalized to a root domain.
- 27 flat fields — identity, hiring signals, website/buying-intent signals, and a transparent score. No nested objects; drops straight into Sheets/Excel/CRMs.
- Transparent rule-based score — every point is explained by reason tags (no AI, no black box).
- Cheap & compliant — public pages only, no login-only platforms, no expensive enrichment APIs, no email/contact scraping.
- Pay-Per-Event — one flat
growth-signal-resultevent per saved unique company. Duplicates, filtered, and failed rows are never charged.
🚀 Quick start — sample inputs
Example 1 — company URLs with filters
Example 2 — bare domains, homepage-only, tag filter
🧾 Input fields
| Field | Type | Default | Purpose |
|---|---|---|---|
companyUrls | array | [] | Direct company website URLs to enrich |
domains | array | [] | Domain-only inputs (converted to https://<domain>) |
maxResults | integer | 100 | Max saved company rows (1–5000) |
scanMode | string | homepage_plus_key_pages | homepage_only or homepage_plus_key_pages |
maxPagesPerCompany | integer | 5 | Page guardrail (1–10; forced to 1 for homepage_only) |
includeHiringSignals | boolean | true | Detect + scan a public careers/jobs page |
minOpenJobs | integer | 0 | Keep companies with at least N visible open jobs |
minGrowthSignalScore | integer | 0 | Keep companies scoring at least this (0–100) |
requiredSignalTags | array | [] | Keep a company only if it has ≥1 of these reason tags |
deduplicate | boolean | true | Remove duplicate companies by root domain |
proxyConfiguration | object | { "useApifyProxy": true } | Datacenter, no-proxy, or custom proxy URLs |
At least one of
companyUrlsordomainsis required. No field accepts login credentials, cookies, session tokens, or account API keys.
📤 Output — one flat row per company
Results are returned as a flat Growth signals table — one row per company:
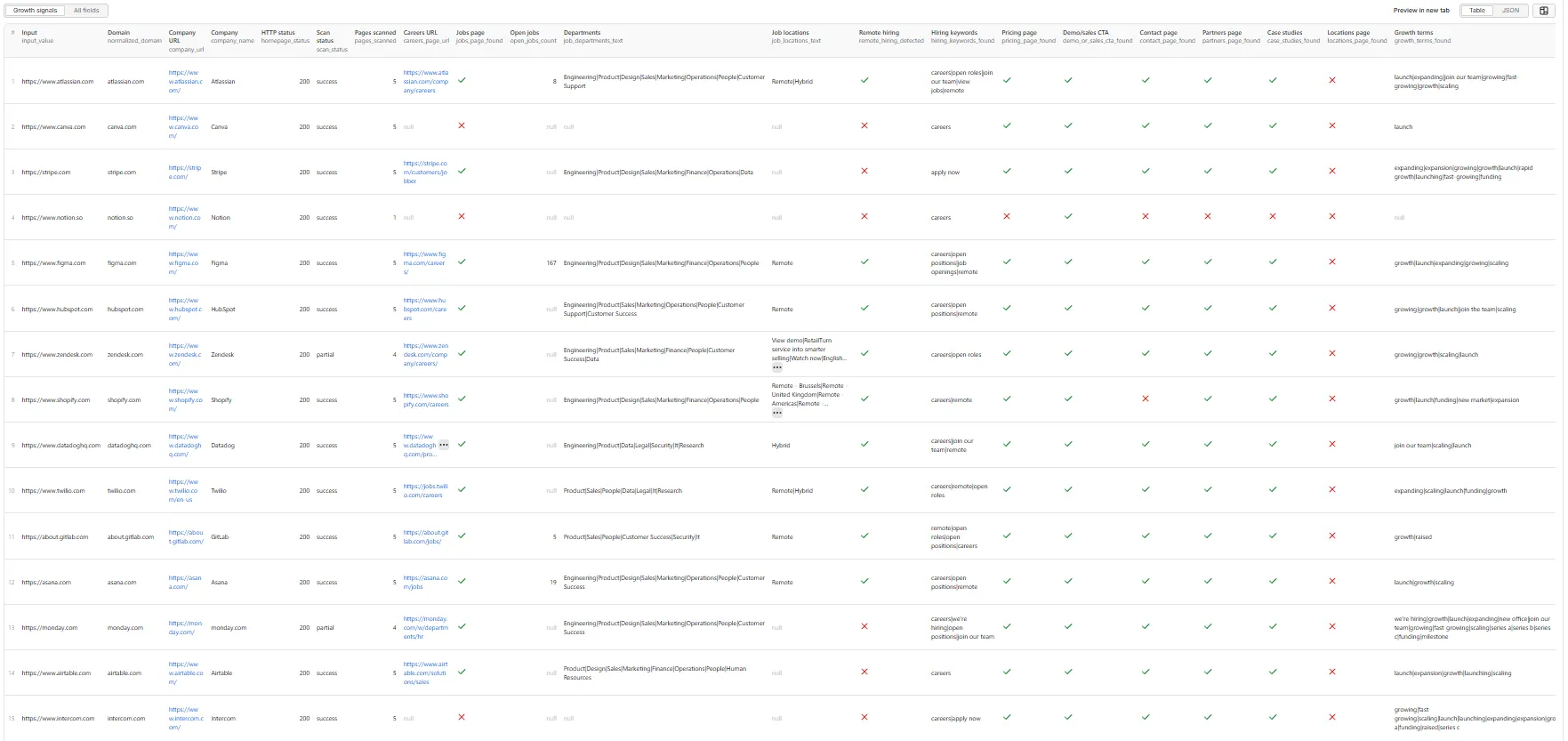
Sample record — strong signal (visible open-role count)
Sample record — careers page found, job count not in static HTML
When a careers page renders its roles only through heavy JavaScript, jobs_page_found stays true but open_jobs_count is null (V1 extracts visible HTML only — it does not run a browser):
Field groups
- Identity / status:
input_value,normalized_domain,company_url,company_name,homepage_status,scan_status(success/partial/failed/filtered),pages_scanned - Hiring signals:
careers_page_url,jobs_page_found,open_jobs_count,job_departments_text,job_locations_text,remote_hiring_detected,hiring_keywords_found - Website / buying-intent signals:
pricing_page_found,demo_or_sales_cta_found,contact_page_found,partners_page_found,case_studies_found,locations_page_found,growth_terms_found - Scoring:
