Facebook Ad Library Scraper
Pricing
from $2.99 / 1,000 results
Facebook Ad Library Scraper
Facebook Ad Library scraper tool: pull every Meta ad by keyword or URL and copy, images, video, CTA, spend & reach. Export to CSV/JSON. All 6 Meta platforms.
Pricing
from $2.99 / 1,000 results
Rating
0.0
(0)
Developer
Thodor
Maintained by CommunityActor stats
1
Bookmarked
41
Total users
7
Monthly active users
3 days ago
Last modified
Categories
Share
Facebook Ad Library scraper tool to pull every Meta ad for a keyword or Ad Library URL — ad copy, images, videos, CTA, landing page, and run dates, plus spend & reach for political/regulated ads. Export as a spreadsheet (CSV / Excel / Google Sheets), JSON, or via API. Covers every ad running on Facebook, Instagram, Messenger, WhatsApp, Audience Network, and Threads.
Each ad comes back as one row with the fields you actually need: page name & profile, ad copy, images, videos, call-to-action, link destination, run dates, publisher platforms, plus spend, reach, and targeting for regulated categories (political/issue/housing/credit/employment ads).
A fast Facebook ads scraper for the whole Meta network: scrape Facebook ads, extract Instagram ads, track WhatsApp / Messenger / Threads / Audience Network placements, spy on competitor creatives, and feed BI tools, lead-enrichment pipelines, or LLM agents with structured Meta ad data.
Built on the Apify platform: residential proxy rotation, scheduling, integrations, full REST API, and dataset export to spreadsheet (CSV, Excel), JSON, HTML, or RSS out of the box.
Why use this Facebook Ad Library scraper?
This Facebook ads scraper turns the public Meta Ad Library into structured, filterable data:
- 🕵️ Competitor intelligence. See exactly what ads competitors are running, in which countries, and how long they've been running.
- 🎨 Creative research. Discover top-performing ad copy, formats, and call-to-actions in your industry.
- 📈 Trend analysis. Sort by total impressions or most recent to spot what's gaining traction.
- ⚖️ Compliance & transparency. Track active political, housing, employment, or credit ads in any jurisdiction (with currency, spend, and reach estimates).
- 🌍 Multi-country coverage. Issue separate searches per ISO country code in a single run.
- 🔗 Influence mapping. Link ads back to the Facebook pages running them, including page-like counts and categories.
- 🧪 Live-tested filters. Every input is verified against Meta's GraphQL endpoint. Most scrapers expose UI options that silently don't work for anonymous browsing; this one doesn't.
How to scrape Facebook Ad Library data
Option A (recommended): Paste a search URL from your browser
This is the simplest workflow and works for 95% of cases. The form prefills with a working example URL, so the very first click of Start returns results.
