Reed Jobs Search Scraper
Pricing
$15.00/month + usage
Reed Jobs Search Scraper
Automate Reed.co.uk job data extraction with our advanced scraper. Extract job titles, salaries, locations & descriptions into CSV/JSON formats. Perfect for recruiters, HR professionals & businesses. 99% accuracy, bulk processing & seamless integration. Transform recruitment workflows today!
Pricing
$15.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
10
Total users
2
Monthly active users
5 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
What Can Reed.co.uk Jobs Search Scraper Do?
In today's competitive job market, accessing comprehensive employment data from leading platforms like Reed.co.uk has become crucial for recruitment agencies, HR professionals, job aggregators, and market researchers. Reed.co.uk stands as the UK's #1 job site with over 200,000 available positions, serving more than 11 million monthly users who make almost 100,000 applications daily. The platform features vacancies from over 30,000 recruiters annually, making it an invaluable source of UK employment market intelligence.
The challenge lies in efficiently extracting and organizing this vast amount of job data for analysis, competitive research, or automated job aggregation services. Manual data collection from such a large-scale platform would be time-consuming, error-prone, and practically impossible to maintain at scale. This is where a specialized Reed.co.uk jobs scraper becomes an essential tool for businesses and professionals who need reliable access to UK job market data.
Comprehensive Reed.co.uk Jobs Search Scraper Overview
Our Reed.co.uk Jobs Search Scraper is a sophisticated data extraction tool designed specifically to navigate and extract job listings from Reed's extensive database. The scraper handles the complexities of modern web scraping, including dynamic content loading, anti-bot measures, and data structure variations, ensuring consistent and reliable data extraction.
The tool excels in its ability to process multiple search query URLs simultaneously, making it ideal for large-scale data collection projects. Whether you're tracking specific job categories, monitoring salary trends across different regions, or building comprehensive job databases, this scraper provides the robust functionality needed for professional applications.
Key advantages include automated pagination handling, comprehensive data field extraction, proxy support for undetected scraping, and configurable retry mechanisms. The scraper is particularly valuable for recruitment consultancies, HR analytics firms, job board aggregators, and market research organizations that require systematic access to UK employment data.
Input Configuration and Requirements
Example url 1: https://www.reed.co.uk/jobs/jobs-in-london?sortBy=displayDate&pageno=2
Example url 2: https://www.reed.co.uk/jobs/jobs-in-east-london
Example url 3: https://www.reed.co.uk/jobs/jobs-in-harrow
Example Screenshot of jobs information page:
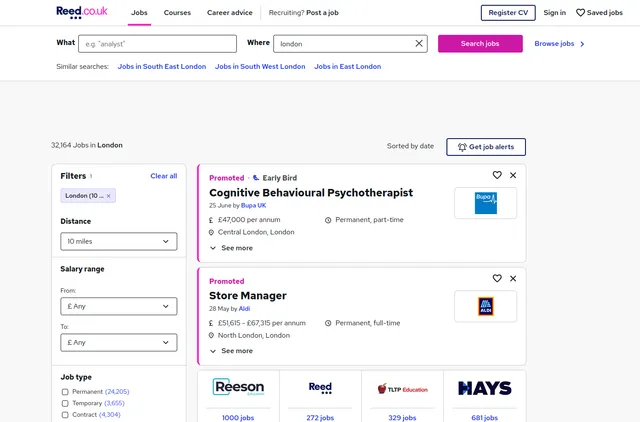
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of job listing page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find jobs (e.g., "software engineer", "accountant", "nurse", "manager").
The location parameter: Enter the location to search for jobs (e.g., "London", "Manchester", "Birmingham", "Leeds").
The job_type parameter: Filter jobs by employment type:
"permanent"- Permanent positions"temporary"- Temporary positions"contract"- Contract positions"full-time"- Full-time positions"part-time"- Part-time positions
The distance parameter: Filter jobs by distance from the specified location:
"0"- 0 miles (exact location)"1"- 1 mile"3"- 3 miles"5"- 5 miles"10"- 10 miles"15"- 15 miles"20"- 20 miles"30"- 30 miles"50"- 50 miles
The posted_date parameter: Filter jobs by posting date:
""- Any time"today"- Last 24 hours"lastthreedays"- Last 3 days"lastweek"- Last week"lasttwoweeks"- Last 2 weeks
The page parameter: Starting page number for scraping, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of job listings extracted from each listing page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., UK/GB for reed.co.uk).
