Google Search Results Scraper
Pricing
from $1.80 / 1,000 scraped search result pages
Google Search Results Scraper
Scrape Google Search Engine Results Pages (SERPs). Select the country or language and extract organic and paid results, AI Mode, AI overviews, ads, queries, People Also Ask, prices, reviews, like a Google SERP API. Export data, run the scraper via API, schedule runs, or integrate with other tools.
Pricing
from $1.80 / 1,000 scraped search result pages
Rating
4.8
(134)
Developer
Apify
Maintained by ApifyActor stats
1.3K
Bookmarked
126K
Total users
10K
Monthly active users
3.8 days
Issues response
2 days ago
Last modified
Categories
Share
What is Google Search Results Scraper?
Google Search Results Scraper crawls Google Search Results Pages (SERPs) and extracts data from those web pages. With this SERP scraper API, you can:
- Extract almost any Google data from each Google page
- Data includes organic and paid results, as well as suggested results
- Scrape Google AI Mode, Perplexity AI search, ChatGPT search, Copilot search, and Gemini search to improve AEO and GEO results
- Compare AI answers across platforms (Google, Perplexity, ChatGPT, Copilot, Gemini) to spot narrative differences and search engine biases
- Also extract review ratings, review counts, and product ads
- Find related queries and People Also Ask answers
- Find prices for products or services
- Use business lead enrichment to further enrich your data with contact details (full name, work email address, phone number, job title, LinkedIn profile)
- Export data in multiple formats: JSON, CSV, Excel, or HTML
- Export via SDKs (Python & Node.js), use API Endpoints, webhooks, or integrate with workflows
What data can I extract with Google Search Results Scraper?
| 🌱 Organic results | 🛍 Paid results |
| 🤖 AI Mode + AI Overviews | 📢 Product ads |
| ❓ Related queries | 🙋♀️ People Also Ask |
| 🎯 Business leads enrichment | ⭐️ Review rating and review count |
| 🪴 Suggested results | 🔍 Additional custom attributes |
🤖 Add-on: Google AI Mode
Scrapes results from Google AI Mode - Google's dedicated AI-powered search interface on google.com, distinct from the standard AI Overviews snippets that appear in regular search results. AI Mode provides deeper, conversational answers with cited sources. Essential for Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO) - track how your brand or content appears when users switch to Google's AI search experience.
🧠 Add-on: Perplexity AI search
Enables you to fetch AI-generated answers using the Perplexity Sonar model. This feature is designed for cross-platform analysis, allowing you to directly compare other AI search model results against Perplexity's perspective to identify narrative differences and coverage gaps.
💬 Add-on: ChatGPT search
Enables you to fetch AI-generated answers using OpenAI's search model. This feature is designed for cross-platform analysis, allowing you to directly compare other AI search model results against ChatGPT's perspective to identify narrative differences, coverage gaps, and search engine biases.
The output includes query fan-out under queryFanOut, showing additional search queries the model generated to answer your question.
⏩ Add-on: Copilot search
Enables you to fetch AI-generated answers using Microsoft Copilot. This feature is designed for cross-platform analysis, allowing you to directly compare other AI search model results against Copilot's perspective to identify narrative differences, coverage gaps, and search engine biases.
You can choose from four modes to control how Copilot structures its response: chat (conversational, quick answers), reasoning (deep analytical, multi-step logic), smart (balanced speed and reasoning), or study (detailed explanations for educational and research prompts).
⏩ Add-on: Gemini search
Fetches AI-generated answers from Google Gemini (gemini.google.com) - Google's standalone AI assistant, separate from Google Search. Use this for cross-platform comparison to identify narrative differences and coverage gaps across AI platforms.
📢 Add-on: Paid results (ads) extraction
Determines whether ads are present on the page and, if so, shows what they are. This is useful for anybody planning their own campaigns, or who want to know what competitors are showing.
👥 Add-on: Business leads enrichment
This setting allows you to add contact information for companies and the employees working there, including full name, work email address, phone number, job title, and LinkedIn profile.
Under the 'Organic results' tab, you can now find multiple business leads associated with each individual search result.
⚠️ Warning!
Leads enrichment is applied to all domains discovered in your search, including news articles, directories, and comparison sites, not just the primary company websites.
Large company chains are filtered out so as not to clutter up your results. This list shows you which sites are never included.
✅ Add-on: Email verification
When verifyLeadsEnrichmentEmails is enabled, each lead's email address is verified and an emailVerification object is added to the lead output. Requires business leads enrichment to be active.
Charged (decisive results):
ok– Valid, deliverable email addressinvalid– Invalid or non-existent email addressdisposable– Disposable or temporary email address
Not charged:
catch_all– The domain accepts all addresses; individual deliverability cannot be confirmedunknown– Verification result could not be determinederror– Verification encountered a technical error
How can I use data scraped from Google Search?