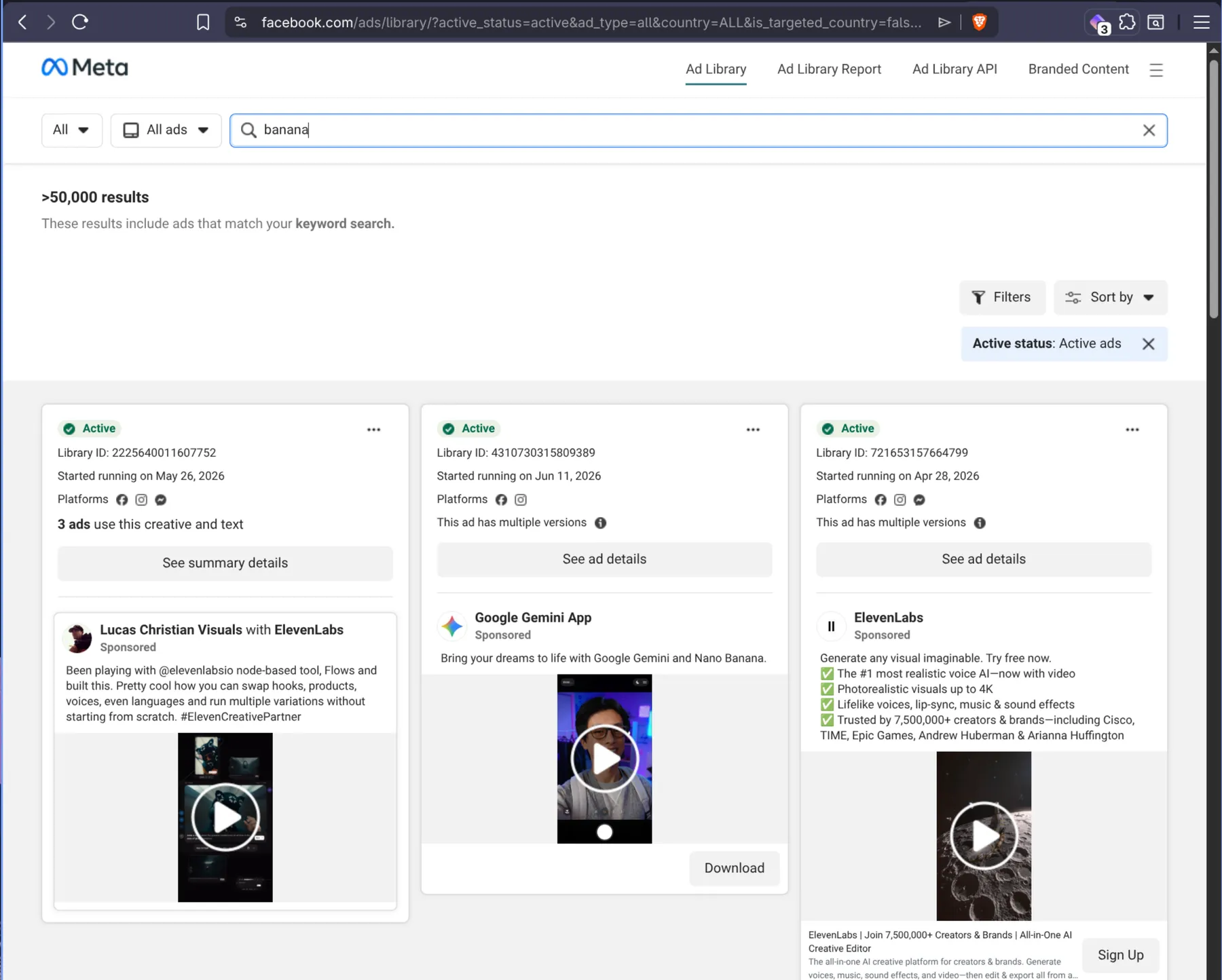
- Visit the Facebook Ad Library and search for ads based on your requirements — keyword, country, ad type (all / political / housing / credit / employment), active status, media type, publisher platform, date range.
- Copy the URL from the browser's address bar. It will look something like this (a search for
bananaads across all countries, biggest spenders first):https://www.facebook.com/ads/library/?active_status=active&ad_type=all&country=ALL&is_targeted_country=false&media_type=all&q=banana&search_type=keyword_unordered&sort_data[direction]=desc&sort_data[mode]=total_impressions - Click the Try for free button at the top of this page.
- Paste the URL into the Ad Library search URLs input. You can add multiple URLs; the actor scrapes them all in sequence and writes a flat
search_urlfield to each row so you can trace results back to their source query. - (Optional) Adjust Max ads per search (default: 100, max: 1,000,000).
- Click the Start button. Results stream into the dataset as ads are found, so you can begin downloading partial results immediately.
- When the run has finished, open the Output tab and click the Export button to download the ads as CSV, Excel, JSON, or HTML.
Option B: Use structured filters (no browser needed)
If you'd rather not paste URLs (e.g. you're templating runs across many keyword × country combinations from a spreadsheet, or wiring this into an automation), open the Structured filters section in the actor input and fill them directly:
- Search terms + Countries: cross-product becomes one search per combination (3 terms × 5 countries = 15 searches in one run).
- Ad category / Active status / Media type / Search type / Sort by / Publisher platforms / Start date from-to: every filter from Facebook's own Ad Library UI is exposed and labelled in plain English.
Click Start — same as Option A.
Option C: Meta Ad Library API (no access token needed)
The actor works as a Meta Ad Library API: callable via the Apify REST API and webhooks with the same input schema as the UI, no Meta access token or app review required, and it returns all ad categories — not just the political ads Meta's official API is limited to in most regions. Useful for scheduled scrapes, lead-enrichment pipelines, n8n / Make / Zapier workflows, and any LLM agent stack. See the actor's API tab in Apify Console for the exact endpoint and example curl calls.
Use case recipes
Here's how to put the Facebook Ad Library scraper to work. Pick the recipe that matches your goal and follow the click-by-click steps. Recipes using Search terms + Countries require opening the Structured filters section in the actor input (or you can paste a URL with those filters baked in).