Output:
You get the output from the Reed.co.uk Jobs Search Query Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
Detailed Output Data Structure
Core Job Information Fields
The scraper extracts over 40 distinct data fields from each job listing, providing comprehensive information for analysis and application. Understanding each field's purpose is crucial for effective data utilization.
Primary Identifiers: Job ID serves as the unique identifier for each listing, while Profile ID and OU ID (Organizational Unit ID) help track job relationships and employer hierarchies. These fields are essential for database management and avoiding duplicate entries.
Job Details: Job Title, Job Type, and Job Description provide the core content information. Job Type typically indicates whether the position is permanent, temporary, contract, or part-time. The description contains the full job posting content, including requirements and responsibilities.
Temporal Data: Multiple date fields track the job lifecycle - Date Created shows when the job was first posted, Date Updated indicates the last modification, Display Date shows when it appeared in search results, and Expiry Date indicates when the listing will be removed. This temporal information is valuable for analyzing job posting patterns and market trends.
Location Intelligence: Display Location Name and County Location provide geographical context, while Remote Working Option indicates flexibility in work arrangements. This data is crucial for location-based analysis and understanding regional employment patterns.
Compensation Details: Salary Currency ID, Salary Description, Salary From, Salary To, and Salary Type provide comprehensive compensation information. These fields enable salary range analysis, market rate research, and compensation benchmarking across different roles and locations.
Advanced Classification and Features
Job Categorization: Taxonomy Level 1 and Taxonomy Level 2 provide standardized job classification, enabling systematic analysis across job categories and industries. This hierarchical classification system helps in building job recommendation engines and market analysis tools.
Priority and Visibility Indicators: Boolean fields like Is Priority, Is Promoted, Is Top Job, Is Featured, and Is Early Bird indicate the job's visibility status on the platform. These fields help understand employer marketing strategies and job posting economics.
Application and Engagement Metrics: Is Easy Apply, Is ATS Direct Apply, Has Applied, Is In Saved Jobs List provide insights into job accessibility and user engagement levels. This information is valuable for understanding application conversion patterns.
Employer Information: OU Name, OU Type, OU Tier ID, Profile Name, Profile URL, and Logo Image provide comprehensive employer details. This data enables employer analysis, company research, and professional networking applications.
Implementation Guide and Best Practices
Configuration Setup
Step 1: Choose Your Scraping Approach
Option A - URL-Based Configuration:
Begin by configuring your input parameters based on your specific data collection requirements. Navigate to Reed.co.uk and use the website's search and filtering features to find relevant job listings. Construct your URLs carefully using Reed.co.uk's search parameters. Include sorting options like sortBy=displayDate for the most recent listings, or sortBy=salary for compensation-focused research. Always test your URLs manually before adding them to the scraper configuration. Copy the complete URLs with all filter parameters.
Option B - Filter-Based Configuration: Define your search criteria using the built-in filters:
- Set
keywordfor specific job titles or roles (e.g., "software engineer", "nurse", "accountant") - Enter
locationto target specific areas (e.g., "London", "Manchester", "Birmingham") - Select
job_typeto filter by employment type (permanent, temporary, contract, full-time, part-time) - Set
distanceto define search radius from location (0-50 miles) - Choose
posted_dateto filter by job posting recency (today, last 3 days, last week, last 2 weeks) - Set
pageto start from a specific results page
Step 2: Set Data Limits
For comprehensive market research, set max_items_per_url to a higher value (50-100 items) but monitor your proxy usage and request frequency. For focused searches, 10-20 items typically provide sufficient data while maintaining efficient resource usage.
Step 3: Configure Proxy and Retry Settings
Set max_retries_per_url (recommended: 2-3) and configure UK (GB) residential proxies for optimal performance with Reed.co.uk. Enable ignore_url_failures for robust scraping.