Google SERP API has a lot to offer in terms of how extracted Google data can be applied:
- Use it for SEO and keep an eye on how your website performs on Google for certain queries over time
- Monitor how frequently a search term has been used on Google, and how it compares with total search volume
- Analyze display ads for a given set of keywords
- Monitor your competition in both organic and paid results
- Build a URL list for certain keywords for scraping web pages containing specific phrases
- Analyze the Google algorithm and identify its main trends
- Better lead generation with the business leads enrichment add-on
- Monitor AI overview summaries to see how a site performs
- Improved AEO, GEO, and brand visibility tracking with AI search add-ons (Google AI Mode, Perplexity, ChatGPT, Copilot, Gemini)
How to use Google Search Results Scraper
Google Search Results Scraper is designed with users in mind, even those who have never extracted data from the web before. Using it takes just a few steps.
- Create a free Apify account using your email
- Open Google Search Results Scraper
- Add one or more [relevant data]
- Click the “Start” button and wait for the data to be extracted
- Download your data in JSON, XML, CSV, Excel, or HTML
Check out Apify's video tutorial for more details: https://www.youtube.com/watch?v=wjLskDlPfvo
How to adapt your queries
To get a larger number of results, simply increase the number of pages you want to scrape. For example, to get approximately 100 results, you need to set maxPagesPerQuery to 10. The Actor will then navigate through 10 pages for your query, collecting ~10 results from each.
Please note that your results will be determined by the country you select, as well as your browsing history, exact IP address location, and browser fingerprint.
How much will scraping Google Search cost you?
This scraper uses a pay-per-event (PPE) pricing model. You are not charged for the Apify platform usage, but only a fixed price for specific events, check the pricing tab for details.
On the Free plan, you get $5 worth of credit, which lets you scrape over a 1,000 Google Search results, without use of add-ons. If you upgrade to any of Apify's paid plans, you get a further discount, which means you could scrape thousands of results in just seconds.
⬇️ Input
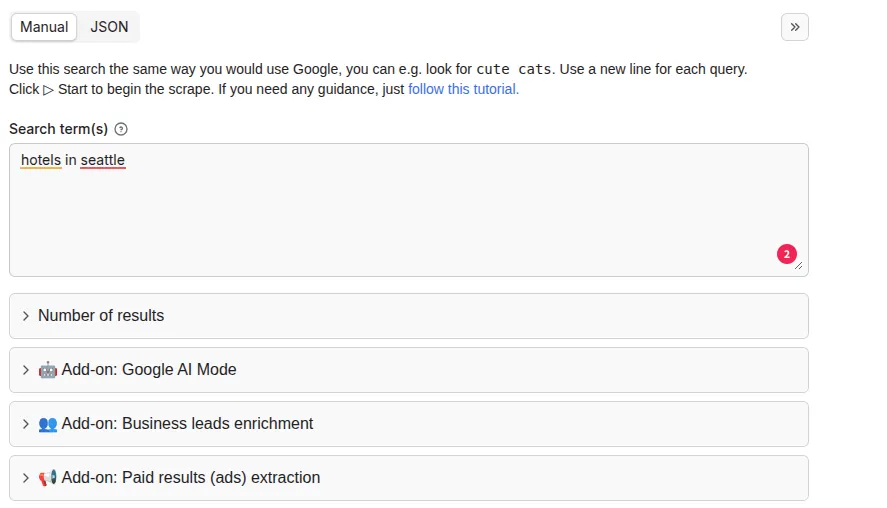
The scraper lets you control what kind of Google Search data you can extract. You can specify the following settings:
- Query phrases or raw Google search URLs
- Country/search domain
- Language of search
- Exact geolocation
- Number of results per page
- Mobile or desktop version results
For a complete description of all settings, see the Input tab.
How to scrape Google Search results by URL or keyword
There are two ways you can scrape Google search pages: either by URL or by search term.
- Scraping by URL will get you data from Google Search results page. You'll get Google data from a copy-pasted Google URL with any Google country domain (e.g.
google.co.uk). You can add as many URLs as you want. - Scraping by search term will also get you data from Google Search results page. You can also add as many search terms as you want.