🎨 Find the highest-performing creatives in your industry
Goal: pull the top-spending ads for a category across several countries.
What to fill in (in Structured filters):
- Search terms: type your category keywords, one per line (e.g.
weight loss,fitness app) - Countries: type the country codes you care about, one per line (e.g.
US,GB,CA) - Leave everything else at default.
The actor will run one search per keyword × country combination (so 2 keywords × 3 countries = 6 separate sorted lists, biggest spenders per query first).
📅 Monitor newly-launched ads in your niche (weekly schedule)
Goal: catch new creative launches in your industry, e.g. the last 7 days. Pair with Apify's built-in Schedules to run it every Monday.
What to fill in (in Structured filters):
- Search terms: your niche keywords (e.g.
crypto,trading bot) - Countries: the countries you care about (e.g.
US) - Sort by: change from the default to "Most recent (grouped by month)". This is important — the default "Total impressions" sort silently ignores the lower date bound.
- Start date from: pick the date one week ago in the date picker.
- Active status: leave at
active.
When the run finishes, schedule it weekly via the Schedules tab in Apify Console.
⚖️ Political, housing, employment, or credit ad transparency
Goal: get the regulated-category-only fields — currency, spend (range like "$600K - $700K"), reach_estimate, impressions_text / impressions_index, and targeted_or_reached_countries. These columns are empty for normal commercial ads — you must set adType to a regulated category to get them.
What to fill in (in Structured filters):
- Search terms: your topic (e.g.
election,vote,mortgage) - Countries: the jurisdiction (e.g.
US) - Ad category: change from "All ads" to "Issues, elections or politics" (or Housing / Employment / Financial products and services, depending on what you're tracking).
- Active status: set to "Active + inactive" to also get historical ads (politics ads are kept for 7 years).
📸 Search the Instagram Ad Library
Goal: use this as an Instagram Ad Library scraper — get only the ads running on Instagram, as a spreadsheet. The official Ad Library shows all Meta surfaces mixed together unless you dig into its platform filter; here it's one checkbox.
What to fill in (in Structured filters):
- Search terms: your niche or a competitor brand (e.g.
skincare) - Countries: your market (e.g.
US) - Publisher platforms: tick only
Instagram.
Every row's publisher_platform column confirms the surfaces, and image_urls / video_urls give you the Instagram creatives directly.
📱 Threads / WhatsApp / Audience Network analysis
Goal: see which brands are running ads on Meta's lesser-known surfaces (most competitor scrapers only return Facebook + Instagram).
What to fill in (in Structured filters):
- Search terms: your niche (e.g.
fintech) - Countries: your market (e.g.
US) - Publisher platforms: tick only the surfaces you want —
Threads, orWhatsApp, orAudience Network, or any combination. Leaving this empty returns ads from all surfaces.
🌍 Multi-country B2B lead research
Goal: find every active ad targeting a specific non-US country for a niche, then enrich the landing pages into a contact list.
What to fill in (in Structured filters):
- Search terms: your niche, in the local language too if relevant (e.g.
accounting software,boekhouder) - Countries: the target market (e.g.
BEfor Belgium) - Publisher platforms: tick
FacebookandInstagram(skip Threads/WhatsApp for B2B). - Active status: leave at
active.
When the run finishes, take the link_url column from the output spreadsheet and feed it into the Email Extractor & Lookup API to auto-find contact emails on each landing page.
🕵️ Spy on a single competitor's ads
Goal: see every ad one specific brand is currently running, biggest spenders first. No Structured filters needed.
Steps:
- Open the brand's Facebook page in your browser.
- Click the "Page transparency" section, then click "See all" under "Ads From This Page". This opens the Ad Library showing only that brand's ads.
- Copy the URL from your address bar.
- In the actor's input, paste it into Ad Library search URLs (replacing the prefilled crypto example).
- Click Start. That's it — defaults take care of the rest (active ads only, sorted by biggest spenders).