growth_signal_score(0–100),growth_signal_label(low/medium/high/very_high),growth_reason_tags - Provenance:
source_pages,error_message,scraped_at
Booleans default to false, unknown counts to null, text fields to null.
📊 Growth signal score (transparent, no AI)
The 0–100 score is a simple weighted sum, capped at 100:
| Signal | Points |
|---|---|
| Careers/jobs page found | +15 |
| Open jobs: 1–4 / 5–19 / 20–49 / 50+ | +10 / +18 / +25 / +30 |
| Remote/hybrid hiring detected | +8 |
| Multiple job locations | +8 |
| Demo / contact-sales CTA | +8 |
| Growth terms (expanding, hiring, launch, growth…) | +8 |
| Pricing page found | +6 |
| Case studies / customers page | +6 |
| Locations/offices page | +6 |
| Partners page found | +5 |
| Contact page found | +4 |
Labels: 0–24 → low, 25–49 → medium, 50–74 → high, 75–100 → very_high.
Every contribution is recorded in growth_reason_tags (e.g. careers_page_found, active_hiring, large_hiring_volume, remote_hiring, multi_location_hiring, demo_cta_found, pricing_page_found, case_studies_found, partner_page_found, location_expansion_signal, growth_terms_found, contact_page_found).
💸 Pricing — Pay Per Event
One flat growth-signal-result event is charged per valid unique company row successfully pushed to the dataset. Failed inputs, duplicates, and filtered-out rows are never charged. The per-event price is set on the Apify Console. The actor also honours the per-run spending limit you set on Apify — it stops collecting once the limit is reached.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for public company-website crawling at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor will fail at startup if apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~$/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
⚙️ How it works
- Normalize every input URL/domain to a root domain and a candidate HTTPS homepage, deduplicating by domain.
- Fetch the homepage (HTTP-first, no browser). On HTTPS failure the HTTP variant is tried once.
- Discover & classify internal links (careers, about, contact, pricing, solutions, customers, locations, partners) and, in
homepage_plus_key_pagesmode, fetch up tomaxPagesPerCompany - 1high-value pages. - Extract signals — company name, careers/jobs presence + visible open-role count, CTA/page indicators, and growth keywords.
- Score, filter, dedupe, then push valid unique rows and charge per row.
A RUN_SUMMARY object (inputs, saved, duplicates, filtered, charged events, blocked requests, pages scanned, runtime) is stored in the default key-value store.
🚫 Not in V1
Deep crawling, full job-description extraction, contact/email/person enrichment, AI scoring/summarization, LinkedIn or any login-only platform, paid data vendors, historical cross-run tracking.