Example input for scraping Google Search search term
To get Google search data by search term, enter the search term and a number of Google pages to scrape. Using search terms, you can:
- Scrape by multiple keywords in parallel by adding more search terms and separating them by a new line
- Say how many results you want to see per each Google page (10-100)
- Determine the country of search (domain), language, and UULE location parameter
Here's its equivalent in JSON:
Scrape Google Search results by URL
To input URLs instead, simply replace queries with full URLs:
⬆️ Output
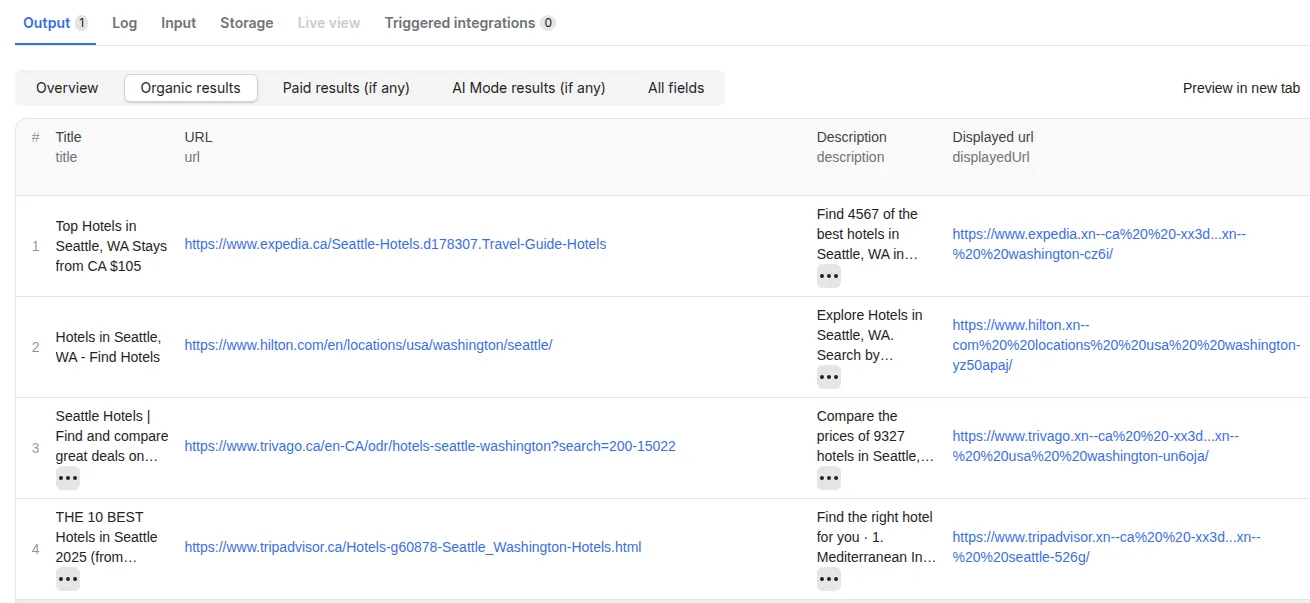
The scraper stores its result in the default dataset associated with the scraper run, from which you can export it to various formats, such as JSON, XML, CSV, or Excel.
For each Google Search results page, the dataset will contain a single record, which looks as follows. Note that the output preview will be organized in table and tabs for viewing convenience:
Here’s the equivalent of the same scraped data but in JSON. Bear in mind that some fields have example values:
You can download the results directly from the platform using a button or from the Get dataset items API endpoint:
where [DATASET_ID] is the ID of the dataset and [FORMAT]can be csv, html, xlsx, xml, rss or json.
Frequently asked questions
How to get one search result per row
Simply choose the Export view for Organic results and/or Paid results, it automatically spreads each result into a separate row. For API access, you can add &view=paid_results or &view=organic_results to the URL and with the API client, you can do the same using the view field.
An organic result is represented using the following format:
A paid result has an adPosition field instead of position and "type": "paid". Paid result position is calculated separately from the organic results.
When using a tabular format such as csv or xls, you'll get a table where each row contains just one organic result. For more details about exporting and formatting the dataset records, please see the documentation for the Get dataset items API endpoint.
Can I use integrations with Google Search Results Scraper?
You can integrate Google Search Results Scraper with almost any cloud service or web app. Apify offers integrations with Make, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and plenty more.
Alternatively, you could use webhooks to carry out an action whenever an event occurs, such as getting a notification whenever Google Search Results Scraper successfully finishes a run.
Can I use Google Search Results Scraper with the Apify API?
The Apify API gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify Actors. The API also lets you access any datasets, monitor Actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Click on the API tab for code examples, or check out the Apify API reference docs for all the details.
Can I use Google Search Results Scraper through an MCP Server?
With Apify API, you can use almost any Actor in conjunction with an MCP server. You can connect to the MCP server using clients like ClaudeDesktop and LibreChat, or even build your own. Read all about how you can set up Apify Actors with MCP.
For Google Search Results Scraper, go to the MCP tab and then go through the following steps:
- Start a Server-Sent Events (SSE) session to receive a
sessionId - Send API messages using that
sessionIdto trigger the scraper - The message starts the Google Search Results Scraper with the provided input
- The response should be:
Accepted
Is it legal to scrape Google Search data?
Web scraping is legal if you are extracting publicly available data, which is most data on Google Search. However, you should respect boundaries such as personal data and intellectual property regulations. You should only scrape personal data if you have a legitimate reason to do so, and you should also factor in Google's Terms of Use.
If you're unsure whether your reason is legitimate, consult your lawyers. You can also read Apify's blog post on the legality of web scraping.
Your feedback
If you are not sure that the results are complete and of good quality, each run stores the full HTML page to the default Key-Value Store. You can view the KVS by clicking on it and comparing the results.
We’re always working on improving the performance of our Actors and monitoring the quality but we are happy for any reports. So if you’ve got any technical feedback for this Google SERP API or simply found a bug, please create an issue on the Actor’s Issues tab.