Input
Every input is optional, except that you must provide either startUrls or searchTerms (or both; they're additive). Fields marked Structured are under the collapsible Structured filters section in the form.
| Field | Section | Description |
|---|---|---|
startUrls | Top level | One or more facebook.com/ads/library URLs copied from your browser. Prefilled with a working crypto/US example. |
maxAdsPerSearch | Top level | Max unique ads to collect per search. Default: 100. Max: 1,000,000. Set to 0 for unlimited. |
searchTerms | Structured | Keywords to search for (each term × country combination becomes one search). |
countries | Structured | ISO country codes; defaults to ["US"]. Use ["ALL"] for global. |
adType | Structured | all (default), political_and_issue_ads, housing_ads, employment_ads, credit_ads. |
activeStatus | Structured | active (default), inactive, all. |
mediaType | Structured | all (default), image, video, meme, image_and_meme, none. |
searchType | Structured | keyword_unordered (default), keyword_exact_phrase. |
sortBy | Structured | total_impressions (default, high to low — best for competitor analysis) or relevancy_monthly_grouped (most recent, grouped by month — best with a date filter). |
publisherPlatforms | Structured | Any of facebook, instagram, messenger, whatsapp, audience_network, threads. Empty = all. |
startDateFrom / startDateTo | Structured | YYYY-MM-DD bounds on ad start date. |
Example input (API / programmatic — section grouping doesn't apply here, just key names):
Output
Each ad the Facebook Ad Library scraper returns is written to the dataset as a flat row. Download as a spreadsheet (CSV or Excel) for direct use in Google Sheets, Airtable, or Looker, or grab JSON / HTML / RSS / API for piping into BI tools, LLM agents, and automation platforms.
Results land in the run's dataset, which you can browse in the Output tab — one row per ad, with page name, ad copy, creatives, CTA, and platforms side by side:
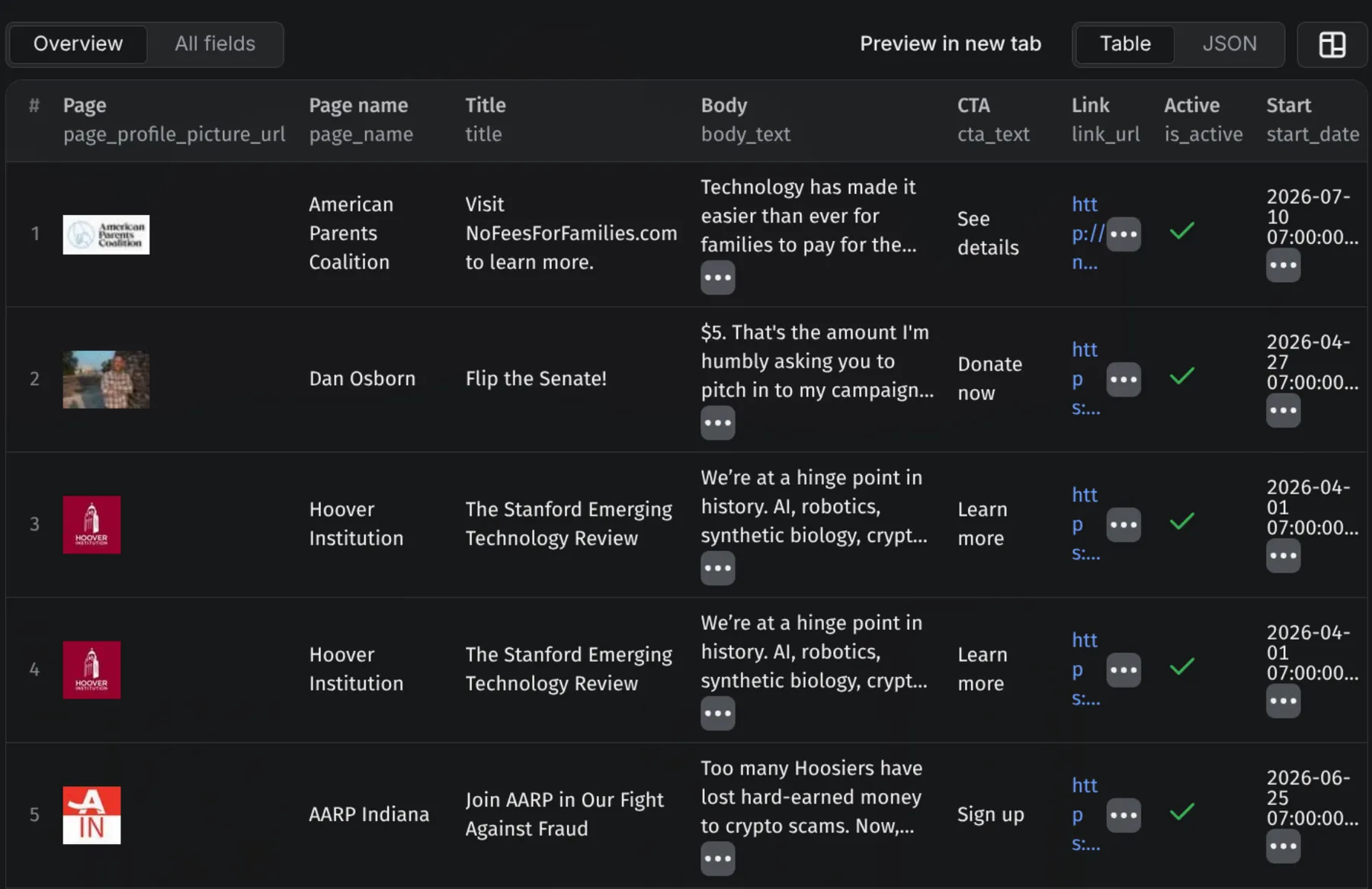
⚠️ Spend, reach, and impressions data is ONLY available for regulated ad categories — political/issue, housing, employment, and credit ads. For normal commercial ads these columns will always be empty. This is a Meta policy (they only legally have to disclose ad finances for regulated categories), not a scraper limitation. To get spend/reach data, set Ad category to one of the regulated options when running the actor.