Best Practices:
Method Selection:
- Use URL-based scraping for complex searches with multiple filters or specific sorting requirements
- Use filter-based scraping for simpler keyword and location searches with standard filtering options
- Combine both approaches: use filters for broad job discovery, then URLs for targeted extraction
Filter Optimization:
Location Strategy:
- Use specific city names in
location(e.g., "London", "Edinburgh", "Cardiff") - Combine with
distanceto broaden or narrow the search area:- 0-5 miles for hyperlocal searches
- 10-15 miles for city-wide searches
- 20-30 miles for regional searches
- 50 miles for broader coverage
Job Type Strategy:
- Use
job_type: "permanent"for full-time career positions - Use
job_type: "contract"for project-based work - Use
job_type: "temporary"for short-term assignments - Use
job_type: "full-time"or"part-time"for schedule-specific searches
Recency Filtering:
- Use
posted_date: "today"for real-time job tracking - Use
posted_date: "lastthreedays"for catching recent opportunities - Use
posted_date: "lastweek"for weekly job market analysis - Use
posted_date: "lasttwoweeks"for broader time coverage - Leave empty for comprehensive historical data
Advanced Filter Combinations:
- Local permanent jobs:
keyword: "accountant", location: "Manchester", job_type: "permanent", distance: "10", posted_date: "lastweek" - Recent contract work:
keyword: "IT consultant", location: "London", job_type: "contract", distance: "15", posted_date: "lastthreedays" - Part-time opportunities:
keyword: "customer service", location: "Birmingham", job_type: "part-time", distance: "5", posted_date: "today" - Regional full-time:
keyword: "engineer", location: "Leeds", job_type: "full-time", distance: "30", posted_date: "lasttwoweeks"
Distance Optimization:
- Start with smaller distance values (5-10 miles) for specific locations
- Increase distance (20-50 miles) if results are limited
- Use distance: "0" for exact location matches only
- Consider commute patterns when setting distance for major cities
Use Cases:
- Daily Job Monitoring:
posted_date: "today"with specific keywords and locations - Weekly Market Analysis:
posted_date: "lastweek"for comprehensive tracking - Location Comparison: Run same keyword across different
locationanddistancecombinations - Contract vs Permanent Analysis: Compare results using different
job_typefilters - Commute-Based Search: Use
distanceto find jobs within commutable range
Handling Common Challenges
Network reliability can impact scraping performance, especially during peak hours when Reed.co.uk experiences high traffic. The retry mechanism helps handle temporary failures, but consider spacing your scraping sessions to avoid concentrated load on the target servers.
Data consistency may vary between different job listings, as employers have flexibility in how they structure their postings. Some optional fields like Remote Working Option or specific salary details may not be populated for all jobs. Implement proper data validation in your processing pipeline to handle missing values appropriately.
Rate limiting is crucial for maintaining long-term scraping access. Reed.co.uk, like most major job boards, monitors for automated access patterns. Use the provided proxy rotation features and avoid scraping the same URLs repeatedly within short time windows.
Business Applications and Strategic Value
Time Efficiency and Automation
Manual job data collection from Reed.co.uk would require hundreds of hours for comprehensive market analysis. The scraper reduces this to automated background processing, freeing human resources for analysis and decision-making. Organizations can schedule regular data collection to maintain current market intelligence without ongoing manual effort.
Market Intelligence Applications
Recruitment agencies can monitor competitor job postings, analyze salary trends across different sectors, and identify emerging skill requirements in specific markets. HR departments can benchmark their job postings against market standards and optimize their recruitment strategies based on successful posting patterns.
Business Intelligence Integration
The structured output format enables seamless integration with business intelligence tools, CRM systems, and analytics platforms. Organizations can build automated reporting systems that track job market trends, monitor specific companies' hiring patterns, and identify business opportunities in the recruitment sector.
Conclusion and Implementation
The Reed.co.uk Jobs Search Scraper provides professional-grade access to the UK's most comprehensive job database, enabling systematic data collection for business intelligence, market research, and competitive analysis. With its robust configuration options, comprehensive data extraction capabilities, and built-in reliability features, the tool serves as an essential resource for organizations requiring systematic access to UK employment market data.
Ready to transform your approach to job market intelligence? Implement this scraper to gain competitive advantages through data-driven insights into the UK employment landscape.
Related Actors
- Reed.co.uk Jobs Details Scraper: Your comprehensive tool for extracting valuable jobs information from Reed.co.uk extensive directory platform.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Reed.co.uk Jobs Search Query Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.