Some ads return placeholder text like {{product.name}} or {{product.brand}} in the title and body. Those are DCO (Dynamic Creative Optimization) ads where Meta serves a different product per viewer from the same template — see the DCO FAQ for how to filter them out using the is_dynamic_creative column.
Download Facebook Ad Library images and videos in bulk
Every row includes direct CDN links to the ad's creatives — image_urls for images, video_urls for videos, and per-card creative inside cards for carousels. That makes this a Facebook Ad Library downloader too: no screenshots or browser extension needed. Export the dataset, take the URL columns, and pull the files with any download tool or a few lines of script.
Data fields
Every field the Facebook Ad Library scraper returns per ad — regulated-category-only fields are flagged ⚠️:
| Field | Description | |
|---|---|---|
| 🆔 | ad_archive_id | Facebook's stable ID for this ad |
| 🟢 | is_active | Whether the ad is currently running |
| 📄 | page_id, page_name, page_profile_uri | The Facebook page running the ad |
| 📊 | page_categories, page_like_count | Page metadata |
| 🎨 | display_format | IMAGE, VIDEO, DCO (dynamic creative), DPA (dynamic product), CAROUSEL, etc. |
| 🧬 | is_dynamic_creative | true when the ad copy contains template placeholders like {{product.name}} (see FAQ below). Use this to filter DCO/DPA template ads out of a spreadsheet in one click. |
| 📝 | title, body_text, caption | Ad copy. For DCO/DPA ads these may contain {{product.name}}, {{product.brand}}, {{product.description}} etc. placeholders rather than literal text |
| 🔘 | cta_text, cta_type | Call-to-action button label and type |
| 🔗 | link_url, link_description | Where the ad sends the user |
| 🖼️ | image_urls | Direct CDN URLs for image creatives |
| 🎬 | video_urls | Direct CDN URLs for video creatives |
| 🃏 | cards | For carousel/DCO ads: array of per-card creative (title, body, link, image) |
| 📱 | publisher_platform | Which Meta surfaces ran the ad: FACEBOOK, INSTAGRAM, MESSENGER, THREADS, WHATSAPP, AUDIENCE_NETWORK |
| 📅 | start_date, end_date | ISO 8601 UTC strings (e.g. "2026-05-23T05:36:37Z"). For active ads, end_date is null and start_date is derived from the actual total_active_time (Meta's anonymous endpoint doesn't expose real delivery windows for non-political ads). |
| 🏷️ | categories | Ad's policy categories, e.g. political, housing, credit, employment |
| 🚩 | contains_sensitive_content, contains_digital_created_media | Policy flags |
| 💰 | currency, spend, reach_estimate, impressions_text, impressions_index | ⚠️ POLITICAL ADS ONLY. Null for all normal commercial ads. spend is a string range like "$600K - $700K" or ">$1M". reach_estimate and impressions_text are string ranges. impressions_index is the only numeric version — use it to sort competitors by impressions in a spreadsheet. |
| 🌍 | targeted_or_reached_countries | ⚠️ POLITICAL ADS ONLY. Populated for cross-border political campaigns; empty for single-country regulated ads. |
| 🔍 | search_url | Which input URL this ad came from (useful when scraping multiple searches) |
Raw JSON examples (for developers)
The data fields table above is the canonical reference. The blocks below show the raw row shape you'll get from the API / JSON export, in case you're piping the output into a script.
Normal commercial ad — political/transparency fields are present but empty (Meta only publishes those for regulated ads).
Political / regulated ad — same schema, but the bottom block is populated because Ad category was set to political_and_issue_ads (or housing_ads / employment_ads / credit_ads). spend, reach_estimate, and impressions_text are string ranges; impressions_index is the only numeric column.
Tips
Get the most out of the Facebook Ad Library scraper:
- Parallelism. To go faster, add more search URLs (or more
searchTerms×countriescombinations) rather than trying to scale a single search. Workers within one search paginate the same sorted list and waste requests on duplicates beyond ~5 parallel workers. - Country filter matters.
country=ALLreturns Facebook's globally-sorted top ads (heavily US-dominated). Use specific country codes (e.g.country=BEfor Belgium-targeted ads) for non-US scrapes. - Sort order. Two modes are honored server-side for anonymous browsing: Most recent (monthly grouped) (default; surfaces newly-launched ads, respects both ends of the date filter) and Total impressions (biggest spenders first; often returns older very-high-spend creatives, and only respects the upper end of the date filter). FB's UI exposes "Creation time / Start date / End date" but those sort modes are not actually honored for anonymous requests; the actor maps them to "Most recent" so pasted URLs still work.
- Date range filter. Use
start_date[min]andstart_date[max]in pasted URLs (FB UI's "Start date" picker), or theStart date from/Start date toinputs. Works most reliably with the "Most recent" sort. - Ad type filter. Change
ad_typefromalltopolitical_and_issue_ads(or housing, credit, employment) to scope to regulated ad categories, which return additional fields like spend, reach, and targeting. - Anti-bot engineering. The actor uses residential sticky-session proxies, Chrome TLS impersonation (Meta blocks plain-Python TLS fingerprints), and an auto-solver for Facebook's
rd_challengeHTTP-403 gate. You don't need to configure any of this; it's hardcoded as the default because anything else gets rate-limited within seconds.
Other Apify Actors you might like
If you're using this for competitive intelligence or lead enrichment, these pair well:
- TikTok Comment Scraper: extract comments, usernames, timestamps, likes & reply counts from any TikTok username or video URL. Useful for social listening alongside Meta ad data.
- Email Extractor & Lookup API: bulk-extract emails from any list of domains (e.g. the
link_urlpages this actor finds). Auto-discovers contact pages and verifies domains. - CMS Detector: identify the CMS, frameworks, analytics, payment processors, and ecommerce add-ons on competitor sites you discover through their ads.
- Reverse Image Search API: find where an ad creative appears elsewhere on the web (Instagram, TikTok, eBay, Amazon, etc.) using Google Lens exact-match search.
- Google Maps Places API: 60+ business attributes per place (names, phones, websites, hours, reviews, coordinates). Good for B2B lead lists.
FAQ, disclaimers, and support
Is there a Facebook Ad Library API? Meta's official Ad Library API requires an access token, app review, and in most regions only returns political/issue ads. This actor works as a Facebook Ad Library API alternative (a no-token Meta Ad Library API) — call it via the Apify REST API (or the UI) for all ad categories across all 6 Meta platforms, and get structured JSON or a spreadsheet back. See "Option C: Meta Ad Library API" above.
Is it legal to scrape the Facebook Ad Library? The Facebook Ad Library is a public transparency tool that Meta provides intentionally to let anyone see active ads. This actor only retrieves data that is visible to any logged-out browser visiting the same URLs. Always respect Meta's Terms of Service and your local laws when using scraped data.
Why does some ad copy look like {{product.name}} instead of real text? Those ads are DCO (Dynamic Creative Optimization) or DPA (Dynamic Product Ads). The advertiser uploads a template like "Shop {{product.name}} from {{product.brand}} today" and links it to a Facebook Commerce Manager product catalog. At render time, Meta picks the right product per viewer and substitutes the placeholder, so each user sees a different rendered ad from the same template. Because there's no single "rendered" ad, the Ad Library (and therefore every scraper, including this one) returns the raw template with placeholders intact. Use the is_dynamic_creative column to filter these out of your spreadsheet in one click if you only want literal ad copy.
Feedback: open an issue on the actor's Issues tab if anything is broken or missing a field you need.